1. Indice
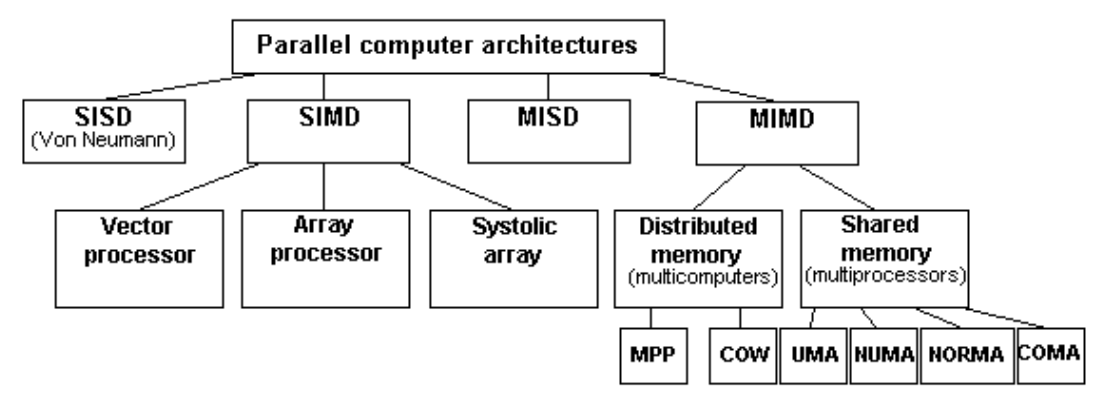
2. Tassonomia di Flynn
È un metodo di classificazione dei sistemi di elaborazione, che utilizza due punti di vista:
- La capacità del sistema di avere più flussi di istruzioni
- La capacità del sistema di avere più flussi di dati
SI (Single Instruction stream) |
MI (Multiple Instruction stream) |
|
|---|---|---|
SD (Single Data stream) |
Macchine SISD |
Macchine MISD |
MD (Multiple Data stream) |
Macchine SIMD |
Macchine MIMD |
2.1. Macchine SISD
Sono macchine a singolo stream, che rappresentano le tradizionali macchine sequenziali basate sul modello di Von Neumann usata da tutti i calcolatori convenzionali.
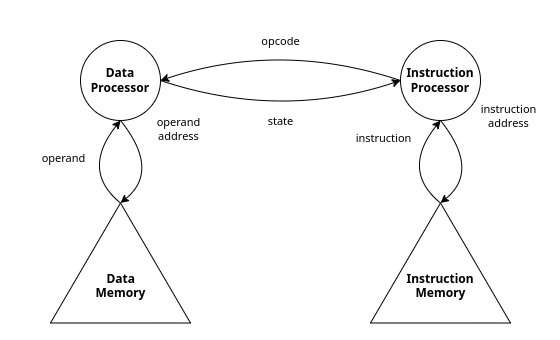
Il cerchio rappresenta un circuito in grado di eseguire istruzioni e/o gestire dati.
2.2. Macchine SIMD
Si differenzia dalle macchine SISD per il numero di Data Processor, ciascuno dei quali possiede una propria Data Memory.
Questo permette a più unità di elaborazione di eseguire contemporaneamente la stessa istruzione, lavorando su flussi di dati differenti.
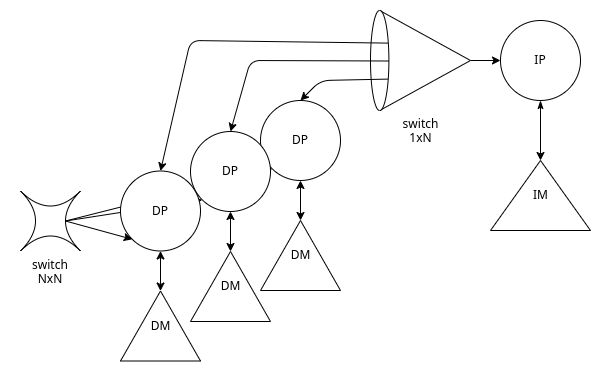
Per permettere la condivisione a tutte le DM dell’istruzione, viene utilizzato uno switch 1 a N
La topologia di interconnessione tra i vari processori può essere sia regolare che creata ad hoc.
Questa architettura permette comunicazioni regolari efficienti e poco costose, che non creano conflitti.
Il modello di computazione di queste macchine è Sincrono, ovvero gestito da un unica unità di controllo.
Questo permette due tipi di parallelismi:
- Temporale fasi diverse di un’unica istruzione sono eseguite in parallelo in differenti moduli connessi in cascata (pipeline)
- Spaziale: i medesimi passi sono eseguiti contemporaneamente su un arry di processori perfettamente uguali sincronizzaiti da un solo controllore
Alcuni esempi di architetture SIMD:
- Supercomputer vettoriali: tipici per lavorare su grandi matrici
- Vector Processor con caratteristiche pipeline
- Array Processor
- Systolic Array
I programmi che beneficiano dell’architettura SIMD, ad esempio per lavorare su grandi vettori, possono essere eseguiti, con opportune ma comunque piccole modifiche, da processori SISD.
Infatti avendo un operazione tra vettori c = a + b, il compilatore può tradurla in for (...) c[i] = a[i] + b[i].
2.3. Macchine MISD
Queste macchine hanno più flussi di istruzioni che lavorano contemporaneamente su un unico fllusso di dati.
Molti considerano questa categoria ancora “vuota”, ovvero senza esempi reali. Altri invece categorizzano i processori basati su pipeline proprio come macchine MISD.
Per ulteriori informazioni sui processori moderni basati su pipeline consultare gli appunti di Calcolatori dedicati.
2.4. Macchine MIMD
In queste macchine abbiamo tante unità di elaborazione connesse a tante untià di dati. Abbiamo infatto più flussi di istruzioni in parallelo che elaborano insiemi di dati che possono essere distinti, privati o condivisi.
Vediamo due categorie di macchine MIMD
2.4.1. Macchine a Memoria Distribuita DM-MIMD
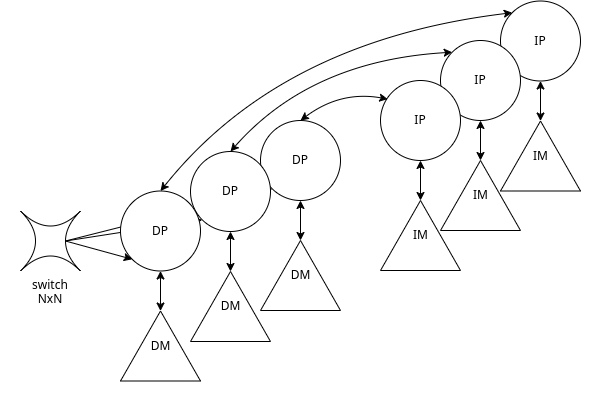
Non esiste memoria condivisa, ma ogni nodo esegue indipendentemente un flusso di istruzioni su un differente insieme di dati
Ogni coppia IP-DP (con le relative memoria) costituisce in pratica una macchina SISD.
Una qualsiasi rete di calcolatori rappresenta una macchina DM-MIMD. Infatti queste reti di interconnessione regolari permettono ai nodi di scambiare informazioni secondo il paradigma message passing. Queste reti permettono algoritmi ad elevata località e un elevata scalabilità.
Nelle DM-MIMD troviamo due sottocategorie:
DM-MIMD MPP(Massively Parallel Processing): L’elaborazioneMMPè utilizzata in applicazioni scientifiche e in particolari contesti di calcolo commerciale-finanziario. Il sistema si basa su migliaia di nodi (CPU standard ognuna con un proprio OS e una propria memoria) e su una rete di interconnessione custom molto potente (larga banda e bassa latenza). È inoltre necessario disporre di software capaci di partizionare il lavoro e i dati su vari processoriDM-MIMD COW(Cluster Of Workstations): Ha due caratteristiche principali:- High-availability: permette alla computazione di migrare da un nodo all’altro in caso di guasti
- High-load-balancing : permette di allocare i task nel nodo con minor carico. Un esempio di questo tipo di connessioni è la Gigabit Ethernet
2.4.2. Macchine a Memoria Condivisa SM-MIMD
Sono macchine multiprocessore che permettono la condivisione della memoria tra processori attraverso delle aree.
Affinché questa architettura funzioni lo switch NxN deve essere molto efficiente.
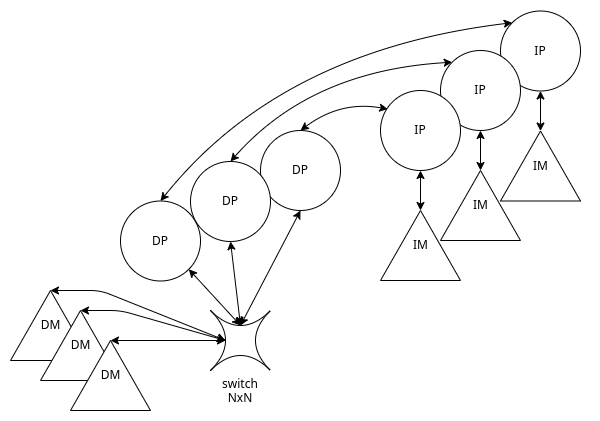
Se il numero di processori $N$ è “piccolo” $(N < 100)$, l’accoppiamento fra i nodi può essere stretto (comunicazioni veloci)
A differenza delle MD-MIMD questa architettura ha una scalabilità limitata.
2.5. Confronto SIMD e MIMD
SIMD |
MIMD |
|
|---|---|---|
| Hardware | Poco Unica Unità di Controllo |
Molto Tante Unità di Controllo |
| Costo | Costoso Necessita di processori specifici |
Poco costoso Gira su processori general-purpose |
| Memoria | Poca Possiede una sola copia del programma |
Tanta Ogni unità possiede una copia del programmma |
| Flessibilità | Poca | Alta flessibilità in termini di modelli computazionali supportati |
Possiamo vedere di seguito uno schema esteso che visualizza le principali tassonomie:
3. Tipologie di interconnessione
Vediamo adesso diverse tipi di interconnessione. Per fare ciò definiamo:
- Grado della rete: numero di connettori necessari per ogni nodo
- Diametro della rete: distanza massima tra una coppia di nodi misurata in numero di link
3.1. Bus
È la rete di interconnessione più semplice di tutte, composta da un unico link condiviso tra tutti i nodi.
Ha alcune limitazioni di natura elettrica dovuta a interferenze elettromagnetiche, che possono degradare la velocità di connessione. Inoltre, nel caso di rottura del link abbiamo zero tolleranza.
Dal punto di vista logico ha competizione massima sull’accesso al mezzo. È infatti necessario arbitrare gli accessi in caso di presenza di più master.
Questa rete ha:
- Grado 1
- Diametro 1
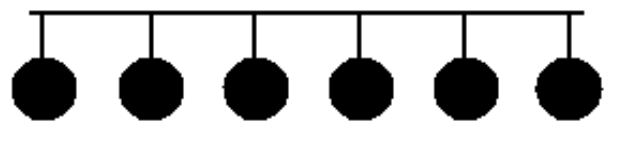
3.2. Linear Array
È una rete composta da $N-1$ link, che collega un nodo al “successivo” e al “precedente”.
Questo permette di ridurre al minimo la competizione. Nel caso ideale infatti possiamo avere $\frac{N}{2}$ comunicazioni in contemporanea.
In questa rete abbiamo nodi capaci di offrire servizi di routing, inoltrando informazioni ai propri nodi adiacenti. La rottura di un nodo o di un link crea due sottoreti che non possono comunicare tra loro.
Questa rete ha:
- Grado $1$ per il “primo” e l’“ultimo” nodo, $2$ per gli altri
- Diametro: $N-1$

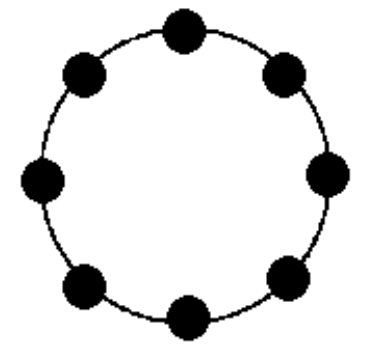
3.3. Ring
È la verisone migiorata del Linear Array, che aggiunge un link (arrivando a $N$) tra il “primo” e l’“ultimo” nodo.
È inoltre tollerante a $1$ guasto, che lo rende un Linear Array
Questa rete ha:
- Grado: $2$
- Diametro: $\Bigl\lfloor\frac{N}{2}\Bigr\rfloor$
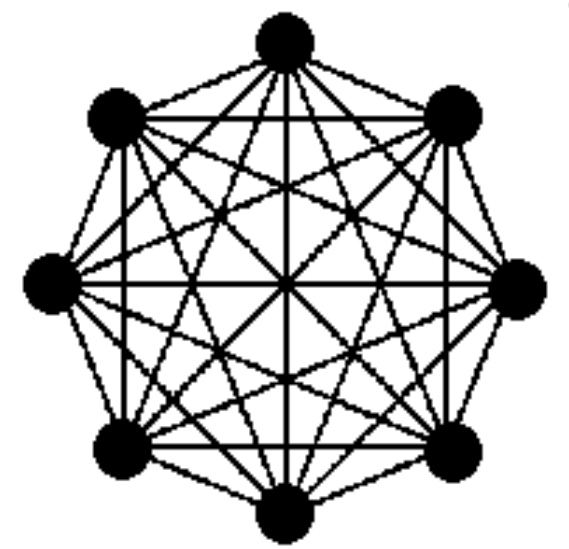
3.4. Connessione Completa
È la soluzione più costosa, al punto da non essere scalabile.
Il numero di link con $N$ nodi è infatti di $\frac{N\cdot (N-1)}{2}$.
Questa rete ha:
- Grado: $N-1$
- Diametro: $1$
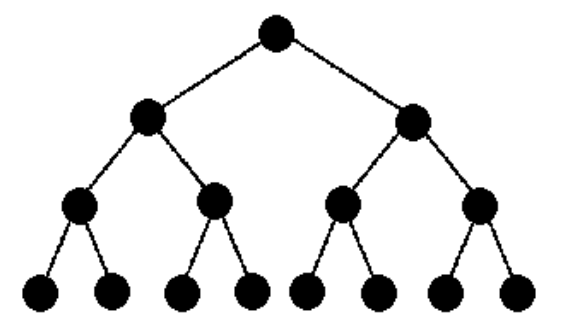
3.5. Albero Binario
Permette di liimtare il numero di link a $N-1$.
È tuttavia una topologia non scalabile, poiché i rami alti hanno elevato rischio di congestione, poiché i nodi intermedi e la radice devono poter fare da router.
Inoltre la radice è un potenziale “punto debole”, poiché la rottura di un suo link crea due sottoreti indipendenti.
Per migliorare la congestione e limitare la tolleranza ai guasti si più pensare ad una topologia detta fat-tree
Questa rete ha:
- Altezza: $h = \Bigl\lceil \log_2{N}\Bigr\rceil$
- Grado: $2$ per la radice, $1$ per le foglie e $3$ per gli altri
- Diametro: $2 \cdot (h-1)$
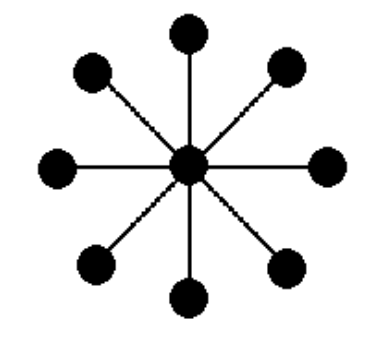
3.6. Stella
È una rete con $N-1$ link, con tolleranza ai guasti fortemente dipendente dalla “robustezza” del nodo centrale, che fa da single point of failure.
Questa rete ha:
- Grado: $N-1$ per il nodo centrale, $1$ per gli altri
- Diametro: $2$
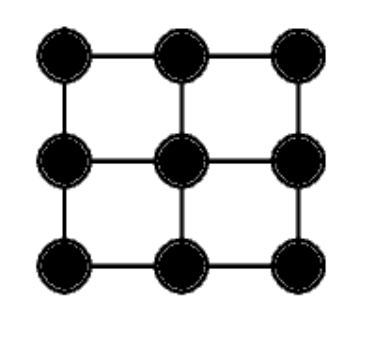
3.7. Mesh (2D)
Hanno come idea di base quella di creare delle matrici di nodi.
Possiede un numero di link uguale a $2 \cdot N - 2 \cdot r$ dove $r = \sqrt{N}$.
Ha una buona tolleranza ai guasti, che va da $2$ a $4$ guasti.
Questa rete ha:
- Grado: $2$ per i vertici, $3$ per gli “spigoli” e $4$ per gli altri
- Diametro: $2 \cdot (r - 1)$
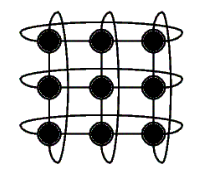
3.8. Toro (2D)
Considerando sempre $r = \sqrt{N}$, migliora la struttura della Mesh 2D.
Aumenta il numero totale di link a $2N$, migliorano però notevolmente sia la resistenza ai guasti sia la scalabilità
Questa rete ha:
- Grado: $4$ per tutti i nodi
- Diametro: $2 \cdot \Bigl\lfloor\frac{r}{2}\Bigr\rfloor$
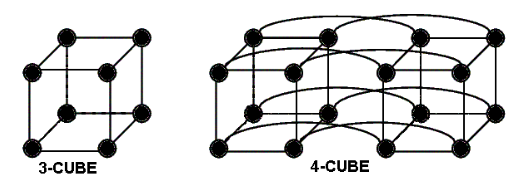
3.9. Ipercubo
Dato un ipercubo in $d$ dimensioni, abbiamo $N = 2^d$ nodi con $d \cdot \frac{N}{2} = d \cdot 2^{d-1}$ link.
Questa architettura è scalabile solo con un numero di nodi che è potenza di $2$.
Questa rete ha:
- Grado: $d$
- Diametro: $d$
Dato l’elevato numero di nodi, questi sono numerati attraverso il Codice Binario di Gray.
4. Metriche di Prestazione
Vediamo alcune metriche di prestazione, prendendo come riferimento un programma sequenziale eseguito su macchina SISD.
Abbiamo che:
- $T_1$: tempo di esecuzione su $1$ nodo
- $T_N$: tempo di esecuzione su $N$ nodi
4.1. Speed-up
Lo speed-up è:
\[S = \frac{T_1}{T_N}\]Il rapporto tra l’esecuzione sequenziale con l’esecuzione con l’esecuzione su macchine
SIMDoMIMD
Ci aspettiamo che $S > 1$, ovvero di avere un guadagno di veocità all’aumentare dei nodi.
Idealmente, vorremmo avere uno speed-up lineare $(S \in O(N))$ con il numero di processori usati nella macchina parallela. Nella realtà $S < N$, in particolare:
SIMD: spesso $S \approx N$MIMD: è difficile far crescere $S$, poiché è legato al software specifico che deve cercare di far lavorare a pieno carico tutte le CPU
4.2. Efficienza
L’efficienza:
\[E = \frac{S}{N}\]È il rapporto tra lo speed-up e il numero di processori
Come abbiamo detto prima, l’ideale sarebbe avere $E = 1$, ma nella realtà $E < 1$
4.3. Tempo Sequenziale
Il tempo sequenziale:
È il tempo impegato per eseguire istruzioni non parallelizzabili (operazioni I/O, costrutti condizionali, algoritmi intrinsecamente sequenziali)
Questo parametro è legato dalla Legge di Amdahl:
Un parallelismo “perfetto” non è mai raggiungibile poiché saranno sempre presenti sequenze di software intrinsecamente seriale
La legge ridefinisce lo speed-up come: \(\boxed{ S = \frac{T_1}{T_{seq}+\frac{T_1-T_{seq}}{N}} = \frac{N\cdot T_1}{T_1 + T_{seq}(N-1)} }\)
Possiamo notare che se $N \to \infty$: \(\boxed{ \lim_{N\to\infty}S = \frac{T_1}{T_{seq}} }\)
Un esempio di algoritmo non parallelizzabile è il calcolo dell’$i$-esimo numero della sequenza di fibonacci: \(f(i) = f(i-1) + f(i-2) \quad \wedge \quad \begin{cases} f(0) = f(1) = 1 \\ i = 2, 3, 4, ... \end{cases}\)
4.4. Multitasking
Ha un importanza notevole nelle macchine parallele per mantenere uno sfruttamento delle CPU molto elevato.
Per poter agire, deve rispettare il seguente vincolo: $P \gg N$
Dove $P$ rappresenta il numero di processi/task disponibili.