1. Indice
2. Gestione della memoria
Quando parliamo di memoria parliamo di una risorsa hardware indispesabile per l’esecuzione di qualsiasi processo.
Abbiamo parlato di tecniche di virtualizzazione delle risorse attraverso una CPU-virtuale.
Questa astrazione funziona solo se associamo ad un processore virtuale anche una memoria virtuale, anche più grande dell’effettivo spazio fisico disponibile.
A livello hardware la gestione delle traduzioni tra memoria virtuale e fisica è gestita dalla MMU (Memory Managment Unit), ma abbiamo comunque necessità anche a livello software di avere delle strutture dati specializzate (descrittori) che ci permettano di gestire opportunamente questa nuova astrazione.
Poiché ogni processo adesso ha una memoria virtuale ed un suo processore virtuale, potrebbe accadere che si abbiano talmente tanti processi da non avere sufficiente spazio fisico per contenerne tutte aree virtuali.
È quindi necessario pensare a diversi aspetti:
- Come sviluppare un meccanismo di swap che ci permette di spostare porzioni di memoria virtuale dalla RAM alla memoria persistente nel disco, in particolare ad una suo sezione dedicata chiamata swap-aread.
- Come organizzare logicamente la memoria virtuale. Questa infatti non è altro che una struttura dati destinata a rappresentare le esigenze di memoria di un processo. Queste esigenze possono essere rappresentate in termini di un unico insieme di locazioni, con indirizzi contigui, oppure mediante più insiemi di locazioni contigue indipendenti, detti segmenti.
- Come organizzare fisicamente le porzioni di memoria utilizzate per allocare i processi. La virtualizzazione della memoria ci permette sì di riservare la memoria virtuale di un processo in un area di memoria fisica costituita da locazioni contigue, ma ci da anche la facoltà di mappare ogni segmento in zone di memoria non necessariamente contigue.
Per una prima introduzione sull’argomento paginazione e memoria virtuale è possibile consultare gli appunti di Calcolatori Elettronici dedicati.
2.1. Rilocazione statica e dinamica - MMU
Ipotizzando che tutta la memoria fisica sia a disposizione di un solo processo, è necessario tener conto che l’area di memoria fisica assegnata ad un processo non potrà coincidere con quella virutale, che consideremo di 6KB con indirizzi [0, 6140).
Seppur vero che l’area fisica assegnata ad un processo dovrà avere una dimensione in byte sufficiente a contenerne l’intera memoria virutale, la localizzazione nella memoria fisica avverrà a partire da un indirizzo $I$.
Sarà quindi opportuno, come descritto anche negli appunti di approfondimento sopra, distinguere tra:
- Indirizzi Virtuali: utilizzati da un processo per indirizzare la sua memoria
- Indirizzi Fisici: indirizzi di memoria corrispondenti alle locazioni fisiche nelle quali il codice e i dati del processo sono caricati
I due spazi di indirizzi non sono ovviamente indipendenti, ma sono legati da una funzione, detta funzione di rilocazione. Questa funzione dipende dalla porzione di memoria fisica utilizzata per caricare l’immagine del processo, e consente ad ogni indirizzo virtuale $x$ di corrispondere ad un indirizzo fisico $y$: \(\quad y = f(x) \approx I + x\)
Quando compiliamo un programma, il linker si occuperà quindi di tradurre gli indirizzi simbolici, inseriti dal programmatore, in indirizzi virtuali.
A questo punto possono avvenire più cosa, a partire dalla politica di rilocazione che utilizziamo.
Nel caso di rilocazioni statiche, il caricatore genererà l’immagine del processo traducendo gli indirizzi virtuali sommandogli il contenuto del program counter
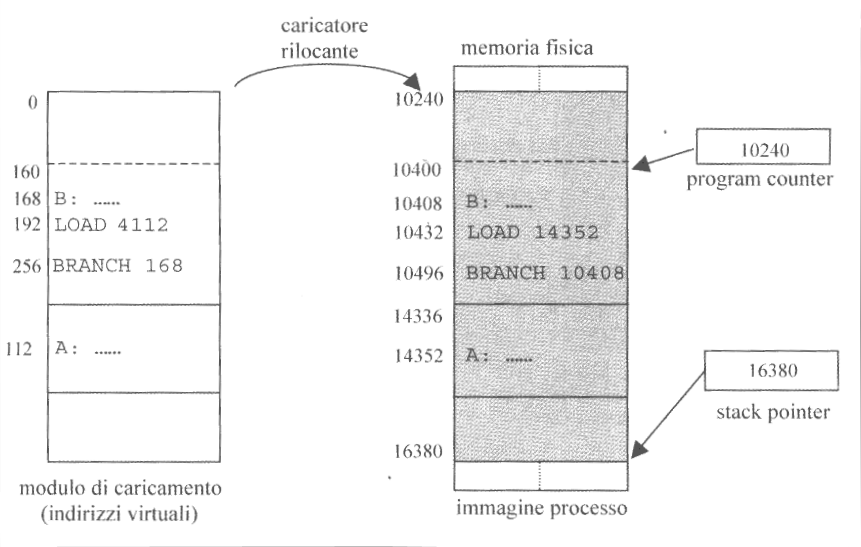
La rilocazione statica funziona in sistemi embedded ma non supporta meccanismi di swapping. Infatti, queste porzioni contengono al loro interno indirizzi fisici, richiedendo quindi di essere reinserite nelle medesime porzione di memoria nelle quali si trovavano prima dello swap, cosa tendenzialemnte impossibile.
Per evitare gli inconvenienti legati alla rilocazione statica è necessario ritardarla, attuandola solamente in fase di esecuzione. Questa nuova rilocazione si chiama rilocazione dinamica.
In questo caso, quando un processo viene allocato in memoria, il caricatore trasferisce nelle locazioni della partzione scelta, direttamente i contenuti del modulo di caricamento, ovvero vengono mantenuti gli indirizzi virtuali.
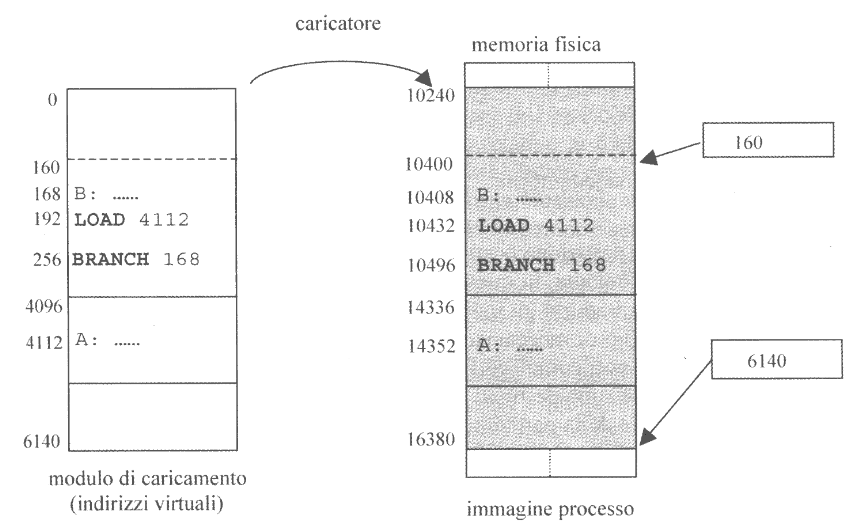
Poiché gli indirizzi virtuali sono indipendenti dalle particolari locazioni fisiche contenenti le istruzioni e i dati, nei registri PC e SP vengono caricati rispettivamente l’indirizzo virtuale della prima istruzione da eseguire e l’indirizzo virtuale della base dello stack.
Si delega quindi alla fase di esecuzione l’azione di traduzione degli indirizzi da virtuali a fisici, attraverso l’MMU che interfaccia la CPU alla memoria.
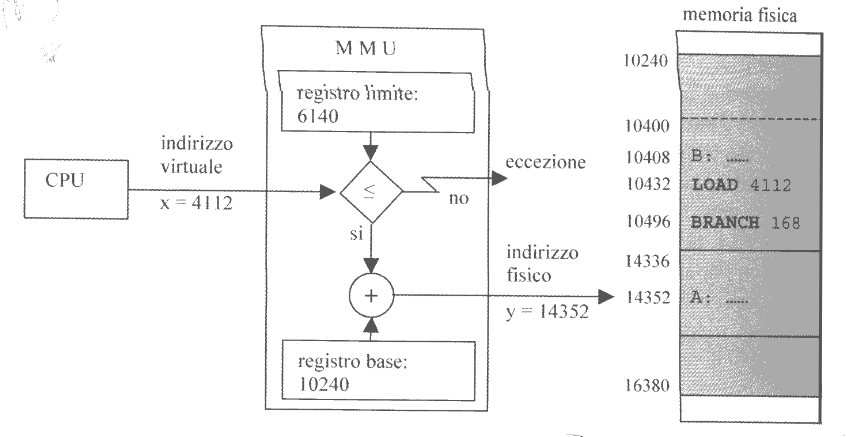
In questa nuova architettura, la CPU utilizza solo ed esclusivamente indirizzi virtuali.

La MMU, oltre a tradurre gli indirizzi da virtuali a fisici, si occupa anche di effettuare dei controlli di protezione.
Prima di tradurre un indirizzo virtuale, si effettua infatti in controllo che $x \in [0, 6140)$.
Se questo non fosse vero allora la MMU genera un eccezione di protezione, tipicamente il segmentation fault, che il sistema operativo dovrà gestire opportunamente.
2.2. Spazio Virtuale Segmentato
Durante la virtualizzazione della memoria possiamo segmentare lo spazio virtuale. Questa azione ha diversi vantaggi:
- Facilita il caricamento delle partizioni più piccole
- Permette di condividere dei segmenti per più processi diversi, senza dover conservare più copie delle porzioni
- Migliora le politiche di protezione sui singoli segmenti
Tuttavia dobbiamo considerare anche che la segmentazione della memoria provoca un aumento della complessità della traduzione degli indirizzi.
Se infatti ci basiamo sull’esempio fatto prima, per salvare i valori di PC e SP nella MMU dovremo avere $2\cdot n\cdot m$ registri, dove $n$ indica il numero di segmenti di un singolo processo, e $m$ è il numero di processi, ovvero una coppia per ogni segmento di ogni processo.
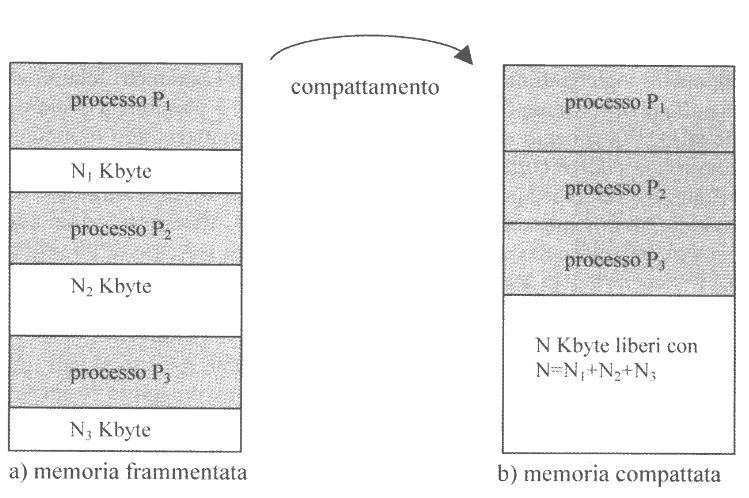
L’utilizzo di memoria segmentata potrebbe inoltre generare una memoria fisica “a buchi”, ovvero dove tra zone di memoria fisica di un processo e un altro si trovano delle aree vuote, detta frammentazione esterna. La frammentazione esterna è tuttavia sanabile con il compattamento.
Questa tecnica permette di rilocare i segmenti frammentati effettuando degli swap-out dei processi frammentati e successivamente degli swap-in per ricaricarli su indirizzi contigui, così da non avere più i “buchi” tra i segmenti dei diversi processi.
2.3. Paginazione
È una tecnica che permette di prendere uno spazio virtuale e suddividerlo in pagine logiche, caricando nella memoria fisica, divisa anch’essa in frame, le singole pagine in maniera non contigua.
La tecnica della paginazione permette di rimuovere il problema della frammentazione esterna, costringendoci però a cambiare la funzione di rilocazione.
La funzione di rilocazione non può più essere una funzione di “somma”, ma diventa una vera e propria tabella di corrispondenza, che mette in relazione ad ogni pagina logica un frame fisico.
Questa tabella dovrà quindi essere inizializzata e mantenuta consistente dalla MMU, generando un overhead nel nostro sistema.
3. Tecniche di gestione della memoria
Nel seguente schema possiamo vedere uno schema ad albero che elenca tutte le tecniche di gestione della memoria:
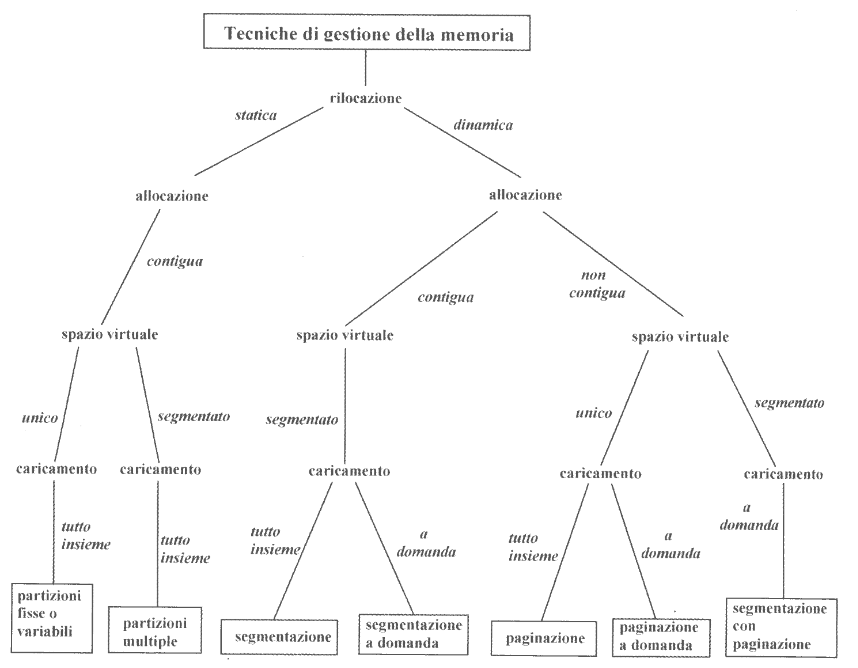
3.1. Partizioni Fisse e Variabili
È una tecnica di rilocazione statica, con allocazione contigua in uno spazio virtuale unico a caricamento unico.
Una partizione è definita come un’insieme di byte in memoria.
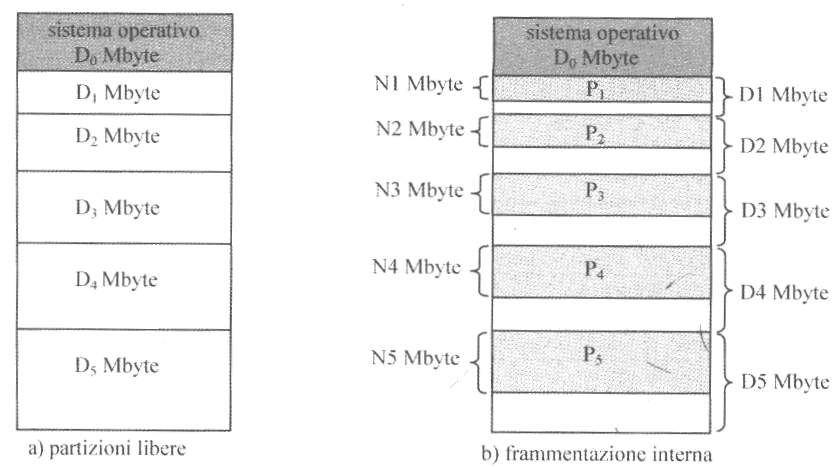
Il sistema a partizione fisse consiste nel suddividere la memoria in $(n+1)$ partizioni di indirizzo iniziale e dimensioni fisse, definite in fase di installazione dell’OS.
La prima delle partizioni è destinata a contenere la parte residente del sistema stesso, mentre le successive $n$ sono riservate per ospitare le immagini di altrettanti processi una volta rilocati i rispettivi spazi virtuali al loro interno.
Sulla destra possiamo vedere un esempio di memoria divisa in $6$ partizioni, dove la prima, con indirizzo virtuale $0$ e dimensioni $D_0$, è quella riservata al sistema operativo.
Le altre $5$ sono utilizzate per allocare i processi, e hanno dimensioni $D_1$, $D_2$, $D_3$, $D_4$ e $D_5$.
Quando viene creato un nuovo processo questo viene normalmente inserito nella più piccola partizione che lo può contenere tra quelle disponibili. È infatti estremamente raro che la dimensione di un processo coincida con quella di una partizione. Ne consegue che una considerevole porzione di memoria non viene utilizzata, fenomeno chiamato frammentazione interna.
Chiamando $N_i$ la dimensione necessaria dello spazio virtuale di un processo $P_i$, nella figura sulla destra la frammentazione interna corrisponde a: \((D_1 - N_1) + (D_2 - N_2) + (D_3 - N_3) + (D_4 - N_4) + (D_5 - N_5)\)
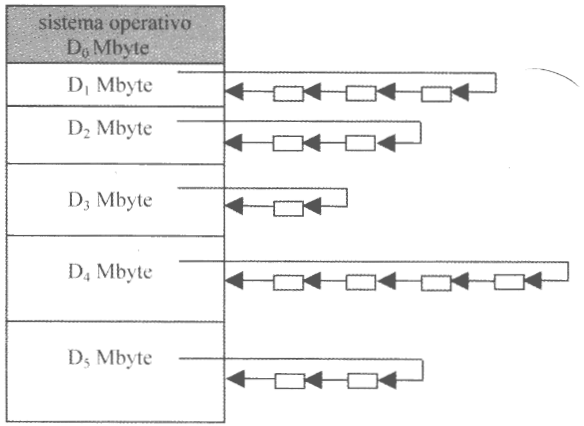
Pur adottando il cirterio della rilocazione statica degli indirizzi, questa tecnica si presta bene ad allocare dinamicamente la memoria ai processi.
Per ogni partizione, il sistema operativo mantiene una lista ordinata di descrittori, corrispondenti ai processi destinati a quella partizione. Il primo elemento della lista è fisicamente allocato in memoria mentre gli altri sono sono residenti nella swap-area. L’OS, seguendo una politica di round-robin, si occuperà di revocare la memoria al primo processo di ogni partizione, inserendo il suo descrittore in fondo ala rispettiva coda, e allocando il processo successivo, come nell’immagine sotto:
Per semplificare sia la fase di richiesta di una partizione libera che quella di rilascio si possono utilizzare due schemi.
Il primo è lo schema best-fit:
Vengono ordinate le partizioni nella lista per dimensione crescente. In fase di richiesta di una partizione di almeno $N$ byte la lista viene scandita e la prima partizione che viene trovata in grado di soddisfare la richiesta è sicuramente la più piccola tra tutte quelle di dimensioni superiori a $N$
Questo schema soffre di due inconvenienti:
- Una volta effettuata l’allocazione, il fatto stesso di cercare la più piccola partizione sufficiente genera la più piccola porzione di memoria non utilizzata, comportando un elevata frammentazione della memoria.
- In fase di rilascio, vedremo che con le partizioni variabili è necessario verificare se la partizione resa disponibile è adiacente ad uno o due partizioni libere per eventualmente compattarle insieme.
Un secondo schema spesso più usato è noto come first-fit
Si mantiene una lista ordinata per indirizzi crescenti delle partizioni
Questo schema risulta particolarmente efficiente in fase di rilascio, poiché le partizioni adiacenti nella lista sono anche quelle adiacenti inferiormente e/o superiormente, rendendo semplice il controllo sulle partizioni adiacenti.
Poiché lo schema di allocazione in partizioni fisse è molto inefficiente per quanto riguarda l’uso della memoria, è stato proposto un diverso schema per suddividere la memoria in partizioni, detto partizioni variabili.
Questo schema consiste nel definire dinamicamente le caratteristiche delle singole partizioni, in modo che queste corrispondano esattamente alle esigenze di memoria.
In questo modo eliminiamo la frammentazione interna, introducendo però la frammentazione esterna.
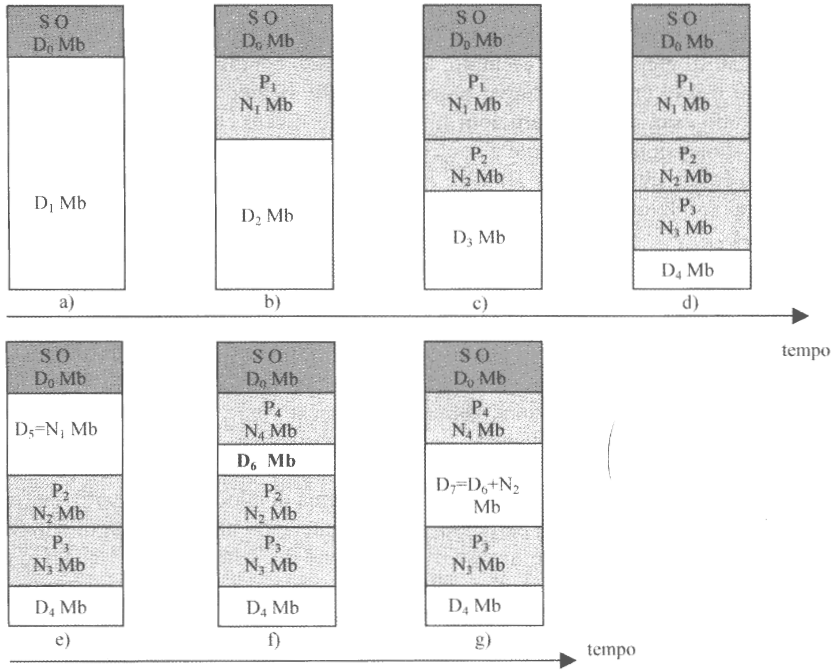
Nell’istante e dell’immagine sulla destra, il processo $P_1$ viene rimosso dalla memoria generando una nuova partizione $D_5$.
Nell’istante f viene allocato $P_4$ con dimensioni più piccole di $P_1$, andando a generare una nuova partizione $D_6 = D_5 - N_4$.
Nell’istante g si libera $P_2$ generando $D_7 = D_6 + N_2$.
Se immaginiamo che in un istante h arrivi un nuovo processo $P_5$ con dimensione $N_5 \in \bigl[\max(D_4, D_7), D_4 + D_7\bigr)$, accade che abbiamo complessivamente sufficiente memoria, ma questa non è contigua, impossibilitandoci ad inserirla nel momento nel quale si genera.
Dovremo attendere che un altro dei processi che si trova attualmente in memoria termini o venga sostituito, dato che essendo a rilocazione statica non possiamo effettuare rilocazione.
Per implementare questa soluzione si riserva nella memoria del sistema una locazione, indichiamola come memoria_libera, che contiene l’indirizzo di una partizione libera.
Questa struttura dati è una lista che contiene la dimensione in byte dell’attuale locazione e l’indirizzo di un’altra partizione libera.

3.2. Partizioni multiple
È una tecnica di rilocazione statica, con allocazione contigua in uno spazio virtuale segmentato a caricamento unico.
Permette a due o più processi di condividere il codice, così da eseguire quindi lo stesso programa, anche se su dati diversi.
Lo schema delle partizioni multiple coincide con il precedente per quanto riguarda l’allocazione di una generica partizione, ma la creazione di un processo implica adesso non solo la ricerca di una grande partizione, ma di tre più piccole, anche se non contigue.
La maggiore complessità richiesta al linker è ampliamente controbilanciata dal fatto che il segmento codice, non essendo più allocato in locazioni contigue al segmento dati può essere facilmente condiviso tra più processi. Inoltre, avendo partizioni più piccole riduciamo gli effetti negativi della frammentazione esterna.
3.3. Segmentazione
È una tecnica di rilocazione dinamica, con allocazione contigua in uno spazio virtuale segmentato a caricamento unico.
Questa tecnica prende lo spazio virtuale e lo divide in un numero variabile di segmenti.
Un indirizzo virtuale avrà adesso due dimensioni x = <segment, offset>, il primo identifica il segmento, mentre il secondo identifica l’offset all’interno del segmento.
Per tradurre un indirizzo virtuale in un indirizzo fisico dobbiamo quindi ridefinire la funzione di rilocazione.
Nei primi esempi di segmentazione, nella MMU erano contenuti tre segmenti per processo:
Fetch$\to$sg = 0: si riferisce alla fase di fetch. In questo caso l’accesso avverrà sicuramente nel segmento che comprende il codice del programmaExcecute$\to$sg = 1: si riferisce alla fase di esecuzione. In questo caso l’accesso avverrà sicuramente nel segmento che comprende i dati del programmaPOP/PUSH$\to$sg = 2: si riferisce alle operazioni che manipolano lo stack del programma.
![]()
Questa tecnica è stata poi migliorata, togliendo un limite al numero di segmenti, introdicendo una tabella dei segmenti, allocata nella memoria fisica del sistema, che sarà consultata dalla MMU.
Il descrittore di un processo dovrà quindi contenere anche un campo relativo alla sua memoria virtuale, mantenendo aggiornate due informazioni:
- Numero di segmenti che compongono la memoria virtuale
- L’indirizzo in memoria della tabella dei segmenti
Questi valori, nel momento in cui il processo viene schedulato e passa in esecuzione vengono caricati in due nuovi registri:
STLR(Segment Table Limit Register): contiene il numero di segmenti del processiSTBR(Segment Table Base Register): contiene l’indirizzo fisico della tabella dei segmenti
Nell’immagine sulla desta possiamo vedere come viene tradotto un indirizzo virtuale x generato dalla CPU.
Per prima cosa x viene diviso in <sg, of>.
Per prima cosa si confronta sg con il contenuto di STLR. Se sg >= STLR allora viene generata un’eccezione trap per indicare il tentativo di accedere ad un segmento inesistente.
In caso contrario sg viene utilizzato come indice per accedere alla tabella dei segmenti, per trovare l’elemento contenente i valori relarivi all’indirizzo iniziale I e la dimensione D della partizione di memoria nella quale il segmento è stato caricato.
A questo punto si confronta of con la dimensione D del segmento. Se of >= D allora viene nuovamente generata una trap per indicare il tentativo di accedere ad informazioni fuori dal segmento.
Altrimenti, ricaviamo l’indirizzo fisico come y = I + of.
![]()
Il ricorso alla tabella dei segmenti, allocata in memoria principale, genera una notevole perdita di efficienza della CPU. Infatti per ogni indirizzo generato è necessario raddoppiare gli accessi alla memoria: il primo per accedere alla tabella, il secondo per recuperare le informazioni.
Al fine di ridurre questa efficienza, nella MMU sono mantenuti alcuni registri associativi (tipicamente da 4 a 8), che fanno da cache per gli utlimi segmenti ai quali è stato fatto riferimento.
Questa memoria associativa è chiamata TLB (Translation Look-aside Buffer).
Qual’ora il valore del segmento sg fosse già presente in uno dei registri, non avremmo più bisogno di accedere alla memoria, effettuando un solo accesso alla memoria.
Questa maggiore complicazione del meccanismo di traduzione, trova la sua giustificazione nei vantaggi che che la segmentazione offre.
Per quanto riguarda la protezione, la segmentazione consente di effettuare tre diversi controlli nel momento in cui viene fatto l’accesso ad una locazione di memoria:
- Segmento non esistente
- Offset fuori dalla dimensione del segmento
- Associazione di specifici diritti di accesso ad ogni segmento, in modo che ogni riferimento a quel segmento sia consistente a tali diritti.
Per ottenere il terzo controllo, aggiungiamo alle singole entrate della tabella, ovvero ai descrittori di segmento, dei campi di controllo.
Per esempio, due campi di controllo sono il campo R (read) che consente l’accesso il lettura del segmento, e il campo W (write), che consente l’accesso il scrittura sul segmento.
Qual’ora un istruzione provasse a scrivere su un segmento che non ha il campo W settato, si genererà un eccezione di protezione.
Con la tecnica della segmentazione un processo può essere in due diverse condizioni:
- Allocato in memoria: tutti i segmenti che compongono il suo spazio virtuale sono residenti in altrettante partizioni
- Non allocato in memoria: tutti i suoi segmenti non condivisi sono contenuti nella swap-area
Per questo motivo è necessario aumentare il numero degli stati in cui un processo più trovarsi:
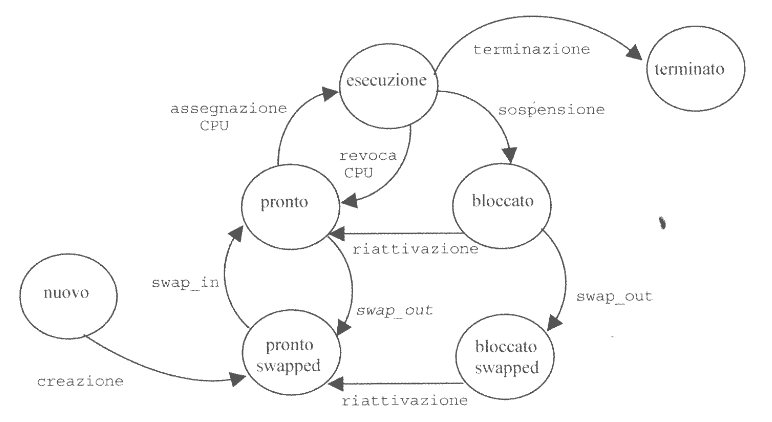
Le transizioni tra gli stati pronto o bloccato e i corrispondenti stati swapped corrispondo all’esecuzione delle primitive swap_in e swap_out.
La scelta del processo pronto a cui assegnare la CPU e quella del processo pronto da caricare in memoria corrispondono ai due livelli di schedulazione che avevamo indicato come short-termi scheduling e medium-term scheduling.
3.4. Segmentazione a domanda
È una tecnica di rilocazione dinamica, con allocazione contigua in uno spazio virtuale segmentato a caricamento a domanda.
Con questa tecnica è necessario complicare la funzione di rilocazione in modo tale che, durante l’esecuzione di un processo sia possibile mantenere in memoria soltanto una parte del suo spazio virtuale, ovvero solo quella necessaria a quel punto della sua esecuzione.
Per questo motivo è necesasrio abilitare la funzione di rilocazione a restituire:
- Il corrispondente indirizzo fisico
yse il segmentosgè presente in memoria - Generare un interruzione (
segment-fault) nel caso in cui il segmento non fosse presente
La funzione di gestione di questa interruzione avrà quindi il compito di cercare in RAM una partizione libera nella quale caricare il segmento richiesto e riattivare l’esecuzione del processo stesso per poter rieseguire l’istruzione che ha generato l’eccezione.
Se nell’atto di caricamento di un segmento non ci fosse spazio in memoria fisica è possibile scaricare sulla swap-area uno o più segmenti, sia dello stesso processo sia di altri processi, attraverso lo schema del rimpiazzamento.
Al fine di facilitare l’implementazione di algoritmi di rimpiazzamento efficienti, sono spesso disponibili ulteriori bit di controllo nel descrittore di un segmento. Ad esempio abbiamo i bit U (uso) e M (modifica), che possono essere letti e azzerati via software, e che vengono settati automaticamente via hardware ogni volta che viene fatto un riferimento/modifica al segmento.
Il bit M è utilizzato per capire se un segmento è stato o meno modificato, così da poter evitare eventuali riscritture sulla swap-area.
Il bit U invece è un bit utilizzato per valutare la freqeunza di utilizzo di ogni segmento, così da rendere più efficienti gli algoritmi di scelta dei segmenti da rimpiazzare.
3.5. Paginazione
È una tecnica di rilocazione dinamica, con allocazione non contigua in uno spazio virtuale unico a caricamento unico.
Per eliminare alla radice il problema della framentazione, che richiede un overhead non indifferente, sarebbe necessario poter allocare in memoria le informazioni utilizzando degli indirizzi virtuali contigui.
Per rendere ciò possibile, dividiamo lo spazio virtuale in blocchi di indirizzi virtuali di dimensioni fisse, detti Pagine.
Allo stesso modo, anche lo spazio fisico viene diviso in blocchi di indirizzi fisici delle stesse dimensioni delle pagine, detti Frame.
Ogni pagina verrà allocata in un frame libero.
Questa scelta può comportare che pagine consecutive nello spazio virtuale siano allocate in frame non consecutivi.
Per tradurre un indirizzo virtuale nel corrispondente indirizzo fisico è quindi necessario registrare in una tabella, detta tabella delle pagine, la corrispondenza pagina-frame.
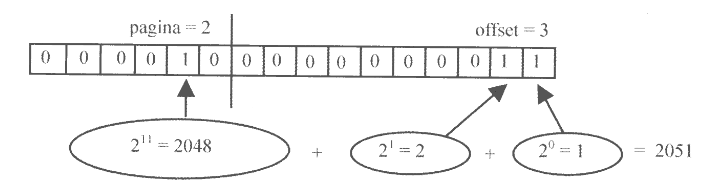
Nell’esempio a destra possiamo vedere una suddivisione in pagine di 1K su una memoria virtuale di 4K, ovvero di quattro pagine.
Per tradurre un indirizzo viruale x in un indirizzo fisico y è necessario sapere a in quale frame la pagina è stata salvata.
In particolare, sfruttiamo la divisione tra l’indirizzo x e la dimensione delle pagine per ottenere:
- Tramite il quoziente: la pagina alla quale
xappartiene. - Tramite il resto: l’offset all’interno della stessa.
Tendenzialmente la dimensione della pagina d è una potenza del due, in questo modo se $d = 2^x$ gli x bit meno significativi saranno l’offset, mentre i bit più significativi rappresenteranno il numero di pagina pf individuata.
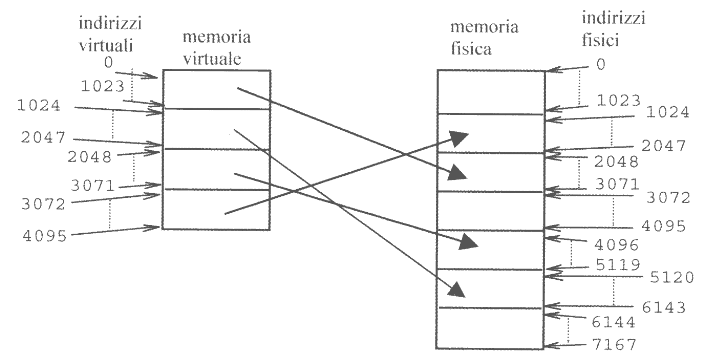
Ogni processo allocato in memoria possiede una propria tabella delle pagine.
La dimensione di questa tabella dipende dal numero di pagine che compongono lo spazio virtuale del processo, che dipende a sua volta dalla dimensione dell’intero spazio e dalla dimensione delle pagine. In generale le dimensioni delle pagine oscillano tra 512 Byte e 4 KByte, dimensioni che mantengolo il vantaggio di dividere in pagine senza introdurre il problema della frammentazione interna.
Supponendo che una pagina contenga 1024 locazioni e lo spazio virtuale di un programma di medie dimensioni sia composto da 256 pagine, la tabella delle pagine dovrà poter contenere almeno 256 elementi.
Queste tabelle non sono allocate nei rigistri della MMU, ma nella memora fisica. È tuttavia necessario che la MMU abbia un particolare registro interno che contenga l’indirizzo della tabella delle pagine del processo in esecizione.
Possiamo chiamarlo PTPR (Page Table Pointer Register) o, come nell’immagine, RPTP (Registro Puntatore alla Tabella delle Pagine).
Anche in questo caso è utile implementare il TLB per evitare accessi in memoria multipli.
![]()
Nella paginazione possono essere effettuati gli stessi controlli visti nel caso della segmentazione, anche se alcuni perdono di significato.
Quando un processo prova ad accedere ad un indirizzo x (che appartiene ad una pagina pg) il primo controllo è quello di verificare che la pagina pg sia una delle pagine del processo.
Questo controllo avviene verificando che il valore di pg sia minore o uguale al contenuto di un particolare registro di macchina PTLR (Page Table Lenght Register), che mantiene il numero di pagine totali per ogni processo.
Se pg supera questo valore allora si genera un eccezione di protezione.
Anche in questo caso possiamo assegnare ad ogni pagina dei campi di controllo in lettura e scrittura.
3.6. Paginazione a domanda
È una tecnica di rilocazione dinamica, con allocazione non contigua in uno spazio virtuale unico a caricamento a domanda.
Basandosi sui concetti della paginazione, sfrutta il fatto che un processo non necessita sempre di tutte le sue pagine.
La tecnica, analoga a quella della segmentazione a domanda, è quella più utilizzata anche nei sistemi paginati.
Il meccanismo hardware è molto simile a quello della segmentazione a domanda, e aggiunge ai campi di lettura R e scrittura W:
P: bit di presenza, caratterizza la presenza della pagina in memoriaU: bit di uso, utilizzato dagli algoritmi di rimpiazzamentoW: bit di scrittura, utilizzato dagli algoritmi di rimpiazzamento
Nel caso di sistemi che utilizzano la paginazione a domanda anche la swap-area è divisa in settori fisici di dimensioni uguali a quelle delle pagine.
Quando un processo viene creato tutti i descrittori associati hanno P == 0, e il campo dove si trova l’indice della pagina fisica contiene in realtà l’indirizzo della pagina sul disco.
Quando il processo farà l’accesso ad un indirizzo x, che appartiene alla pagina pg, si verificherà innanzitutto che pg sia tra le pagine del processo, e successivamente, il valore di P del descrittore associato.
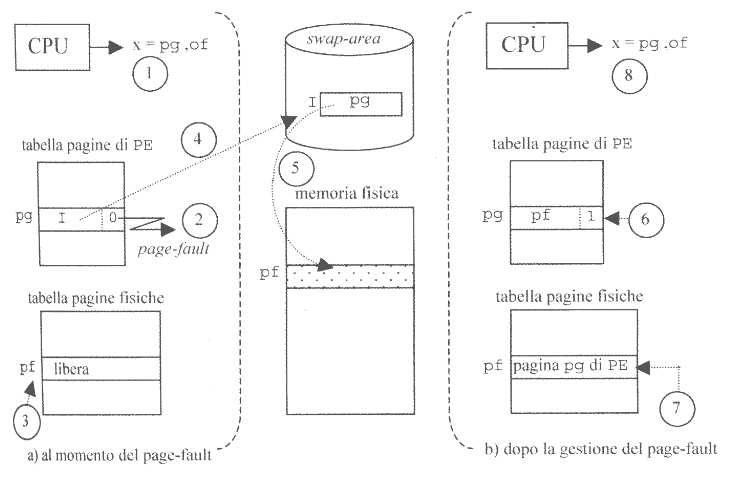
Se P == 0 si genera page fault, fermando l’esecuzione del processo.
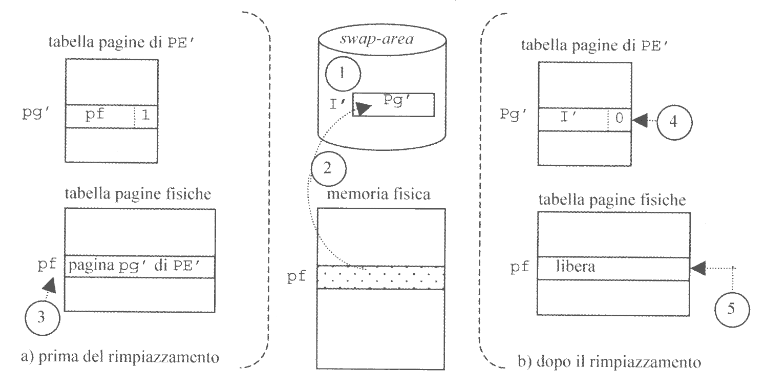
Il sistema operativo eseguirà quindi una routine per recuperare la pagina. (figura a sinistra)
Il primo passo è quello di verificare che ci siano frame liberi nella memoria dove salvare la pagina, attraverso la variabile pf.
Nel caso non vi fossero frame liberi, si utilizza un algoritmo di rimpiazzamneto delle pagine. Questo algoritmo è molto più semplice di quello della segmentazione a domanda, in quanto tutte le pagine hanno le stesse dimensioni.
(figura a destra)
Se invece ci fosse sufficiente spazio, il sistema operativo consulta la swap-area nell’indirizzo contenuto nel campo indirizzo del descrittore, copiandone il contenuto in memoria. Durante questo trasferimento dalla memoria secondaria alla RAM, tipicamente il processo viene bloccato.
Una volta caricata la pagina virtuale richiesta, il processo tornerà prima nello stato di pronto e poi in esecuzione.
Solamente quanto torna in esecuzione si aggiornerà la tabella delle pagine di processo, settando P = 1 e aggiornando il contenuto del campo indirizzo della pagina con l’indirizzo del frame.
Inoltre si aggiorna coerentemente il PC diminuendo il suo valore di uno. In questo modo l’istruzione che ha generato il page-fault può essere rieseguita (stavolta con successo) e il processo può continuare la sua esecuzione in maniera completamente trasparente.
L’algoritmo di rimpiazzamento consulta diverse informazioni per poter decidere su quale pagina effettuare la swap-out. Definiamo innanzitutto come working-set l’insieme delle località dei riferimenti utilizzati, inizialmente vuoto. Nel corso delle varie esecuzione, questo set aumenterà lentamente (per via dei principi di località), andando prima o poi a saturare tutte le locazioni disponibili. A questo punto si utilizza un algoritmo di rimpiazzamento per liberare delle località dal working-set.
Esistono diversi tipi di algoritmo di rimpiazzamento:
- Ottimo: rimpiazza le pagine che non verranno più riferite o che verranno utilizzate più nel futuro rispetto alle altre. (Teorico e irrealizzabile)
- FIFO: rimpiazza la pagina locale (aka del processo in esecuzione) che è da più tempo in memoria. Il rimpiazzamento è locale per evitare di propagare in futuro l’errore anche ad altri processi.
- LRU: rimpiazza la pagina non utilizzata da più tempo. È più efficiente rispetto al FIFO, ma anche più difficile da realizzare. Infatti è necessario modificare opportunamente la tabella delle pagine per introdurre un campo dove salvare un timestamp , ed è necessario consultarli tutti per recuperare il più vecchio e aggiornare i nuovi. Tra gli algoritmi implementabili è quello che riduce al minimo il trashing, ovvero diminuisce al minimo il
page-fault.
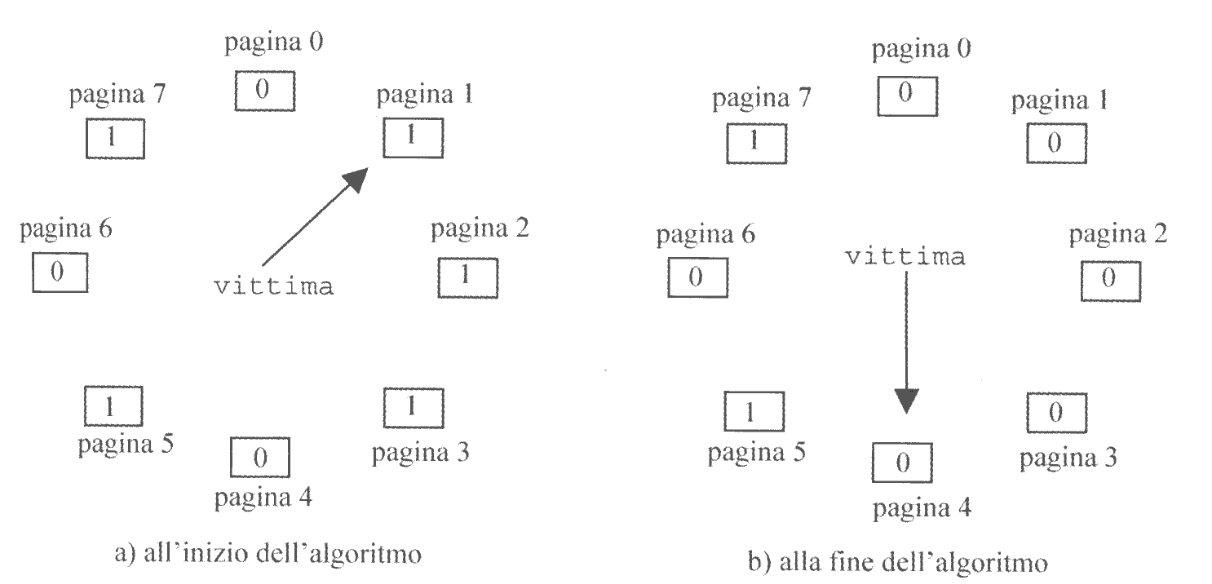
L’algoritmo utilizzato da UNIX è un’approssimazoine dell’algoritmo LRU, noto come second-chance o clock algorithm.
La tabella delle pagine fisiche viene gestita come un array circolare.
Viene mantenuta una variabile vittima. che consiste in un puntatore contenente l’indice della pagina fisica successiva a quella che è stata rimpiazzata per ultima.
Al prossimo page-fault si inizia a verificare la pagina il cui indice è contenuto nella variabile vittima.
In particolare si esamina il bit U della pagina associata:
U == 0: la pagina viene scelta per il rimpiazzamentoU == 1: si azzera il bit e si incrementa la variabilevittima, andando ad esaminare la pagina successiva, riverificando il bitU.
Poiché l’incremento della variabile è modulato al numero delle pagine fisiche M (vittima = (vittima + 1) % M) abbiamo la garanzia che troveremo certamente un pagina con U == 0.
Infatti, il Worst-Case è quello in cui andiamo a selezionare la pagina con la quale avevamo iniziato la scansione, dopo aver iterato sull’intera tabella.
Per ridurre il numero di trasferimenti tra memoria e disco, viene spesso preso in considerazione anche il valore di M.
Le pagine sono quindi classificate prima rispetto al valore di U, e successivamente si privilegiano le pagine con M == 0
3.7. Memoria segmentata e paginata
È una tecnica di rilocazione dinamica, con allocazione non contigua in uno spazio virtuale segmentato a caricamento a domanda.
Questa tecnica, utilizzata nei sistemi UNIX, offre i vantaggi sia della segmentazione che dalla paginazione.
In particolare, nei sistemi UNIX è possibile abilitare/disabilitare l’opzione della segmentazione.
La CPU genera un indirizzo virtuale x composto dalle due componenti <sg, sc> (<segmento, scostamento>).
Dopo le solite verifiche di protezione, sg viene utilizzato per accedere al descrittore del segmento nella tabella dei segmenti.
Il descrittore che si ottiene contiene a sua volta altri due campi: limite e base, dove adesso però base rappresenta l’indirizzo di memoria di una partizione utilizzata come tabella delle pagine del segmento.
Lo scostamento è a sua volta composto da sc = <pg, of>. L’indice pg viene utilizzato come indice nella tabella delle pagine (sempre previ controlli di protezione), per ottenere l’indirizzo del frame pf e andare a costruire l’indirizzo fisico y = <pf, of>
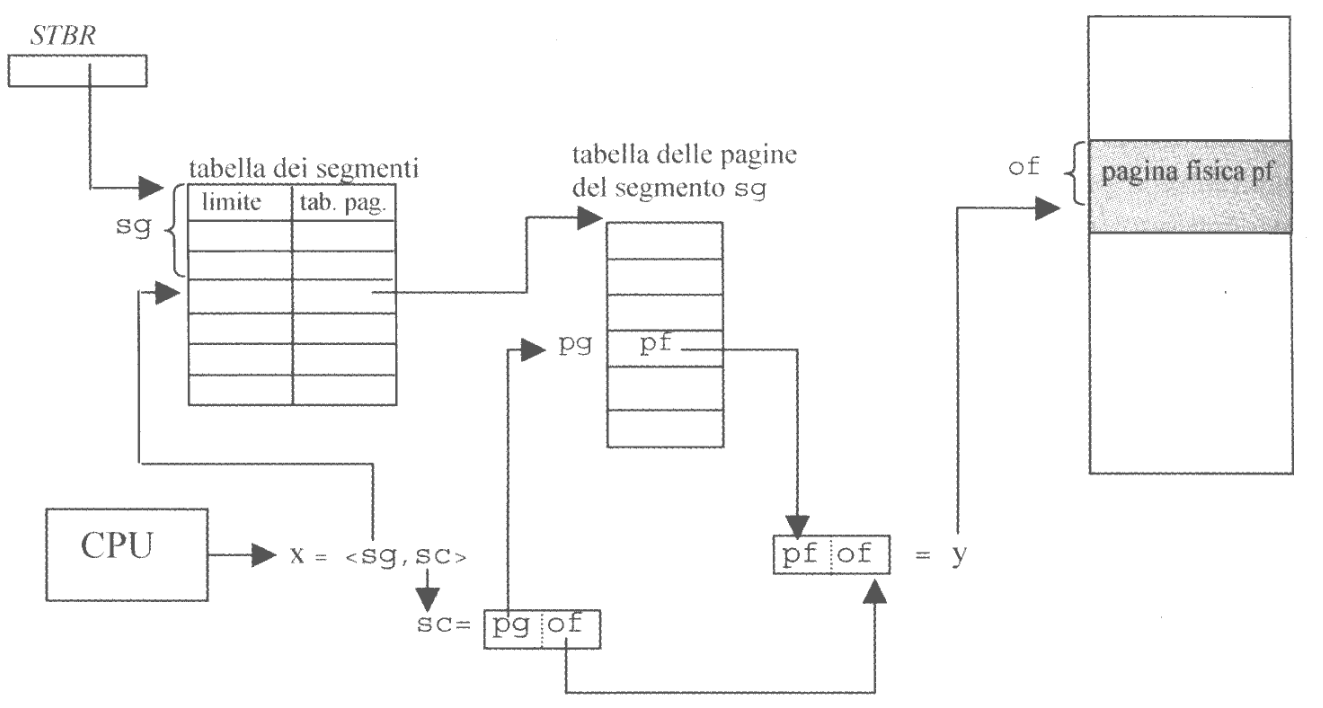
La tabella delle pagine del segmento non è necessariamente in memoria, quindi l’interruzione dei segment-fault viene gestita proprio per caricare tale tabella.
Così come potrebbe verificarsi P == 0 nella tabella delle pagine, generando un normale page-fault.
4. Gestione della memoria
Per informazioni aggiuntive riguardanti a come le tabelle di indirizzi sono salvate in memoria, è sufficiente consultare il seguente capitolo degli appunti di Calcolatori Elettronici.
UNIX disaccoppia la gestione del page fault con la sostituzione delle pagine, facendo in modo che ci sia sempre almeno un numero minumo di frame liberi, detto lotsfree.
Se vi sono almeno lotsfree frame liberi, allora si evita la sostituzione.
Per ottenere questo risultato, il kernel mantiene all’interno della tabella delle pagine fisiche una descrizione dello stato di allocazione della memoria (core map) nella quale ogni elemento rappresenta una pagina fisica e ne contiene le informazioni (libera/allocata, informazioni della pagina logica, a che processo appartiene, …)
Tuttavia l’evoluzione del sistema non è controllabile, ed è quindi possibile che il numero di frame liberi diventi minore di lotsfree.
Per risolvere questo problema, i sistemi UNIX hanno un pagedaemon (pid=2), che esegue periodicamente (ogni 250ms) e si occupa di sostituire le pagine solo se:
num_frame_liberi < lotsfree
Qualora la frequenza di paginazione sia troppo elevata ed il numero di pagine libere rimanga comunque inferiore a lotsfree nonostante l’intervento del pagedaemon, interviene un altro demon, chiamato swapper, che provvede al trasferimento di uno o più processi della memoria centrale a quella secondaria.
In particolare il daemon esegue al verificarsi di due condizioni:
num_frame_liberi < minfree && num_medio_frame_liberi < desfree
La variabile minfree rappresenta il numero minimo di frame liberi per evitare lo swapping dei processi.
La variabile desfree invece è il numero minimo di frame desiderabili, e agisce da filtro-passa-basso. Limita infatti il numero di swap in caso di momenti di picco di richieste, ma solamente quando page-fault avviene per lunghi periodi di tempo.
La relazione tra le costanti è la seguente:
lotsfree > desfree > minfree