1. Indice
- 1. Indice
- 2. Introduzione
- 3. Struttura di un Sistema Operativo
- 4. Definizioni di OS
- 5. Tipi di Sistemi Operativi
- 6. Architettura di un sistema di Elaborazione
- 7. Struttura dei Sistemi Operativi
2. Introduzione
Iniziamo sottolineando la differenza tra meccanismo e politica:
- Un meccanismo riassume una serie di passaggi e operazioni per compiere un determinato compito.
- Una politica invece si preoccupa di effettuare la scelta di come compiere un determinato scopo.
Una volta adoperata la scelta si utilizza un meccanismo per compiere lo scopo.
Detto ciò introduciamo cos’è un Sistema Operativo.
È un programma che in un computer agisce da intermediario tra l’utente e l’hardware
Ha come obiettivi quelli di:
- Eseguire programmi utente e semplificare la risoluzione dei problemi degli utenti
- Rendere il sistema di elaborazione semplice da utilizzare
- Utilizzare l’hardware del computer in modo efficiente (vedremo dieverse metriche per valutare questo aspetto)
I programmi utente creeranno dei processi a partire dai dati dell’utente.
Secondo il modello di Von Neumann i programmi, insieme ai dati, devono essere caricati nella memoria principale RAM. Solo in questo modo la CPU può raccogliere le istruzioni che poi eseguirà.
Oltre alla CPU e alla RAM, componenti fondamentali per l’esecuzione di qualsiasi programma, possono anche essere necessarie delle periferiche di I/O per poter far comunicare i programmi con l’utente. Possono inoltre essere anche necessare delle risorse logiche, alle quali fanno capo tutte quelle variabili e/o strutture dati condivise necessarie per il funzionamento del sistema. Anche i file rientrano nelle risorse logiche.
Alla base di ogni sistema operativo saranno quindi fondamentali due funzioni:
- Meccanismi per la gestione del processore
- Meccanismi per la gestione della memoria
Per le risorse logiche abbiamo altri moduli dedicati, che non costituiscono una componente fondamentale di un sistema operativo.
Il Sistema Operativo è fondamentale poiché si occupa di arbitrare l’allocazione delle risorse dei vari processi e della loro schedulazione, oltre a definire le modalità e i requisiti di accesso tra le varie componenti hardware di un dato sistema, che possono variare da calcolatore a calcolatore.
3. Struttura di un Sistema Operativo
Concettualmente, un sistema operativo può essere rappresentato con questo schema a strati:
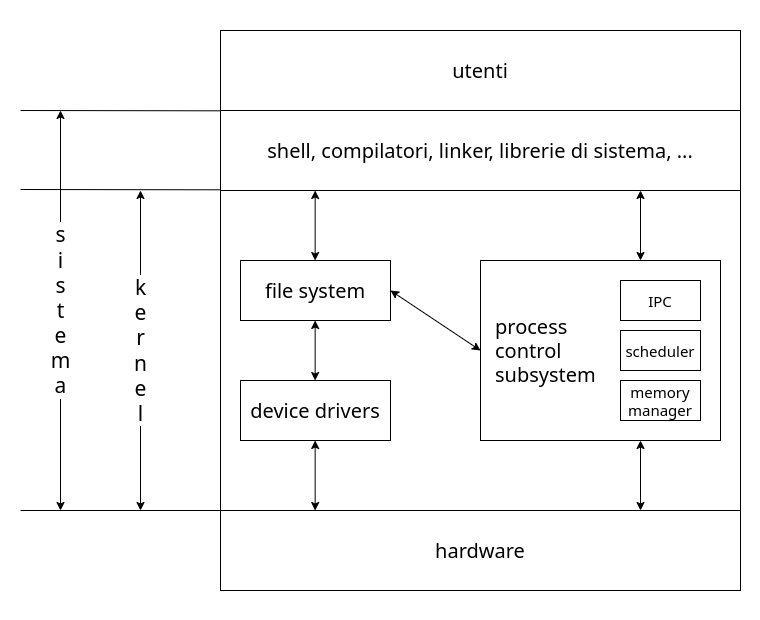
Il livello hardware è quello che corrisponde ai livelli fisici del sistema che comprende oltre a CPU e RAM anche le unità periferiche e la memoria persistente.
Quest’ultima, per quanto non sia strettamente necessaria (si vedano infatti i primi calcolatori con memoria persistente esterna tramite floppy-disk), è oggi considerata tale.
Il livello sistema operativo comprende un insieme di componenti software che hanno il compito di gestire le risorse fisiche della macchina offrendo ai programmi applicativi un’interfaccia standard più semplice da utilizzare. Questa è composta da una serie di funzioni che possono essere invocate dai programmi applicativi per intervenire sulle componenti hardware del sistema in maniera controllata ed efficiente. Sempre a questo livello si trovano i driver per le periferiche.
Questo livello permette di utilizzare le funzioni del livello hardware senza conoscere la loro implementazione. Viceversa possiamo cambiare l’implementazione di queste funzioni senza necessità di dover modificare l’interfaccia dei programmi applicativi, che continuerà a funzionare.
Il livello programmi applicativi corrisponde invece all’insieme delle applicazioni utilizzate direttamente dagli utenti del sistema. I programmi utente infatti non interagiscono mai direttamente con l’hardware, ma sempre tramite l’interfaccia dell’OS.
Grazie ad’esso permettiamo lo sviluppo e la portabilità dei programmi applicativi. In questo modo chi programma non ha la necessità di conoscere nel dettaglio tutte le componenti di un determinato sistema, ma gli è sufficente conoscere l’interfaccia dell’OS.
Il Sistema Operativo realizza politiche di gestione delle risorse del sistema di elaborazione, come la gestione delle pagine di memoria o gli scheduling, che permettono di gestire le assegnazioni dei processi alla CPU. Inoltre, si occupa di fornire meccanismi di protezione, garantire la scurezza del sistema e la tolleranza ai guasti. Non vedremo gli ultimi due scopi, ma analizzeremo invece l’implementazione dei meccanismi di protezione.
In fondo un OS funziona in maniera simile ad una API (Application Programming Interface), ovvero è come se generasse una macchina astratta più semplice, efficiente e sicura.
4. Definizioni di OS
Se volessimo vedere l’OS da altri punti di vista possiamo dire che si tratta di un allocatore di risorse. Deve quindi avere il diritto di poter accedere a tutte le risorse, ed essere in grado di decidere tra richieste conflittutali per garantire un uso efficiente ed equo delle risorse.
È vero anche che l’OS è un programma di controllo, controlla infatti l’esecuzione dei programmi per prevenire errori e un uso improprio del Sistema di Elaborazione.
È importante sottolineare che:
L’unico programma in esecuzione in ogni momento sul computer è il kernel.
Tutto il resto non sono altro che programmi applicativi o di sistema, forniti proprio dall’OS.
5. Tipi di Sistemi Operativi
5.1. Sistemi Batch monoprogrammati
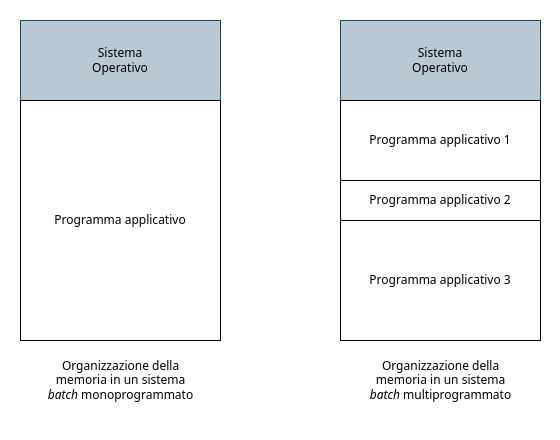
Tipici degli anni ‘60, si chiamano così perché i vari programmi venivano consegnati agli operatori su schede forate, chiamate batch, che venivano inserite una ad una all’interno del calcolatore. In questi sistemi erano presenti solamente il monitor e il BIOS.
Nel calcolatore in ogni momento era presente un solo programma, che veniva eseguito dall’inizio alla fine senza interruzioni.
Anche questo calcolatore, estremamente semplice, necessitava di alcune routine per poter funzionare correttamente, come:
- routine di lettura schede: permetteva di leggere i comandi nei batch
- routine di scrittura: permetteva di fornire l’output all’operatore tramite stampa su rullo
Quando vennero introdotte le memorie di massa diventò necessario anche l’implementazione di routine di lettura/scrittura dei job (programmi) da essa.
Nasce quindi l’esigenza di creare un JCL (Job Control Language).
Il JLC non erano altro che delle $direttive che venivano interpretate da un monitor. Queste $direttive corrispondevano a delle routine che potevano essere chiamate all’occorenza.
Possiamo identificare in loro gli antenati della moderna shell.
5.2. Sistemi di Spooling
Questi sistemi permettevano la lettura dei programmi da dischi (floppy-disk) in modo tale che durante le loro esecuzioni la CPU leggesse dati e producesse risultati operando solo con il disco.
Le scritture verso la stampande avvenivano operando in DMA.
Spooling è un acronimo di Simultaneous Peripheral Operation On-LINe, che sta proprio a indicare che tutto avviene su flussi di comunicazione indipendenti e concorrenti.
5.3. Sistemi Multiprogrammati
Venne osservato che l’efficienza dei mainframe, che avevano costi nell’ordine dei milioni di euro, era tendenzialmente bassa. Questo accadeva perché le risorse, a causa di come venivano gestiti i programmi, venivano utilizzate in media meno della metà del loro potenziale. Inoltre vi era un altro problema, legato al numero costantemente crescente di programmatori che nel tempo si erano formati, che rendeva quindi il modello di first-come-first-serve ingestibile.
Per riuscire a ottenere un drastico miglioramento nell’efficienza di uso delle risorse della macchina fu realizzata la tecnica della multiprogrammazione. Questa tecnica permetteva a più programmi di venire caricati in memoria in parallelo, gestendoli in modo concorrente.
Tuttavia, questa nuova gestione dei programmi creò la necessità dell’implementazione di algoritmi di scheduling, che permettevano alla CPU di eseguirli uno alla volta e di sostituirli quando venivano messi in attesa, così da ridurre il più possibile i “tempi morti”.
I primi algoritmi di scheduling deviarono dal principio di first-come-first-serve, e introdussero il concetto di interruzione. Non si lasciava più l’accesso alla CPU ad un programma per tutto il suo time-to-live, ma si riservava la possibilità sostituirlo anche durante la sua eseguzione qual’ora questo fosse andato in attesa, così da permettere ad un altro programma di sfruttare quei cicli che sarebbero altrimenti stati sprecati.
Si notò subito che la memoria diventava il bottleneck di questo nuovo sistema, e si iniziò a introdurre una gestione dinamica della stessa.
Venne quindi introdotta la preemption anche nella gestione spaziale della memoria, attraverso swap da e verso il disco. Si rese quindi necessaria la virtualizzazione della memoria, così da poter riuscire a gestire al meglio i vari accessi in memoria dei programmi che potevano essere swappati e reinseriti in punti diversi di RAM, generando quindi errori e corruzione dei dati.
Nella multiprogrammazione andiamo quindi ad indentificare due momenti durante l’esecuzione di un processo:
- CPU-burst: intervalli di tempo nel quale un processo deve eseguire istruzioni e necessita di occupare la CPU
- IO-burst: intervalli di tempo nel quale un processo deve eseguire un’operazione di IO e non deve utilizzare la CPU
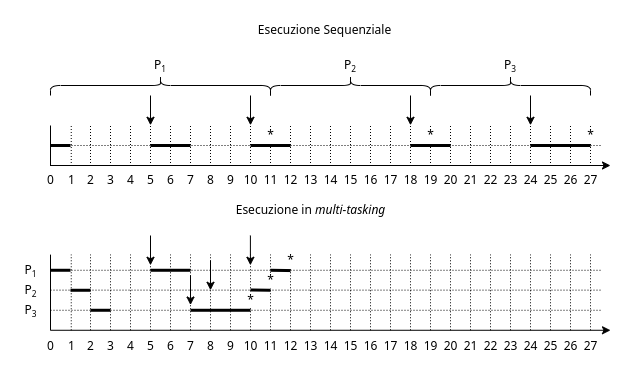
Come possiamo vedere dall’esempio a destra, nell’esecuzione sequenziale i processi vengono eseguiti in ordine di arrivo, e vengono eseguiti dall’inizio alla fine. In questo modo notiamo che sono presenti diverse unità di tempo dove la CPU è in attesa di qualcosa. Possiamo calcolare l’efficienza di questo esempio, che è di $\frac{10}{27} \approx 37\%$
Nell’esecuzione multi-tasking invece, quando il primo processo va in IO-burst, e si mette in attesa, la CPU inizia a lavorare prima sul secondo processo, e poi sul terzo quando anche il secondo va in attesa. Durante i momenti nei quali i vari programmi sono sospesi, questi vengono poi recuperati nell’ordine in cui ricevono i dati che attendono, e verranno messi in esecuzione quando colui che occupa l’esecuzione terminerà e/o andrà nuovamente in attesa. Possiamo quindi calcolare anche in questo caso l’efficienza, che stavolta è di $\frac{10}{12} \approx 83\%$
5.4. Sistemi time-sharing
Sono sistemi che hanno come primo obiettivo quello di dividere il tempo d’uso della CPU tra i vari processi.
Mentre nei sistemi multiprogrammati qundo la CPU viene assegnata ad un processo, gli altri non la possono utilizzare finché questo non termina la sua cpu-burst, nel paradigma time-sharing la CPU è assegnata ad ogni processo per un quanto di tempo uguale e prederminato per tutti.
La politica quindi diventa la seguente:
- Se durante il quanto di tempo hai terminato la cpu-burst vai in attesa fino al prossimo cpu-burst
- Se durante il quanto di tempo non hai terminato, il tuo stato intermedio viene salvato e verrà ripristinato quando tornerà il tuo turno. Questa revoca viene chiamata preemption.
Il salvataggio e ripristino dello stato intermedio corrispondono a tutti gli effetti al cambio di contesto che avevamo visto nel corso di Calcolatori Elettronici.
Un esempio noto di time-sharing è il Round-Robin.
5.5. Overhead
La multiprogrammazione non è però gratuita. Il costo di migliorare i tempi si chiama overhead, e consiste nel tempo aggiuntivo usato dall’OS per eseguire il codice aggiuntivo introdotto dalle operazioni intermedie, come l’algoritmo di schedulazione, l’algoritmo di cambio di contesto, …
Questo tempo è a tutti gli effetti sottratto dall’esecuzione dei programmi applicativi. Per poter vedere un guadagno nei tempi di esecuzione è quindi necessario che l’overhead sia contenuto. indicativamente attorno all’ $1\%/2\%$.
Se avessimo infatti overhead del $70\%$ del tempo totale, potrebbe non essere conveniente avere un sistema multiprogrammato. Se fosse ancora più alto il sistema potrebbe persino andare in crash, in quanto impiegherebbe tutto il tempo a eseguire le istruzioni di overhead e non avrebbe più tmepo per eseguire i programmi applciativi.
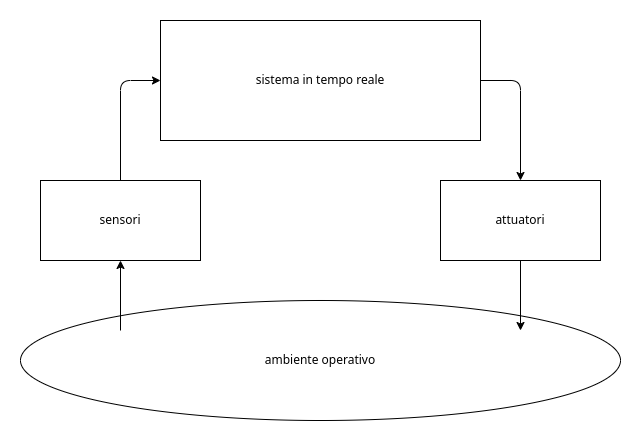
5.6. Sistemi in tempo reale
Sono uno degli ultimi step dell’evoluzione dei sistemi Operativi. Questa tipologia di OS si interfaccia in tempo reale con l’ambiente operativo attraverso sensori per recepire informazioni dall’esterno, e attuatori per poter comunicarvi.
Alcuni esempi di Real-Time OS sono:
- Gli smartphone: tramite il touchpad introducono il concetto di grafica, finestra, …
- I sistemi special purpose: dipendono strettamente dall’evoluzione di un sitema fisico nel tempo reale, come braccia robotiche, robot pulitori, macchine a guida autonoma, …
Per questi sistemi, soprattutto quelli embedded, è fondamentale riuscire a generare risposte agli input in tempi brevi per non avere errori.
Vedremo più avanti che i sistemi in tempo reale si dividono in:
- hard-real-time: la violazione di una deadline provoca effetti catastrofici sul sistema. Un esempio può essere un’auto a guida autonoma che non si rende conto di dover frenare o fare una curva
- soft-real-time: la violazione di una deadline non provoca errori distruttivi. Un esempio sono i servizi di streaming, dove un rallentamento provoca solo errori temporanei che non hanno effetti catastrofici.
6. Architettura di un sistema di Elaborazione
In questa parte rivedremo buona parte delle nozioni di architettura del calcolatore affrontati a Reti Logiche e Calcolatori Elettronici.
A livello hardware nei calcolatori si segue il modello di Von Neumann, che consiste in un bus sul quale sono collegate tutte le componenti del calcolatore: CPU, RAM, e tutte le varie periferiche (video, disco, tastiera, porte seriali, …).
La CPU è l’elemento architetturalmente più complesso all’interno del calcolatore (esclusa la GPU) ed ha il compito di eseguire le istruzioni che le arrivano in un formato detto CISC (Complex Instruction Set Computing). In realtà oggi la maggior parte dei processori converte le istruzioni CISC in istruzioni RISC (Reduced ISC) che semplifica e velocizza l’esecuzione delle istruzioni.
Infatti nei processori CISC si notò la regola dell’80-20: nell’80% dei casi, si utilizzava sempre lo stesso 20% delle istruzioni. Attraverso le RISC si ottimizza quel 20% di istruzioni, e si eseguono le altre come se fossero routine composte da quelle istruzioni semplificate.
In questo modo le istruzioni più comuni utilizzano 1 ciclo di clock, mentre le altre, molto più rare, utilizzano più cicli.
Le istruzioni che la CPU esegue non sono salvate nei suoi registri, bensì si trovano nella memoria centrale, ovvero la RAM. I registri della CPU hanno due ruoli:
- Registri di appoggio per dati intermedi
- Amministrano l’evoluzione del programma (
%rip,%rbp,%rsp) e ne monitorano lo stato (%rflag)
Per ottimizzare i tempi di lettura Von Neumann propose semplicemente di avere dei bus molto efficaci che non avessero un effetto bottleneck rispetto alla RAM e alla CPU, successivamente venne introdotto il concetto di cache.
La RAM (Random Access Memory) per il programmatore è l’equivalente di un array, dove l’indice di ogni cella viene chiamato indirizzo. Il prefisso Random indica proprio l’accesso casuale alla memoria, ovvero libero e diretto. Sulla RAM possiamo effettuare due operazioni:
- Lettura: non varia lo stato della memoria
- Scrittura: modifica lo stato della memoria aggiornandolo esclusivamente nelle locazioni desiderate
Il bus ha un ruolo fondamentale all’interno del calcolatore, poiché permette la comunicazione tra le varie componenti. È composto da centinaia di fili, ognuno con un ruolo diverso (indirizzi, dati, controlli, …).
Esistono due politiche di comunicazione, in particolare vediamo al politica master-slave..
In questa politica solamente il master (nel nostro caso la CPU) può iniziare la comunicazione.
In un sistema dove si ha un solo master si rimuove il problema della competizione di accesso al bus. In questo modo, tutti i dispositivi rimangono in “attesa” sul bus, ovvero sono in ascolto come ricevitori di segnale.
Dovremo quindi dedicare dei fili del bus per riuscire a identificare chi è il destinatario delle informazioni comunicate (RAM, disco, video, …) e in cosa consiste la comunicazione (r/w).
Il protocollo di comunicazione è quindi molto semplice:
- Tutti i dispositivi stanno in ascolto sul bus attendendo modifiche al suo stato
- Quando il master vuole iniziare la comunicazione per prima cosa inizializza i bit che definiscono:
- Il dipositivo slave con il quale si vuole comunicare
- L’operazione di comunicazione desiderata (lettura/scrittura)
- Tutti gli slave stanno in ascolto e solamente quello selezionato risponde alla CPU quando è pronto tramite handshake
- Dopo il segnale di ack la CPU inizia a comunciare i vari dati (indirizzi, valori, …)
6.1. CPU
La CPU a grandi linee esegue costantemente le seguenti fasi in ciclo:
- Fetch/Prelievo: la CPU recupera la prossima istruzione da eseguire. Per fare ciò si affida al contenuto di un registro interno chiamato
%ip(Istruction Pointer) o%pc(Program Counter) sul quale effettua dei calcoli per ottenere l’indirizzo della prossima istruzione da eseguire. Successivamente effettua una copia dalla memoria per recuperare l’istruzione all’interno di un Istruciton Register%ir. Ultima azione, importante per il proseguimento del ciclo, si incrementa il valore all’interno di%ipaffinché la prossima lettura sia dell’istruzione successiva - Decodifica: si decodificano i bit che compongono l’
%irche decodificano le istruzioni assembler in segnali che specificano quale operazione dellaALUutilizzare con quali dati. Rispetto al fetch questa operazione è molto più veloce - Esecuzione: l’operazione viene eseguita dalla
ALUe i risultati vengono propagati nei registri e/o in memoria
All’interno della CPU ci sono diversi registri di appoggio per le comunicazioni con il bus, in aprticolare:
MAR(Memory Address Register): registro di appoggio dove salvare l’indirizzo della cella di memoria desiderataMDR(Memory Data Register): registro di appoggio dove salvare il valore della cella di memoria desiderataPSW(Program Status Word): registro che conserva informazioni relative al privilegio del processo attualmente in esecuzione (USER/SUPERUSER)
6.2. Cache
È un ottimizzazione introdotta per minimizzare le letture verso la RAM, che è molto più lenta rispetto ai cicli di clock ddella CPU.
La cache si basa su due principi:
- Principio di Località Temorale
- Principio di Località Spaziale
Grazie a questi principi riusciamo ad aumentare il numero di istruzioni eseguite nell’unità di tempo.
Esistono diverse tecnologie di cache, dovuto al fatto che la cache (più veloce della RAM) è anche molto più piccola, quindi si possono generare collisioni nei contenuti.
Per ulteriori informazioni consultare gli appunti di Calcolatori dedicati
L’unica aggiunta che facciamo è distinguere due tipi di cache:
- I-Cache: cache relativa alle istruzioni. Non necessita la propagazione in memoria al cambio di contesto, è sufficiente invalidarla.
- D-Cache: cache relativa ai dati delle istruzioni. Necessita la propagazione in memoria dei dati al cambio di contesto
Esistono cache fino a tre livelli, in particolare la cache di I° Livello è implementata direttamente all’interno del circuito della CPU. La lettura di questi dati è quindi effettuabile in una piccola frazione di clock
6.3. Memoria
Si può tracciare una gerarchia tra i vari tipi di memoria:
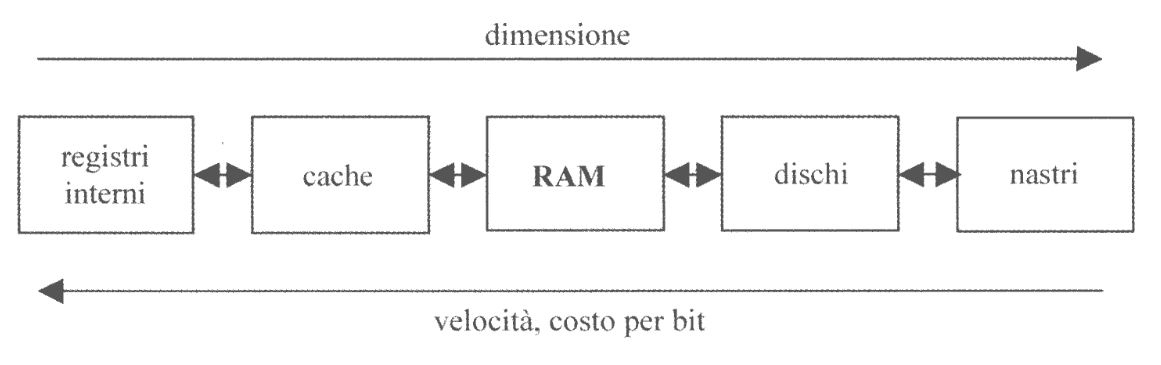
Possiamo associare questa gerarchia a due parametri: capacità totale della memoria, velocità di accesso in termini di costo per bit
Per il programmatore:
- Il disco: esistono diversi modi per gestire l’accesso del software
- RAM: vista come se fosse un vettore
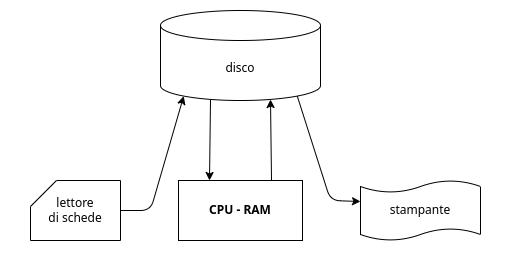
6.4. IO
Possiamo riassumere un calcolatore in un semplice schema a blocchi:
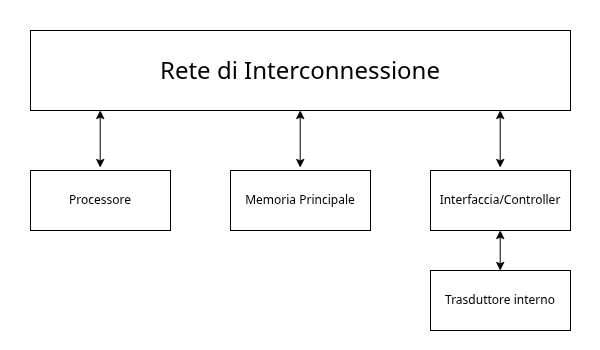
Da questo punto di vista possiamo riassumere tutte le periferiche di IO come l’insieme di due componenti:
- Interfacce: dette anche controllori, si preoccupano di gestire la comunicazione ad uno specifico trasduttore esterno
- Trasduttore Esterno: mezzo di comunicazione con l’esterno (touchscreen, cassa, …)
In questo modo possiamo scrivere i programmi ignorando completmente il funzionamento dei trasduttori, ma concentrandoci esclusivamente sulla comunicazione con le interfacce. Infatti tratteremo la comunicazione tra interfaccia e trasduttore come se fosse un processo esterno.
Dal processore sarà possibile accedere tendenzialmente a tre registri dell’interfaccia:
- Registro di controllo: specifica il tipo di comunicazione
- Registro di stato: utilizzato per comunicare un’aggiornamento dello stato del registro dei dati
- Registro dei dati: utilizzato per comunicare i dati
6.5. Interruzioni, Protezione e DMA
Le interruzioni permettono di interromprere il flusso di un programma per eseguire altri processi.
Per maggiori informazioni sul funzionamento di queste meccaniche:
7. Struttura dei Sistemi Operativi
Prendiamo in considerazione i sistemi operativi basati su UNIX. Questo sistema, detto modulare, prevede una struttura a strati divisa in diversi livelli, ognuno separato da una particolare interfaccia che specifica la funzionalità offerta dal modulo e come utilizzarla.
È inoltre presente un corpo contenente l’implementazione del modulo, non visibile al suo esterno.
Nei sistemi UNIX in particolare fanno parte del sistema sia le tipiche componenti di un OS invocate tramite le chiamate di sistema, eseguite in uno stato privilegiato e identificate globalmente con il termine di kernel, sia l’insieme dei programmi di utilità del sistema (shell, compilatori, caricatori, linker, librerie, …) eseguiti in uno stato non privilegiato come normali programmi.
A livello kernel troviamo il process control subsystem, ovvero la struttura necessaria alla schedulazione e alla virtualizzazione dei processi. Essa è a sua volta suddivisa in:
-
IPC: Inter Process Communication, permette la comunicazione tra processi diversi -
Scheduler: il suo compito è ripartire l’uso del processore tra i vari programmi in memoria, in modo che la CPU possa sviluppare un insieme di processi contemporaneamente -
Memory Manager: consente l’evoluzione concorrente di un insieme di processi mantenendo in memoria più programmi, ognuno con le sue esigenze
Nelle prime versioni UNIX al medesimo livello troviamo anche il file subsystem e i device drivers.
La necessità di proteggere le componenti del sistema operativo ha portato nel tempo alla necessità di introdurre il doppio stato di esecuzione. Questo garantisce soltanto alle componenti del sistema operativo di girare in stato privilegiato.
Per risolvere le problematiche dovute a questo doppio stato è stata proposta una soluzione nota come struttura a microkernel. In questa struttura, per ogni risorsa vengono definite due componenti del sistema operativo:
- I meccanismi che il sistema deve fornire
- Le specifiche strategie di gestione realizzate con i precedenti meccanismi
Ad esempio, nel caso del processore:
- Il cambio di contesto è il meccanismo che dobbiamo fornire
- Lo scheduler implementa le strategie vere e proprie per il cambio di contesto
In questi sistemi, l’insieme dei meccanismi costituisce il microkernel del sistema, unico componente a girare in stato privilegiato.
Le strategie invece fanno parte di programmi di sistema che girano come normali processi applicativi.
Questa struttura presuppone che, quando un processo applicativo deve richiedere l’uso di una risorsa deve prima interagire col corrispondente processo di sistema mediante un meccanismo di comunicazione tra processi (IPC).
Questi sistemi implementano maggiore portabilità e modificabilità, ma registrano perdite di efficienza legate al fatto che ogni chiamate di sistema si traduce in delle comunicazioni tra processi.
Per questo motivo venne subito introdotta una nuova struttura, detta struttura client-server. Tipica dei sistemi distribuiti in rete, immaginiamo di avere tanti nodi connessi ad una rete comune. Su alcuni nodi è implementato una parte del kernel, mentre altri fanno girare normali processi applicativi Questa struttura permette di mantenere invariata l’interfaccia del sistema operativo indipendentemente che esso sia allocato su uno o più dischi diversi. Si parla in questo caso di Sistemi Trasparenti.