1. Indice
È importante sottolineare da subito che le specifiche precise dei processori Intel sono note solamente da Intel. Quello che faremo noi è darne una buona aprossimazione.
2. Pipeline
Il processore per come lo abbiamo visto fin’ora si occupa di eseguire tre operazioni: fetch, decodifica e infine esecuzione.
Le CPU moderne fanno ancora la stessa cosa, ma introducendo tutta una serie di accorgimenti che permettono di aumentare la velocità di esecuzione delle istruzioni.
Tra le varie possibilità per migliorare l’efficenza del processore abbiamo:
- Rendere il clock più veloce: ma la CPU ha un limite sopra al quale non riesce a stare al passo
- Diminuire le dimensioni dei transistor nel processore, così da poterne inserire di più: anche qui ormai siamo ai limiti imposti dalla fisica quantistica
- Inserire più processori in uno stesso chip, creando architetture multicore.
Noi vediamo quindi come in un unico core il processore riesca ad eseguire più istruzioni dallo stesso flusso di esecuzione contemporaneamente.
L’idea alla base di Intel, adottata già dal x486, è quella della pipeline.
Le istruzioni passeranno adesso in diverse fasi:
- Prelievo
- Decodifica
- Prelevio Operandi (dalla memoria o dai registri)
- Esecuzione dell’istruzione
- Scrittura del risultato nella destinazione
Ciascuna di queste fasi è eseguita da parti fisicamente differenti.
Infatti, all’interno del processore, sono presenti circuiti distinti specializzati nel compiere un compito (prelievo, decodifica, ALU, FPU, …).
L’idea della pipeline si basa sul fatto che quando un circuito termina il suo lavoro per una istruzione, rimane in attesa finché non terminano anche le altre fasi. Quello che quindi implementa è permettere al circuito di iniziare a operare sull’istruzione successiva:
| Prelievo | Decodifica | Prelevio Operandi (se necessario) | Esecuzione dell’istruzione | Scrittura del risultato nella destinazione | |
|---|---|---|---|---|---|
| $t_0$ | i |
||||
| $t_1$ | i+1 |
i |
|||
| $t_2$ | i+2 |
i+1 |
i |
||
| $t_3$ | i+3 |
i+2 |
i+1 |
i |
|
| $t_4$ | i+4 |
i+3 |
i+2 |
i+1 |
i |
In questo modo moltiplichiamo il numero di istruzioni completate al secondo per 5, ovvero il numero di stadi nella pipeline. Questo migioramento avviene solo se siamo in grado effettivamente di implementarla in maniera corretta.
Una prima descrizione della pipeline è la seguente:
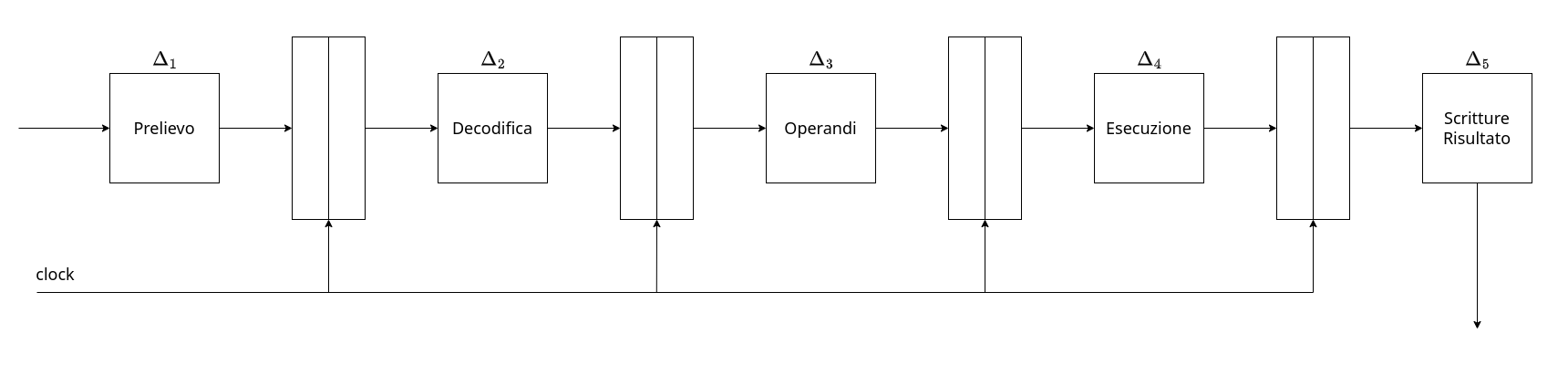
Con questa configurazione però il clock deve avere un periodo che deve essere almeno uguale al massimo $\Delta_i$:
\(\Delta = \max_{i\:\in\:[1,5]}\{\Delta_i\} + t_{setup}\)
Potremmo quindi velocizzare di 5 volte il clock solamente se $\Delta_i = \Delta_j, \forall i \ne j$, ovvero $\Delta_i = {1 \over 5}\Delta_T$.
Questo però può essere possibile solamente in circuiti creati proprio con l’idea della pipeline poiché in generale i $\Delta_i$ saranno diversi. Il recupero di un informazione da un registro è infatti molto più veloce del tempo di attraversamento di una RC di Divisione Intera.
Un altro problema sorge anche tra il prelievo e la decodifica dell’informazione. Infatti, senza aver decodificato l’immediato, nell’assembler non abbiamo idea a priori di quanto sia grande l’istruzione, perciò ci è impossibile capire quale sarà la prossima istruzione.
Le istruzioni Intel a 64bit hanno infatti una dimensione che può variare da 1Byte, ad esempio PUSH %eax, al massimo di 16Byte che contiene:
- 2 Prefissi
- Operatore
- La tripla
(scala, indice, base) - Valore immediato
- Valore di offset
Queste istruzioni sono dette dette CISC (Complex Istruction Set Computer).
2.1. Processori RISC
Per poter riuscire a risolvere parte dei problemi delle operazioni CISC sono stati introdotti negli anni ‘80 i processori RISC (Reduced Istruction Set Computer).
Tutti i processori RISC hanno istruzioni grandi tipicamente 4Byte, al cui interno le posizioni dei campi sono fissi:
OPCODE codiceOperando1 codiceOperando2 codiceDestinazione
Il formato RISC impone che le istruzioni siano regolari e semplici, e inoltre possano implementare semplicemente una pipeline.
Il RISC permette di semplificare le operazioni necessarie all’assembler per eseguire una qualsiasi operazione, così da poter diminuire il tempo di esecuzione.
Un’ulteriore differenza è che i processori RISC presentano una netta separazione tra le operazioni che operano nella memoria e quelle che non lo fanno. Saranno solamente le operazioni di LD (LoaD) e ST (STore) a comunicare con la memoria, e avranno il formato:
LD offset(base), dst
ST src, offset(base)
Un compilatore dovrà quindi cercare di creare un programma che lavori il più possibile con i registri.
Le regole RISC, tra le altre cose, implementano proprio il fatto che alcuni operatori, come la ADD, possono operare solo con i registri.
Questo risolve il probema del prelievo, ma abbiamo ancora risolvere il problema detto delle ALEE.
2.2. Problemi legati alla Pipeline (ALEE)
All’interno del flusso delle istruzioni ci sono alcune situazioni che ci impediscono di eseguire un’istruzione ad ogni ciclo di clock.
Queste situazioni prendono il nome di ALEE.
Esse comprendono tutti quei casi in cui il flusso di istruzioni ci impedisce di utilizzare la pipeline, generando gli stalli della pipeline.
Ne esistono di tre tipi:
ALEE strutturaliALEE sui datiALEE sul controllo
Le ALEE strutturali nascono dal fatto che l’esecuzione di due istruzioni in parallelo possa richiedere l’utilizzo della stessa risorsa.
Immaginiamo infatti il seguente caso:
ST %rax, (%rsi)
MOV $5, %rax
LD (%rdi), %rbx
In questo caso l’istruzione di LD si trova 2 istruzioni dopo quella di ST.
Quando la ST sarà all’ultima fase della pipeline (scrittura in memoria), la LD sarà alla terza (lettura dalla memoria), ed entrambe vorranno utilizzare il circuito che opera sulla memoria.
Le ALEE sui dati sono generate da istruzioni che utilizzano il risultato di un’istruzione precedente, come ad esempio:
op1 R1, R2, R3
op2 R3, R4, R5
Senza pipeline questo problema non sussite, in quanto attenderemmo che la prima operazione sia terminata prima di passare a quella successiva.
Utilizzando invece la pipeline, quando op2 necessita R3 come sorgente, op1 si trova ancora all’esecuzione, e non avrà ancora inserito il risultato.
Le ALEE sul controllo sono generate da tutte quelle operazioni che potrebbero alterare il normale flusso di esecuzione del programma, come ad esempio salti condizionati Jcond.
Per riuscire a gestire queste ALEE si inserisce nella pipeline un circuito di controllo che si occupa di prevenire i problemi.
Il controllo inserisce delle bolle (equivalenti ad una o più istruzioni NOP) che mettono in attesa un’operazione affinché quando entra nella successiva fase della pipeline non verranno generati comportamenti indesiderati:
- Nel caso delle due operazioni che utilizzano
R3basta inserire 2 bolle prima dell’ingresso diop2. - Nel caso di
LDeSTè sufficente invece inserire una bolla tra un’operazione e l’altra. - Nel caso di
Jcondla situazione è più complessa ma sempre gestibile.
Inserire le bolle ovviamente diminuisce il numero di istruzioni al secondo. Inserire 5 bolle equivale di fatti a tornare al processore senza pipeline.
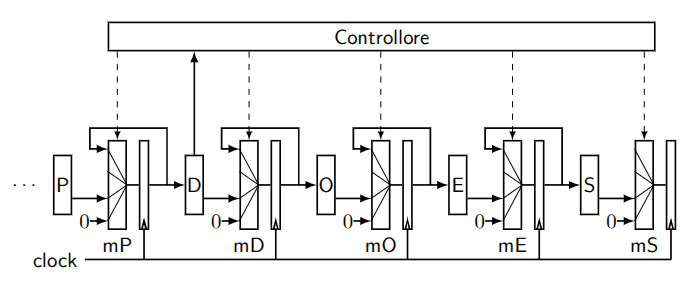
2.3. Ottimizzazioni
Come già detto è possibile fare tutta una serie di ottimizzazioni al compilatore, che può da solo rilevare le ALEE e inserire istruzioni non correlate e non conflittuali tra le operazioni incriminate.
Questo processo è detto ottimizzazione di schedulazione.
Un esempio è il seguente:
Prima
ADD R1, R2, R3
SUB R3, R4, R5
ADD R6, R7, R8
SUB R9, R0, RA
Dopo
ADD R1, R2, R3
ADD R6, R7, R8
SUB R9, R0, RA
SUB R3, R4, R5
È tuttavia anche possibile agire anche lato hardware.
2.3.1. ALEE sui dati
Riprendiamo il caso
op1 R1, R2, R3
op2 R3, R4, R5
op2 non necessità tanto di R3, quanto del suo contenuto, che è calcolato da op1 già alla fine dell’esecuzione.
Quello che possiamo fare quindi è inserire un collegamento tra esecuzione e recupero operandi, chiamato circuito di bypass.
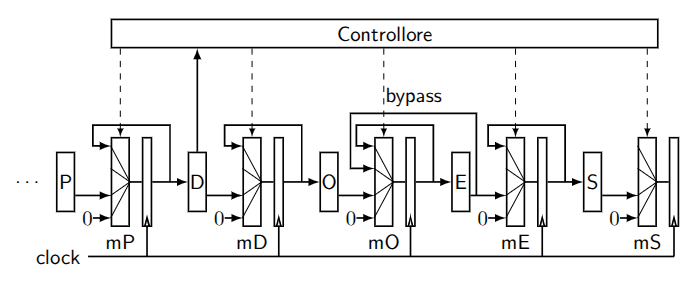
2.3.2. ALEE sul controllo
Per ottimizzare questi casi quello che fa il processore è cercare di indovinare dove salteremo.
Il processore effettuerà una scelta, vedremo più avanti come, e inizierà a prelevare le istruzioni dal punto che lui crede sia quello al quale salteremo. Capiremo se abbiamo fatto la giusta scelta solamente quando la jump verrà realmente eseguita.
Uno sbaglio in questa predizione comporta pagare il prezzo di quella che è chiamata branch miss, ovvero dovremo tornare a recuperare le istruzioni ignorando quello che avevamo già precalcolato. Possiamo permetterci ciò anche in virtù del fatto che quanto precalcolato non ha effetti a lungo termine, in quanto questi avvengono solo alla scrittura.
Al primo salto il processore segue regole statiche per indovinare dove andrà a finire:
- Se l’indirizzo di destinazione è precedente a quello dell’istruzione si aspetta un loop, indirizzerà quindi ad una delle etichette precedenti.
- Se l’indirizzo di destinazione è successivo a quello dell’istruzione si comporta come se la
Jcondfosse un sempliceNOP, prelevando l’istruzione successiva
Per rendere questo processo dinamico salviamo in una struttura dati tutta una serie di informazioni relative ai salti già eseguiti. Le istruzioni di salto già avvenute cercano quindi di capire l’esito del salto riutilizzando questi dati, ricordando quando e dove siamo saltati e quando invece siamo “andati dritti”.
Nel caso dei cicli tuttavia potremmo andare in errore ben due volte:
- All’ultima esecuzione del
Jcondche non dovrà più essere eseguita - Alla prima esecuzione della stessa
Jcondqual’ora vi tornassimo in un secondo momento
Una delle tecniche per conservare i dati sui salti precedenti è implementare per ogni salto un contatore.
Il contatore è un circuito a quattro stati:
- Strongly Not Taken (SNT)
- Weakly Not Taken (WNT)
- Weakly Taken (WT)
- Strongly Taken (ST)
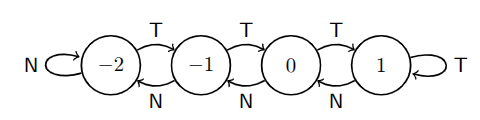
La regola è che:
- La prima volta, a seconda che si salti o meno assumerà lo stato di WNT o WT.
- Aumenta di uno per ogni salto effettuato (SNT $\to$ WNT $\to$ WT $\to$ ST)
- Diminuisce di uno per ogni salto non effettuato. (SNT $\leftarrow$ WNT $\leftarrow$ WT $\leftarrow$ ST)
Predittori migliori ricordano anche la storia del salto, associando uno sheet register contenente una sequenza di bit che rappresentano lo storico dei salti effettuati (1) e non (0).
Da questa informazione il predittore cerca quindi di imparare a utilizzarlo, cercando di trovare pattern.
In generale tutte queste cose vengono fatte dal Branch Target Buffer (BTB), a tutti gli effetti una cache, che:
Ha come scopo associare ad ogni salto il proprio esito e la destinazione del salto (se avviene)
L’operatore di prelievo si baserà quindi proprio sul contenuto di BTB per scegliere da dove recuperare i dati dopo aver riconosciuto un istruzione di salto.
Il BTB non si preoccupa delle colllisioni come avviene con la cache di memoria, poiché un suo errore non porta a effetti disastrosi ma “solamente” degli step della pipeline.
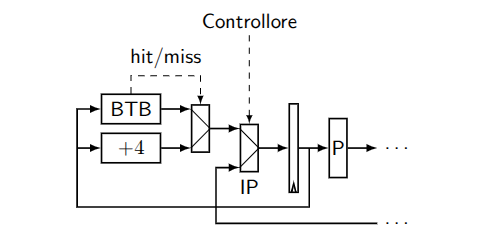
2.3.2.1. RET
RET è un operatore di salto indiretto molto usato e con una struttura statica.
Perciò possiede un suo circuito autonomo che si occupa di recuperare in autonomia l’indirizzo di salto dalla pila.
3. Architettura Intel
Nel 1995 Intel produce il Pentium Pro, la cui architettura è la base sulla quale si evolvono ancora oggi i processori moderni.
Intel ha tentato di cambiarne degli aspetti nel tempo, ma con esito insufficente.
L’idea principale di questo processore è:
Prendere le istruzioni
CISCe tradurle internamente in istruzioniRISC.
Da ora in poi faremo delle ipotesi sulle operazioni vere e prorie utilizzate.
3.1. Fase di Fetch e Decode
La prima fase dei processori Intel è composta da Fetch e da Decode.
Questa fase prelieva microistruzioni CISC per tradurle in microistruzioni RISC.
Una singola microistruzione CISC può tradursi come:
- Un’unica microistruzione
RISC - Più microistruzioni
RISC(più raro ma possibile)
Il circuito di Fetch ha al suo interno due buffer da 16Byte l’uno. Sono due poiché, per via delle dimensioni variabili delle operazioni CISC, non sappiamo nemmeno dove l’operazione inizi. È quindi possibile che una singola istruzione possa sforare il primo registro.
Il circuito di Decode si divide invece in due fasi:
- Fase di predecodifica: questa fase è necessaria a capire dove si trovano le istruzioni passate dalla
Fetch; - Fase di decodifica: si occupa di decodificare le istruzioni recuperate dalla
Fetchper tradurle in microistruzioniRISC. Nel Pentium Pro venivano decodificate fino a 3 istruzioni alla volta, oggi, nei processori moderni, si arriva a 5.
Facciamo quindi un esempio di quello che compiono la Fetch e la Decode, immaginando di avere la seguente istruzione:
ADD %rax, 1000(%ebx, %ecx, 8)
La traduzione utilizza registri interni ai quali il programmatore non ha accesso, che chiamiamo per adesso tmp.
La traduzione diventa quindi la seguente:
SHL %ecx, $3, tmp1
ADD %ebx, tmp1, tmp1
LD 1000(tmp1), tmp2
ADD %rax, tmp2, tmp2
ST tmp2, 1000(tmp2)
Immaginiamo invece di avere il sequente spezzone di programma:
// ...
for(int i = 0; i < 100000; ++i){
a[i] = v1[i] + v2[i];
}
// ...
Ogni operazione effettuata nei vari cicli del for è indipendente dalle altre.
Non abbiamo quindi nessun obbligo ad eseguirle nell’ordine che il programmatore desidera. Infatti, se avessimo sufficenti sommatori a disposizione, potremmo persino effettuarle tutte insieme in parallelo.
Se i vettori sono grossi, è possibile inoltre che una loro parte si trovi persino in cache, quindi sarebbe molto più veloce da recuperare piuttosto alle altre in RAM.
Quindi, mentre attendiamo che arrivino dalla RAM le miss della cache è conveniente cominciare a calcolare quelle operazioni che invece hanno fornito una hit.
Per essere completamente precisi, in realtà tra un’operazione e l’altra sono presenti dei salti incondizionali, che possiamo ancora una volta cercare di indovinare. A differenza della previsione delle pipeline adesso però, le istruzioni nell’indirizzo indovinato verranno eseguita in tutto e per tutto, andando anche a scrivere in memoria se lo richiedano. Dobbiamo quindi riservarci un modo che ci permetta di effettuare il rollback delle scritture qual’ora avessimo sbagliato a prevedere il salto. Li vedremo meglio più avanti.
3.2. Esecuzione fuori ordine
Portando degli accorgimenti al processore, possiamo permettergli di eseguire delle istruzioni fuori ordine rispetto a quello imposto dal programmatore, o persino in parallelo tra di loro.
Queste modifiche avvengono dopo la fase di Fetch e Decode, quindi lavoreremo con istruzioni RISC:
op1 src1, src2, dst
Possiamo cercare di modificare l’architettura del processore affinché sia in grado di eseguirle nel momento stesso in cui esse sono pronte, anche se quelle precedenti non sono ancora state eseguite. L’architettura che vediamo adesso non esiste nella realtà, ma è comoda per farci capire meglio i vari problemi da risolvere.
Per ottenere questo risultato immaginiamo di avere più di un’unica ALU, ognuna preceduta da quelle che chiamiamo stazioni di prenotazione.
Nella realtà ognuna delle varie ALU è specializzata in qualcosa di diverso dalle altre, ma noi immagineremo che sono tutte uguali.
Proseguiamo aggiungendo un’ulteriore componente che chiamiamo emissione.
Questo componente riceve le istruzioni dalla decode e le smisterà nelle varie stazioni di prenotazione passando attraverso i registri interni, diversi da quelli utilizzabili dal programmatore e che, oltre ai dati stessi, contengono anche due campi aggiuntivi:
W(writing)C(count)
Le ALU invieranno i risultati in automatico, tramite 1 o più bus, ai registri.
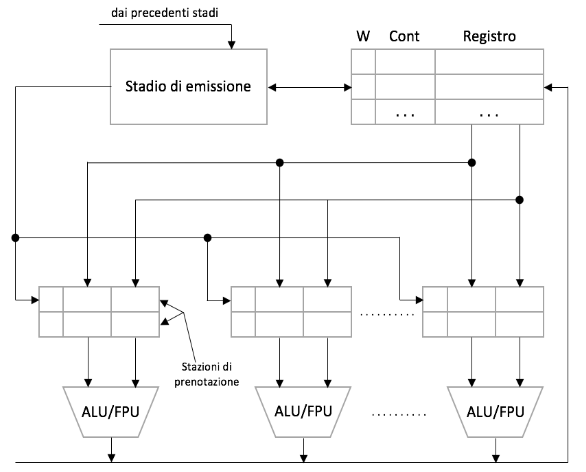
3.3. Dipendenze
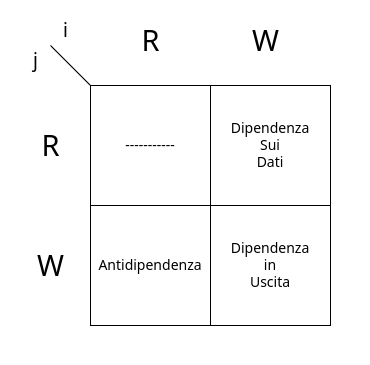
Affinché il risultato finale dei registri sia significativo, dobbiamo rispettare una serie di condizioni chiamate Dipendenze, che si dividono in tre tipi:
- Dipendenze sui Dati
- Dipendenze sui Nomi
- Dipendenze sui Controllo
Le dipendenze sono proprietà del programma, indipendenti dal circuito che esegue il programma.
3.3.1. Dipendenze sui Dati
Sono definite così:
Un’istruzione
idipende dai dati di un’altra istruzionej, precedente ad essa, seiutilizza come uno dei registrisrcil registrodstdij.
ADD R1, R2, R3
; ...
SUB R3, R4, R5
Le Dipendenze sui Dati forzano le istruzioni dipendenti a non poter essere riordinate liberamente, poiché è necessario che l’istruzione i venga eseguita dopo j, per avere il contenuto corretto del registro che dovrà utilizzare.
Per risolvere questo tipo di dipendenze, facciamo in modo che l’emissione setti il bit W del registro dst dell’istruzione che sta emettendo.
La stazione di emissione, prima di inviare i dati alla ALU, valuterà il bit W dei sorgenti, inviandoli solamente quando dst->W == 0.
3.3.2. Dipendenze sui Nomi
Le dipendenze sui nomi si differenziano in due tipi:
- Antidipendenze
- Dipendenze in uscita
Antidipendenza
Sono così definite:
Un’istruizone
isi dice antidipendente da un’altra istruzionej, successiva ad essa, seiutilizza comesrclo stesso registrodstdij.
Per questo tipo di dipendenze è quindi necessario che j venga eseguita dopo di i, affinché non aggiorni troppo presto i suoi sorgenti
ADD R1, R2, R3
; ...
SUB R4, R5, R1
Dipendenza in uscita
Sono così definite:
Un’istruzione
isi dice dipendente in uscita rispetto ad un’altraj, se entrambe vogliono scrivere nello stesso registrodst.
In questo caso rischiamo che eventuali istruzioni tra le due lavorino con l’uscita di quella successiva, e non della precedente.
ADD R1, R2, R3
; ...
SUB R4, R5, R3
Un modo per risolvere le dipendenze sui nomi è far andare in stallo l’emissione. Questa può infatti entrare e uscire liberamente dallo stato di stallo, tramite dei controlli.
Per le dipendenze in uscita, verrà controllato il bit dst->W, e propagherà l’istruzione solo se dst->W == 0.
Per quanto riguarda le antidipendenze, si valuterà il campo dst->C. Anche in questo caso l’istruzione verrà propagata solo se dst->C == 0.
Il campo C di un registro viene:
- Incrementato dal circuito di
emissioneogni qual volta quel registro è unsrc. - Decrementato dalla
ALUquando l’operazione viene completata.
3.3.3. Dipendenze sul Controllo
Un istruzione
iè dipendente dal controllo di una istruzionej, precedente ad essa, sejpotrebbe comportare un salto che produrrà un flusso non definito a priori del programma.
Le Dipendenze sul Controllo indicano quindi che l’esecuzione di una serie di istruzioni dipende dal controllo dell’esito di una precedente.
CMP ;...
JE fine1
ADD ;... # Sono Dipendenti sul Controllo della JE
SUB ;... # Sono Dipendenti sul Controllo della JE
JMP fine2
fine1:
DIV ;... # È dipendente sul controllo della JE a causa di JMP fine2
fine2:
MUL ;... # In maniera raffinata questa non è dipendente
Se non vogliamo implementare la “raffinatezza”, possiamo creare una dipendenza sul controllo nel momento in cui viene emessa una Jcond che genera uno stallo finché non si recupera il risultato.
3.3.4. Ottimizzazioni
Sono possibili varie ottimizzazioni, come il bypass, che collega il bus di uscita delle ALU direttamente con le stazioni di controllo.
Un’ulteriore ottimizzazione è la rimozione del campo C dai registri interni, possibile aggiungendo delle stazioni di controllo lo spazio per salvare anche il contenuto dei sorgenti, così da rendere i registri liberamente modificabili dopo che l’istruzione è stata smistata ad una stazione.
Noi non ci occuperemo di questi accorgimenti, ma andremo a cercare come minimizzare il numero di stalli.
Per quanto riguarda le dipendenze sui dati, sostanzialmente non eliminabili, possiamo banalmente mantenerle all’interno delle stazioni di prenotazione senza bloccare il passaggio di altre istruzioni che possono essere eseguite nel mentre che queste aspettano la risoluzione della dipendneza.
Vediamo quindi uno schema delle dipendenze date due istruzioni i e j con i eseguita prima di j:
È importante sottolineare che tutte le azioni che vedremo adesso non influenzano le uscite della Decode, ma lavorano su di esse.
Per quanto riguarda le dipendenze sui nomi, esse sono anche chiamate dipendenze fittizie, questo perché se andiamo a sovrascrivere il contenuto di un registro è perché adesso lo vogliamo utilizzare per fare altro.
Possiamo quindi risolverle in questo modo:
- Antidipendenze: è sufficiente cambiare il registro
dstdij. - Dipendenze in uscita: cerchiamo per ogni scrittura un registro non utilizzato da nessun’altro.
Per riuscire a implementare questa ottimizzazione, chiamata riscrittura sui registri, dobbiamo ovviamente poi continuare a modificare questi registri per tutte le operazioni successive.
Un modo per semplificare questo passaggio è inserire, prima degli $n$ registri fisici Fi, una tabella contentente $m$ registri logici Ri che punteranno ai registri fisici non in uso.
In questa nuova architettura, le istruzioni tradotte dalla decode faranno riferimento ai registri logici.
L’emissione si preoccuperà quindi anche di tradurli in registri fisici Fi con l’accortezza che:
Il
dstdi una operazione deve sempre essere un registro fisico attualmente non puntato da nessun altro e non utilizzato dallaALU(W == 0 && Count == 0).
Vediamo quindi una possibile traduzione da logico a fisico:
ADD R1, R2, R3
SUB R4, R5, R2
\(\begin{CD} @VVV \end{CD}\)
ADD F1, F2, F6
SUB F4, F5, F7
Lo stato dei registri al termine delle due istruzioni sarà quindi quello sulla destra.
3.3.5. Esecuzione speculativa
Per quanto riguarda le dipendenze sul controllo anche qui, come per la pipeline, continuiamo a esaminare le informazioni come se il flusso dei dati fosse corretto.
Infatti la Fetch & Decode ha continuato a prelevare istruzioni dal punto indicato nel BTB, supponendo di aver effettuato una predizione corretta.
In questo caso la nostra architettura andrà a eseguire queste istruzioni predette prima di sapere se debbano o meno essere eseguite. Questa tecnica si chiama Speculazione.
Per un’implementazione corretta della specuazione è necessaria una nuova struttura dati chiamata ReOrder Buffer ROB. Questa struttura dati è una coda che ricostruisce l’ordine di emissione delle istruzioni.
Al suo interno ha un bit T che, se settato, indica che l’operazione associata è terminata.
In questa nuova architettura, le istruzioni vanno a scrivere i risultati nei registri solo dopo che sono state ritirate dal ROB.
Il trucco è che il ROB, in quanto coda, può solo effettuare prelievi dalla testa.
Adesso, quando terminiamo un’istruzione di Jcond e ne conosciamo l’esito, setteremo il suo bit T e la estraemo. Successivamente, valutandone l’esito:
- Se si effettua dove ci aspettiamo continuiamo a prelevare dal
ROB - Se abbiamo sbagliato allora svuotiamo il
ROB.
Finché le istruzioni del ROB non sono prelevate non abbiamo infatti effetti sui registri veri e propri, perciò possiamo tranquillamente eseguire codice che non siamo sicuri vada eseguito.
Il fatto che le modifiche sui registri non si manifestino immediatamente al completamento dell’esecuzione dell’ALU, comporta però che le stazioni di prenotazione, qual’ora vogliano prelevare un valore da un registro, non lo trovino aggiornato dal valore desiderato, che si trova ancora bloccato nella coda ROB.
Dobbiamo quindi modificare il modo in cui le stazioni di prenotazione prelevano i valori, introducendo un meccanismo di prelievo dal ROB.
Modifichiamo quindi gli indirizzi logici, in modo che invece di avere un solo indirizzo logico per ogni registro, ne conserviamo adesso due:
- Nel primo inseriamo l’informazione certa, quella che siamo sicuri vada lì ottenuta dall’estrazione dal
ROB - Nel secondo inseriamo invece l’informazione speculativa derivata dalle
ALUe potenzialmente annullabile con l’annullamento delROB
L’esecutore, nella traduzione degli indirizzi logici in fisici per i sorgenti, utilizzerà il contenuto dei registri speculativi.
Il registro dst verrà sempre tradotto in un nuovo registro non utilizzato per quello che abbiamo detto prima.
Quando la ALU termina, scrive quindi l’esito dell’operazione nel registro logico speculativo e setta il bit T della ROB.
Quando effettuiamo il prelievo dal ROB il valore speculativo di quell’operazione diventa non speculativo.
In questo modo, quando svuotiamo il ROB nel caso delle Jcond che non hanno l’esito atteso, è sufficente copiare i valori non speculativi nei registri speculativi.
Così facendo, alla prossima operazione, prelevando dal registro non speculativo, non avremo effetti collaterali poiché quelli salvati sono valori certi.
In questa architettura l’esecuzione va in attesa solo per via di limiti fisici.
Per migliorare le prestazioni è infatti sufficente aumentare i parametri fisici: le dimensioni del ROB, il numero di ALU e stazioni di controllo, il numero di registri, …
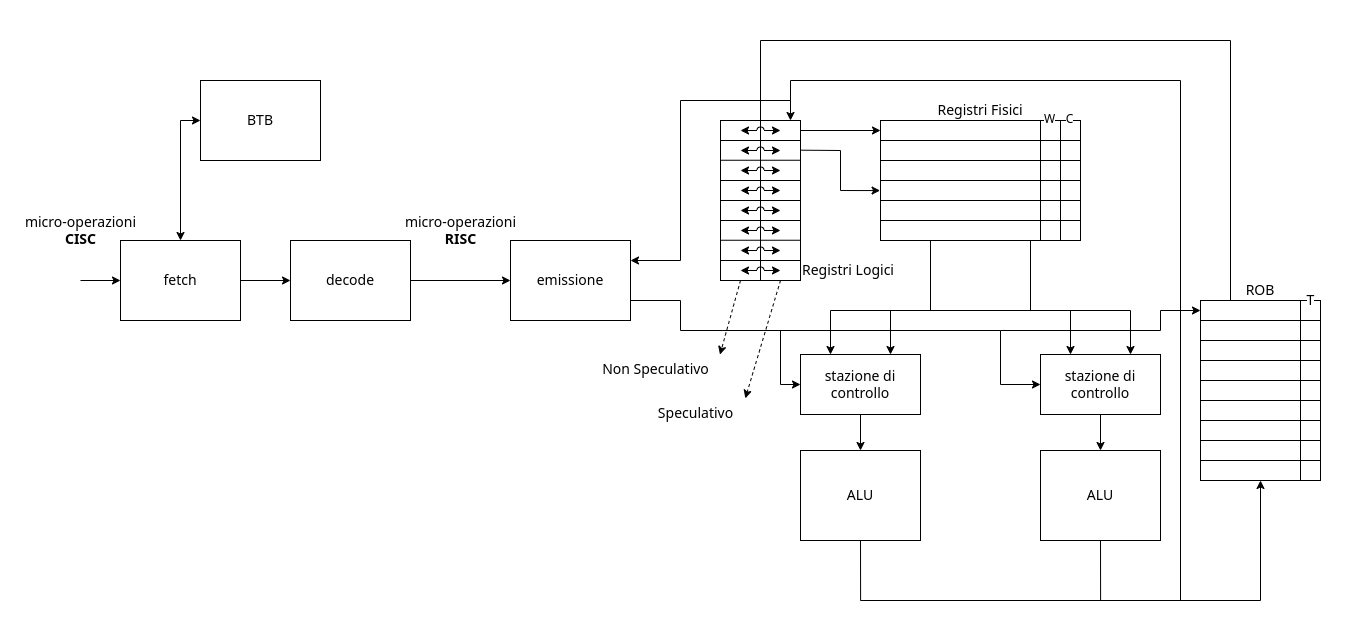
3.4. Istuzioni di LD e ST
Le istruzioni di LD e ST sono più complicate delle istruzioni viste fin’ora.
Come prima cosa, la ST effettua modifiche in memoria. Perciò, se dovesse essere eseguita speculativamente dovremmo trovare un modo per poter effettuare il rollback di queste scritture in memoria.
Questo si ottiene inserendo uno Store Buffer, una coda nella quale effettuiamo le scritture/letture durante l’esecuzione speculativa, senza quindi accedere direttamente in memoria.
Copieremo i dati in memoria solamente quando l’istruzione verrà recuperata dal ROB.
Per le letture, questa operazione si chiama Store Buffer Forwarding. Permettiamo infatti alla ALU di eseguire l’operazione, ma prima di andare a recuperare i dati dalla memoria, controlliamo eventuali hit all’interno dello Store Buffer.
Il problema principale con questi meccanismi è che non possiamo vedere direttamente lo stato dell’istruzione.
Le istruzione LD e ST contengono indirizzi del tipo offset(base), calcolati solamente quando le istruzioni vengono valutate.
Dobbiamo quindi prestare attenzione alla loro esecuzione speculativa, poiché potrebbe portare ad accessi in zone di memoria non accedibili, generando eccezioni.
Vediamo un’esempio:
CMP $1000, %rbx
JAE fine
MOV off(%rbx), %rax
fine:
In questo codice propriamente scritto, controlliamo prima di essere in un range minore di $1000 e solo in quel caso effettuiamo la MOV.
Se l’BTB, quando incontra la JAE fine, specula di non saltare, rischiamo di causare page fault qualora %rbx fosse stato maggiore di $1000 e non avessimo i permessi di accesso necessari per gli indirizzi successivi a off+1000.
Per evitare quindi che si possa generare un fault in questi casi, quello che facciamo è dedicare un’ulteriore bit fault all’interno del ROB.
Adesso, l’eccezione verrà sollevata solamente quando l’istruzione con il bit settato viene prelevata.
Così facendo, nel momento in cui il processore si rende conto di aver sbagliato nella speculazione e svuota il ROB, non avremo alcun sollevamento di eccezioni non desiderate.
3.5. Interazione con la cache
Grazie ai processi di speculazione riusciamo inoltre a prevedere le hit/miss della cache, così da permetterci di prelevare il dato prima rispetto a quando sarebbe accaduto senza questi accorgimenti.
Anche se la cache comunicasse una miss, e dovessimo quindi attendere la RAM, la richiesta dei dati a quest’ultima avviene comunque prima.
Per ragioni in realtà non ben definite, i vari errori che avvengono durante la speculazione non vanno a ripulire gli effetti provocati sulla cache. Qual’ora avessimo eseguito speculativamente una lettura in memoria, questa salva la corrispondente porzione di memoria all’interno di una delle cacheline, e successivamente la trasmette al processore.
Se la lettura speculativa fosse annullata poiché ci rendiamo conto di aver speculato male una Jcond, puliamo i registri speculativi e il ROB, ma lasciamo inalterata la cacheline recuperata impropriamente.
Questo fatto è importante per quanto riguarda i problemi di sicurezza che questa mancanza comporta, come vediamo nel prossimo capitolo.
4. Problemi di Sicurezza della speculazione
Agli inizio di Gennaio 2018 è stato scoperto che la speculazione ha problemi di sicurezza insormontabili, questi problemi sono relativi all’annullamento delle azioni speculative.
È infatti possibile per chi attacca le macchine, bypassare i servizi di sicurezza hardware implementanti nel processore, riuscendo ad accedere liberamente alle informazioni proprio struttando i problemi di annullamento della speculazione.
I due problemi principali sono:
- Meltdown: sfrutta le misure di sicurezza hardware di permessi di accesso e mancati accorgimenti progettuali. Oggi è ampiamente risolto
- Spectre: sfrutta gli accorgimenti non vitali per il funzionamento della nostra architettura (indirizzi virtuali, cache, …) ed è intrinseco nell’idea stessa della speculazione.
Entrambi sfruttano la separazione tra lo stato architetturale e quello $\mu$-architetturale.
4.1. Meltdown
Come abbiamo detto alla fine del precedente capitolo, la LD recupera delle informazioni speculativamente dalla memoria, salvandole di conseguenza in cache.
Come abbiamo sottolineato, può accadere che si scopra che la LD non andava eseguita e si annullino le modifiche che aveva apportato, lasciando però la cache aggiornata con le informazioni prelevate.
Una cosa importante da dire prima di descrivere il problema è che, poiché la cache è molto più veloce della RAM, misurando il tempo di estrazione di un informazione possiamo capire se è stata recuperata adesso dalla _RAM_ o se si trovava già in cache.
Per produrre il problema proviamo ad accedere, dal nostro processo utente, ad un’indirizzo vietato, come un’indirizzo a livello sistema.
Quando l’operazione verrà estratta dal ROB, la nostra architettura invierà un segmentation fault annullando di fatto l’operazione e non permettendoci di accedere ai dati.
Tuttavia, il nostro processore adesso valuta le operazioni speculando, quindi, prima che venga sollevato il fault le istruzioni successive alla lettura saranno state eseguite sui dati proibiti senza problemi.
Il problema sfrutta proprio queste operazioni per permettere all’attaccante di poter recuperare i dati dall’indirizzo_vietato senza recuperarli direttamente, ma sfruttando proprio la cache:
; Svuoto la cache
XOR %rax, %rax
MOV indirizzo_vietato, %al ; questa operazione genera `segmentation fault`
; -------------------------------------------------------------------------
; questa sezione non dovrebbe essere eseguita dall'architettura
; che rileva che non abbiamo i privilegi di accesso
; tuttavia a causa della speculazione queste operazioni vengono eseguite
; ma sono annullate prima che possa accadere
SHL $12, %rax ; trasformo %al in un indice di cacheline ($12 per disattivare il prefetch, meccanismo non visto in questo corso ma presente)
MOV vettore(%rax), %rbx ; leggo dalla memoria l'indirizzo vettore[%rax], che verrà salvato alla cacheline n° %rax
; -------------------------------------------------------------------------
; intercetto il fault e proseguo da qui (con dei try{}catch{} o in altri modi)
; Controllo infine la cache
In Unix è infatti possibile intercettare il segmentation fault, permettendo quindi al programma di proseguire nonostante queste eccezioni.
Se quindi ci preoccupiamo di intercettarlo, per il continuo del programma sarà possibile accedere alla cache manipolata.
Sarà quindi sufficente scrivere una sezione di codice che controlla il tempo di estrazione delle informazioni di ogni indice del vettore.
Questo produrrà due valori diversi:
- Alto: se l’elemento
vettore[i]non era presente in cache e abbiamo dovuto recuperarlo dalla RAM - Basso: se l’elemento
vettore[i]era già presente in cache
Poiché ci siamo assicurati di svuotare la cache prima di eseguire questo codice di verifica, l’unica cacheline presente sarà proprio quella con indice %rax, dove %rax era proprio il contenuto dell’indirizzo_vietato.
Siamo così riusciti a prelevare il contenuto di un’indirizzo_vietato senza accedervi direttamente, sfuttando la speculazione.
Oggi questa vulnerabilità è stata risolta in diversi modi, ne citiamo due:
- Rimozione delle traduzioni univoche nella parte utente, che infatti oggi non sono più presenti.
- Riconoscere l’eccezione di protezione e terminare la speculazione da quel punto in poi.
Nei processori moderni comunque il Meltdown non esiste più.
4.2. Spectre
Spectre rappresenta tutta una serie di debolezze intrinseche al concetto stesso di speculazione, che si basano su una manipolazione del BTB.
Parte di questa famiglia di problemi addestra il BTB a sbagliare.
È infatti sufficiente utilizzare istruzioni codificate con gli stessi bit delle istruzioni di salto, per creare collisioni all’interno del BTB, generando di conseguenza falsi dati.
Il BTB, pur avendo una struttura molto simile a quelal di una cache, non verifica che l’indice ricavato dal dato in ingresso si riferisca proprio a quel dato e non ad uno a lui naturalmente allineato, cosa che invece fa la cache tramite la corrispondenza etichetta-indice.
Sfruttando questo mancato controllo, possiamo far prelevare al BTB dati che sovrascrivono sempre gli stessi indici, di fatto addestrandolo ad andare dove vuole l’utente.
In questo modo l’utente può costringere anche il codice privilegiato a speculare nel modo che vuole lui. Questo codice privilegiato produrrà di conseguenza degli effetti $\mu$-architetturali attraverso i quali sarà possibile ancora una volta per l’utente recuperare dati del kernel.
Per questi problemi non esiste ancora una soluzione efficace e univoca, ma una serie di accortezze che cercano di limitarne gli effetti.
Una di queste accortezze è stata quella di svuotare il BTB qual’ora entri il kernel, così che le traduzioni forzate vengano perse prima di poter essere eseguite.