1. Indice
2. Sincronizzazione dei Processi
Abbiamo visto quindi che abbiamo un sistema a processi paralleli.
Questi processi possono interagire in tre modi:
- Sincronizzazione Diretta o Esplicita (Cooperazione): quando due processi lavorano insieme per il raggiungimento di uno scopo comune
- Sincronizzazione Indiretta o Implicita (Competizione): quando due processi vogliono accedere alla stessa risorsa per scopi indipendenti. Questi problemi di dicono “impliciti” perché non sono scritte esplicitamente in nessun programma, ma avvengono per via della gestione delle risorse
- Time-Dependent error (Interferenza): quando l’esecuzione di un insieme di processi ne modifica i dati in maniera arbitraria producendo errori
Per lo studio della sincronizzazione faremo riferimento a due modelli:
A Memoria Comune
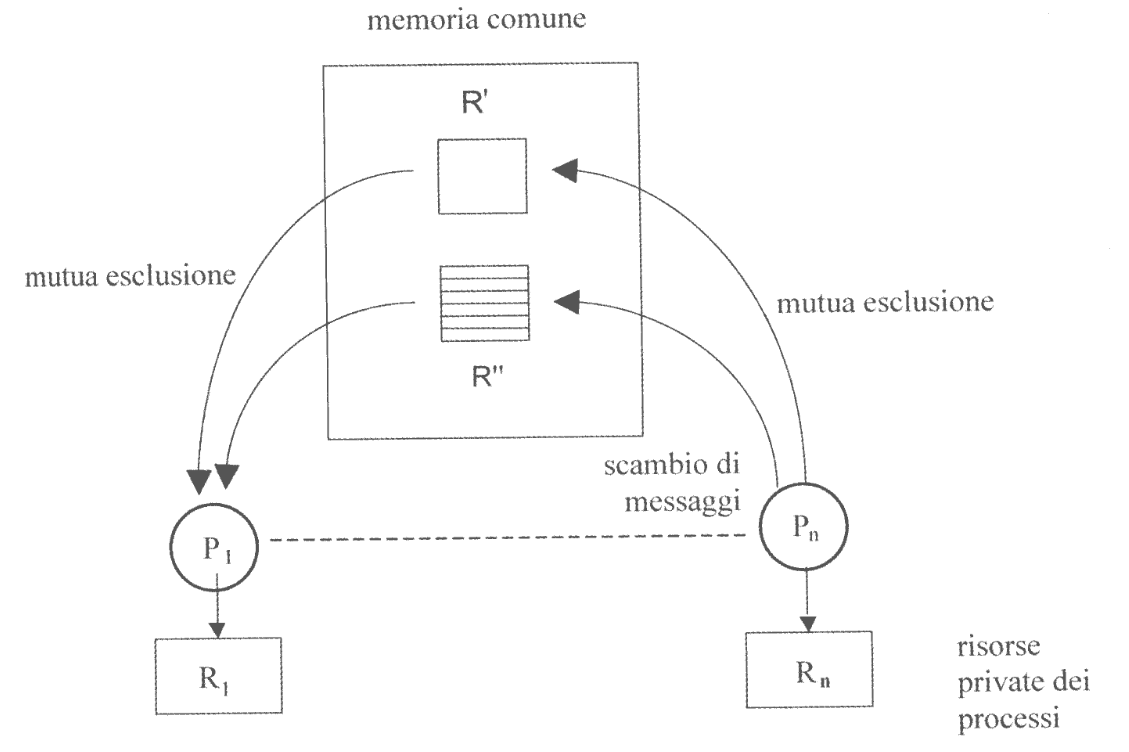
I processi, pur avendo spazio di indirizzamento privato, possono condividere una porzione di memoria comune.
L’accesso a queste risorse deve essere protetto da mutua esclusione.
A Memoria Locale
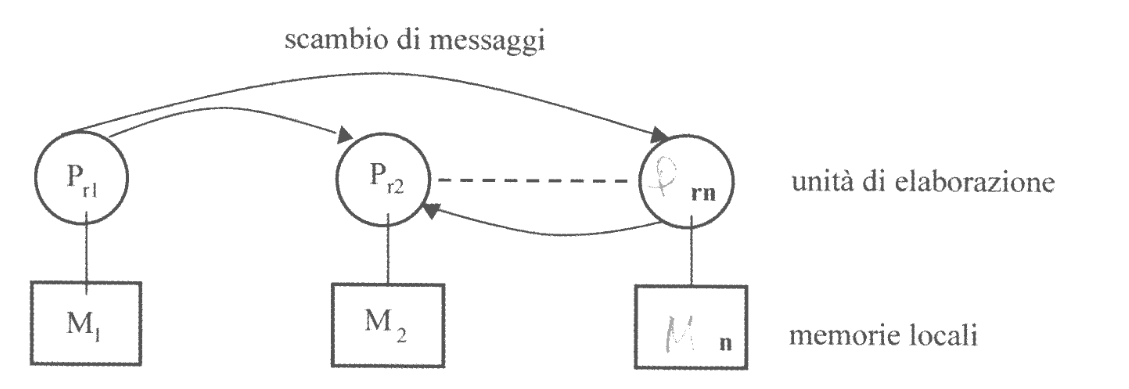
I processi hanno solo spazio di indirizzamento privato.
Tuttavia, è possibile accedere a porzioni private di memoria di altri processi attraverso scambio di messaggi. In questo modo i ci si deve adoperare per richiedere, copiare e inviare le porzioni di memoria desiderate.
L’accesso alle strutture nei messaggi deve quindi essere protetto sia da mutua esclusione che da sincronizzazione.
2.1. Processi a memoria condivisa
Per ripassare le condizioni di mutua esclusione e sincronizzazione si consiglia di consultare gli appunti di Calcolatori dedicati.
Tuttavia esistono altre implementazione degli stessi. Una prima implementazione diversa può essere quella di introdurre una nuova istruzione atomica TSL (test-and-set) che permette di leggere il valore di un bit e settarlo a 1.
Per fare queste due operazioni (lettura e scrittura) l’operazione mette un lock sul bus, così da avere atomicità delle operazioni.
In questo modo infatti solo una CPU ha accesso alla memoria, e non può avvenire che un’altra ne modifichi lo stato durante le operazioni di lettura e scrittura.
Introducendo questo supporto hardware, possiamo immaginare di strutturare due funzioni:
lock(x):
TSL registro, x
CMP registro, 0
JNE lock
RET
unlock(x):
MOVE 0, x
RET
In questo modo la verifica del lock sull’oggetto x è compiuta in modo atomico.
Il problema delle sezioni critiche, che richiedono atomicità, viene quindi risolto in questo modo:
// --- Thread A --- //
lock(x); // Prologo
// <sezione critica A>
unlock(x); // Epilogo
// --- Thread B --- //
lock(x); // Prologo
// <sezione critica B>
unlock(x); // Epilogo
Questa soluzione, per quanto efficace, pone però il processo che trova il lock in una busy-wait, nel quale si è a tutti gli effetti in un ciclo di attesa. Questo tendenzialmente non è un problema in quanto rientra nell’ordine dei nanosecondi (un paio di cicli di clock).
Inoltre, questo approccio funziona anche nei sistemi multiprocessore.
Torniamo però a parlare di semafori. Attraverso i semafori possiamo proteggere le sezioni critiche:
// --- Thread 1 --- //
wait(mutex); // Prologo
// <sezione critica A>
signal(mutex); // Epilogo
// --- Thread 2 --- //
wait(mutex); // Prologo
// <sezione critica B>
signal(mutex); // Epilogo
Questa soluzione non è però efficace per ambienti multiprocessori. Infatti l’atomicità è garantita dall’assenza di interruzioni solo sul singolo processore. Nel caso di più processori che lavorano in parallelo non abbiamo garanzie che entrambi non possano eseugire una wait sullo stesso semaforo.
È quindi necessario opporre alcune modifiche al sistema per poter continuare ad utilizzare i semafori in ambienti multiprocessori.
Una prima idea è quella di introdurre una atomicità hardware, implementendo dei lock hardware del bus qual’ora un processore stia eseguendo un’operazione di wait e signal.
In questo modo blocchiamo a livello hardware (attraverso i costrutti i lock e unlock che utilizzano l’operazoine TSL) tutti gli altri processori:
// Proteggo con lock-unlock
lock(x);
wait(mutex); // Prologo semaforo
unlock(x);
// <sezione critica A>
// Proteggo con lock-unlock
lock(x);
signal(mutex); // Epilogo semaforo
unlock(x);
2.2. Processi a Memoria Locale
Nel caso di processi a memoria distribuita (o locale), non possiamo più utilizzare semafori condivisi.
È quindi necessario implementare un meccanismo ICP (Inter-Process-Communication), ovvero dobbiamo creare dei canali tra processi, in modo di poter scambiare messaggi da un processo all’altro.

I processi assumono dei ruoli: mittente (send()) e destinatario (receive())
Lo strumento più elementare è quello basato su due primitive:
send(dest, message): permette di inviare un messaggio ad un destinatario. L’invio può essere di tre tipi:- Asincrono: dopo l’invio il mittente non si preoccupa del corretto arrivo del messaggio
- Sincrono: il mittente si blocca finché non è sicuro che il destinatario ha ottenuto correttamente il messaggio (ad esempio attende un
ACK) - A chiamata di procedura remota: è utilizzata quando il processo mittente chiede l’esecuzione di un servizio tramite procedura remota al destinatario. In questo caso i due processi oeprano su due processori collegati da una rete di comunicazione.
Questo tipo di
sendmette il processo mittente in attesa fin quando il servizio richiesto non è terminato e il risultato ricevuto.
receive(src, message): permette di ricevere un messaggio. È possibile specificare una determinata origine, ma non è obbligatorio. Può essere implementana in due modi:- Asincrona: consente la prosecuzione dell’esecuzione del processo anche in assenza di messaggi
- Sincrona: provoca la sospensione del processo che la esegue nel caso non ci fossero messaggi in attesa di essere serviti. All’arrivo del primo pessaggio il processo viene risvegliato
Un messaggio ha tipicamente il seguente formato:
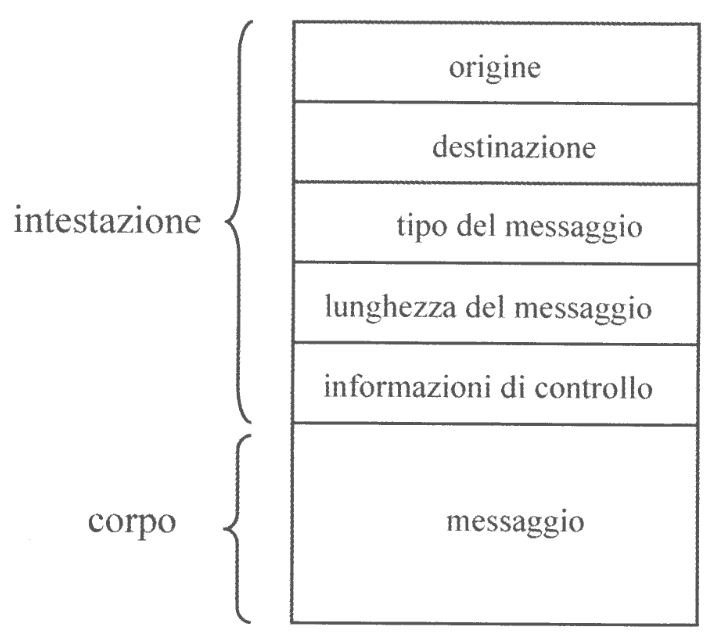
Possiamo quindi vedere un esempio di comunicazione diretta simmetrica:
Produttore
pid C = /*......*/;
main() {
msg M;
do{
produci(&M);
// ...
send(C, M);
} while (!fine);
}
Consumatore
pid P = /*.......*/;
main() {
msg M;
do{
receive(P, &M);
// ...
consuma(M);
} while (!fine);
}
Nel caso di comunicazione diretta asimmetrica:
Produttore
pid C = /*......*/;
main() {
msg M;
do{
produci(&M);
// ...
send(C, M);
} while (!fine);
}
Consumatore
main() {
msg M;
pid id;
do{
// attende un qualsiasi produttore
receive(&id, &M);
// ...
consuma(M);
} while (!fine);
}
2.3. Modello Client-Server
Nel caso di modelli client-server non abbiamo una comunicazione diretta attraverso un canale.
Si introduce una specie di mailbox per il server, detta porta o socket.
Possiamo immaginare i socket come dei processi che implementano una coda di messaggi.
In questo modello, le synchronized send si bloccano non finché il messaggio arriva al destinatario, ma finché il messaggio viene inserito nella mailbox.
Ogni processo server può quindi avere più socket diversi identificati da numero di porta diversi. Questo permette di dividere le informazioni e ottimizzare l’esecuzione.
Questa parte viene chiamata tipicamente Sistemi Operativi delle Reti Informatiche, e non la vedremo più di tanto in questo corso.
3. Classici Problemi di Sincronizzazione
Alcuni classici problemi che si verificano quando viene proposto un nuovo schema di sincronizzazione sono:
- Bounded-Buffer Problem
- Readers and Writers Problem
- Dining-Philosophers Problem
3.1. Bounded-Buffer Problem
Immaginiamo di avere un buffer con capacità massima di $N$ elementi (per comodità circolare) e due processi che lo condividono:
- Produttore: genera dati e li inserisce nel buffer
- Consumatore: preleva dati dal buffer e li elabora
Le sfide che il problema ci introduce sono tre:
- Overflow: il produttore non deve scrivere nel buffer se questo è pieno
- Underflow: il consumatore non deve leggere il buffer se questo è vuoto
- Mutua Esclusione: il produttore e il consumatre non devono mai manipolare i puntatori del buffer o una stessa cella di memoria nello stesso istante.
La soluzione classica a questo problema prevede tre semafori:
buf = sem_ini(N): indica il numero di buffer vuoti, permette di risolvere il problema dell’overflowmsg = sem_ini(0): indica il numero di buffer pieni, permette di risolvere il problema dell’underflowmutex = sem_ini(1): permette di risolvere il problema della mutua esclusione
Un esempio di processo produttore:
do{
wait(buf);
wait(mutex);
// add the item
signal(mutex);
signal(msg);
} while (true);
Un esempio di processo consumatore:
do{
wait(msg);
wait(mutex);
// remove item
signal(mutex);
signal(buf);
} while (true);
3.2. Readers and Writers Problem
Abbiamo un set di dati condivisi tra più processi concorrenti, che si dividono in:
- Lettori: possono solo leggere i dati senza poterli modificare
- Scrittori: possono sia leggere che scrivere
Se avessimo solamente processi lettori non avremmo problemi, in quanto nessuno può modificare i dati per gli altri.
Nel momento in cui introduciamo anche un solo Scrittore, questo potrebbe modificare i dati, rendendo i dati letti dai Lettori inconsistenti.
Esistono diverse politiche per la gestione di scrittori e lettori, la prima (e più semplice) è che:
Ci può essere al massimo uno scrittore alla volta. Se lo scrittore è presente non ci possono essere lettori.
Questa politica ci impone implementare due mutue esclusioni:
- Tra scrittori e scrittori: solo uno alla volta può accedere alla risorsa.
- Tra scrittori e lettori: se c’è uno scrittore nessun altro può accedere alla risorsa. Se ci sono lettori altri lettori nessuno scrittore può accedere.
Vediamo un primo esempio definendo un set di dati e:
- Un semaforo
wrt = 1: protegge gli accessi multipli tra più scrittori - Un contatore
readcount = 0 - Un semaforo
mutex = 1: protegge il contatore da stati inconsistenti
Un esempio di processo scrittore:
do{
// Verifico di essere l'unico scrittore
wait(wrt);
// scritture
signal(wrt);
} while (true);
Un esempio di processo lettore:
do{
// Proteggo `readcount` da stati inconsistenti
wait(mutex);
// Mi segno come lettore
readcount++;
// Se sono il primo lettore
if (readcount == 1) {
// Verifico che non ci siano scrittori
// E impedisco a eventuali scrittori futuri di accedere
wait(wrt);
}
signal(mutex);
// lettura
wait(mutex);
// Mi rimuovo tra i processi lettori
readcount--;
// Se non è rimasto più nessuno
if (readcount == 0) {
// Notifico ad eventuali scrittori futuri che possono accedere
signal(wrt);
}
signal(mutex);
} while (true);
In questa implementazione si possono mettere in attesa:
| Scrittori | Lettori | |
|---|---|---|
mutex |
$0$ | $N_L$* |
wrt |
$N_S$ | $1$ |
(In realtà il primo lettore non è propriamente in attesa su mutex. Può essere però in attesa su wrt mentre possiede il gettone del mutex)
Esistono diverse variazioni di questo problema:
- Nessun reader deve essere messo in attesa se lo scrittore ha il permesso di utilizzare l’oggetto condiviso
- Quando lo scrittore è pronto deve effettuare la scrittura il più velocemente possibile
Ambedue problemi possono provocare starvation, la cui soluzione porta a nuove variazioni.
All’interno di alcuni Sistemi Operativi il kernel fornisce dei reader-writer locks.
3.3. Dining-Philosophers Problem
È un problema che considera 5 filosofi p_i che passano tutta la loro vita a fare due cose:
- Thinking
- Eating
Questi filosofi si trovano attorno ad una tavola dove al centro si trova una ciotola di riso infinita.
I filosofi stanno prevalentemente nello stato thinking, ma ogni tanto vogliono passare nello stato eating.
Al tavolo però si trovano solamente 5 bacchette (chopsticks) c[i] distribuite in modo da essercene una tra ogni coppia di filosofi.
Quando vuole mangiare un filosofo segue le seguenti regole:
- Prende la bacchetta a destra
- Prende la bacchetta a sinistra
- Mangia
- Posa la bacchetta a sinistra
- Posa la bacchetta a destra

Possiamo pensare ad una prima soluzione basandoci su quello che abbiamo già visto:
sem chopstick[5] = 1;
proc philosopher{
int i;
do{
// hungry
wait(chopstick[i]);
wait(chopstick[(i+1) % 5]);
// eating
signal(chopstick[(i+1) % 5]);
signal(chopstick[i]);
// thinking
} while (true);
}
Questo algoritmo possiede un principale punto critico.
Immaginiamo che tutti i processi riescano a prendere possesso del primo chopstick[i] ma vengano interrotti “in cascata” (0 $\to \dots \to$5) prima di poter prendere il secondo.
Quando i processi avranno recuperato la prima bacchetta e proveranno a recuperare la seconda, entreranno tutti nello stato bloccato in cascata, generando un deadlock (blocco).
Per visualizzare graficamente l’accesso alle risorse possiamo utilizzare dei grafi, come quello sulla destra.
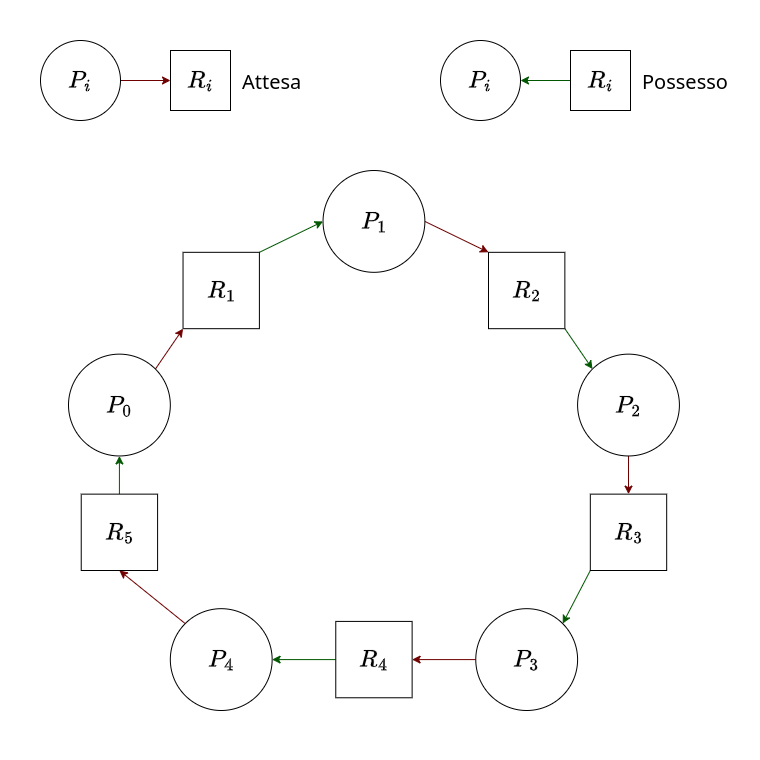
Tutti deadlock sono rappresentati da cicli. Non tutti i cicli rappresentano deadlock: solo quando le risorse coinvolte sono presenti in singola istanza
Possiamo prevenire il deadlock in tre modi:
- Deadlock Prevention: cambiare la logica del programma evitando le situazioni di deadlock
- Deadlock Avoidance: mantenere la logica del programma ma aggiungere dei controlli che evitano le situazioni di deadlock
- Deadlock Detection: implementare un algoritmo che cerca di capire se si è verificato un deadlock e lo slega
Vedremo meglio i deadlock nel capitolo successivo, adesso introduciamo invece una nuova astrazione per pensare ad una prima soluzione al problema dei filosofi.
3.4. Monitor
È un astrazione di alto livello che fornisce un meccanismo semplice e efficace per la sincronizzazione dei processi.
Possiamo rappresentarlo come un abstract data type, con variabili interne accessibili solo all’interno delle varie procedure.
Un monitor ha la seguente struttura:
monitor monitorName{
// shared variable declarations
procedure P1(/*...*/) {
// ...
}
// ...
procedure Pn(/*...*/) {
// ...
}
initialization_code(/*...*/) {
// ...
}
}
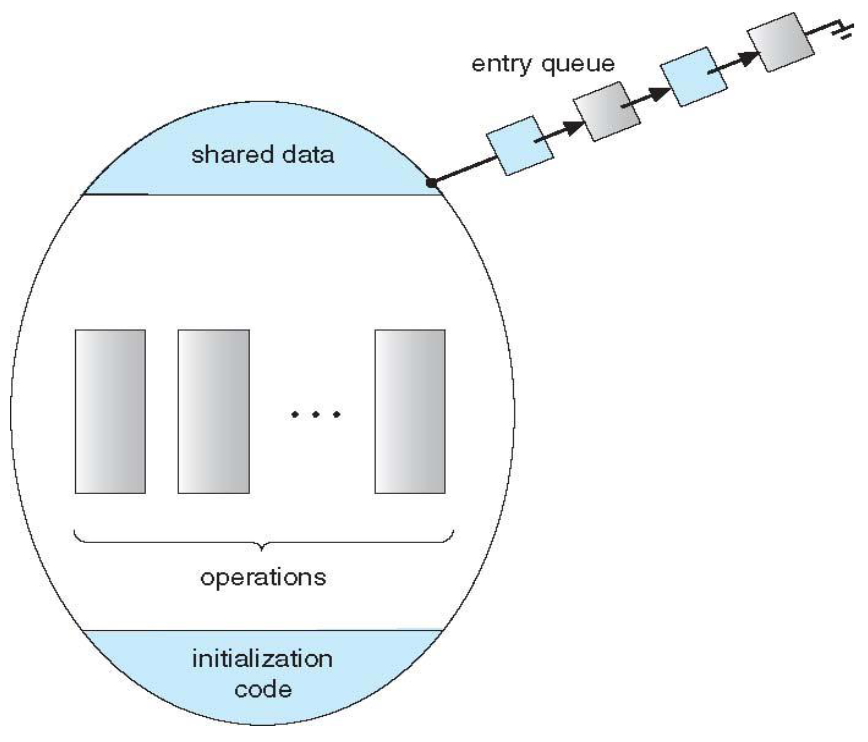
Per definizione un solo processo alla volta può essere attivo dentro al monitor, ciò rende le procedure mutualmente esclusive.
Se un processo sta infatti eseguendo una delle procedure del monitor, gli altri processi che vi vogliono accedere attendono in coda (entryQueue).
Questo meccanismo non è però ancora sufficientemente potente da poter risolvere alcuni schemi di sincronizzazione.
Per migliorarne l’efficacia si definiscono quindi all’interno del monitor delle variabili di condizionamento.
Ad ogni condition variable (condition x;) all’interno del monitor il sistema assegna due operazioni:
x.wait(): sospende l’operazione in attesa di unax.signal()x.signal(): riprende l’esecuzione di uno dei processi che ha chiamato lax.wait(). Se nessun processo aveva chiamato lax.wait()non ha alcun effetto.
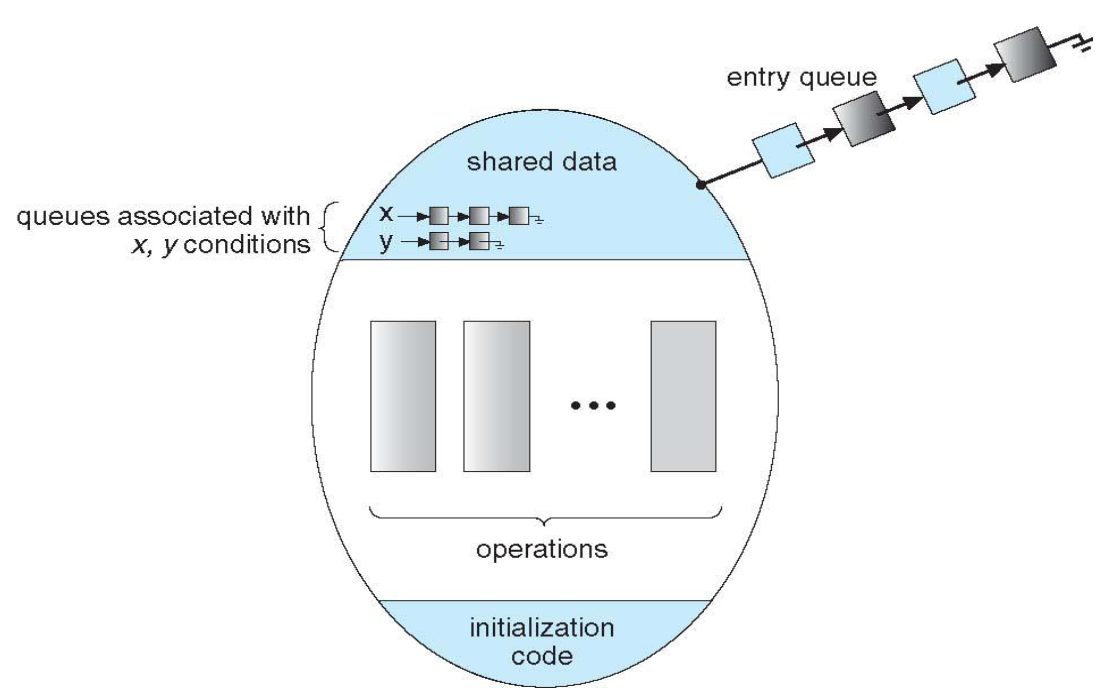
L’introduzione di queste condition variable comporta alcune scelte progettuali da fare. Ad esempio, se P invoca la x.signal(), mentre c’era Q in x.wait(), quale dei due processi dovrà riprendere prima?
Abbiamo due opzioni possibili:
- Signal and wait: facciamo riprendere
Qdandogli la precedenza suPanche se questo era in esecuzione. - Signal and continue: facciamo proseguire
P, mettendo in attesa della mutua esclusioneQ
Ambedue le opzioni hanno dei pro e dei contro, e sta all’implementatore scegliere quale delle due opzioni selezionare.
I monitor sono nativamente implementati in diversi linguaggi di programmazione, come C# e Java.
3.4.1. Soluzione al Dining Philosophers Problem
Vediamo quindi un implementazione della soluzione al problema sfuttando proprio i monitor:
monitor DiningPhilosophers{
enum {THINKING, HUNGRY, EATING} state[5];
condition self[5];
void pickup(int i) {
state[i] = HUNGRY;
test(i);
if (state[i] != EATING)
self[i].wait();
}
void putdown(int i) {
state[i] = THINKING;
test((i-1) % 5);
test((i+1) % 5);
}
void test(int i) {
if ( (state[(i-1) % 5] != EATING) &&
(state[i] == HUNGRY) &&
(state[(i+1) % 5] != EATING)) {
state[i] = EATING;
self[i].signal();
}
}
initialization_code() {
for (int i = 0; i < 5; ++i) {
state[i] = THINKING;
}
}
}
Ogni processo i utilizzera il monitor in quest’ordine:
DiningPhilosophers.pickup(i);
// EAT
DiningPhilosophers.putdown(i);
Questo metodo, che non si basa direttamente sul possesso delle bacchette, ma piuttosto sul fatto che:
- Se i miei vicini sono
THINKINGio posso mangiare - Se almeno uno dei miei vicini è
EATINGpasso allo statoHUNGRYe mi metto in attesa, in quanto prima o poi restituirà la bacchetta che mi serve (questo potrebbe provocare starvation, in quanto basta che i due vicini siano sempreEATINGper evitare che lo possa diventare) - Se entrambi i miei vicini sono
HUNGRYsignifica che io possono mangiare
L’ultimo di questi casi avviene proprio perché quando qualcuno è HUNGRY non prende nessuna bacchetta finché non le può prendere entrambe.
3.4.2. Implementazione dei monitor con i semafori
In C++ non sono forniti nativamente i monitor, però possiamo implementarli tramite l’utilizzo dei semafori.
Per implementare un monitor signal and wait servono:
/**
* Semaforo di mutua esclusione sul monitor
*/
sem mutex = sem_ini(1);
/**
* Semaforo sul quale si mettono in attesa i processi
* che si sono sospesi all'interno del monitor
*/
sem next = sem_ini(0);
/**
* Indica il numero di processi in attesa sul semaforo `next`
*/
int next_count = 0;
Ogni procedura sarà quindi rimpiazzata con il seguente segmento di codice:
wait(mutex);
// corpo della procedura
if (next_count > 0)
signal(next);
else
signal(mutex);
Uno scheletro dell’implementazione delle varie condition variable è il seguente:
class condition{
sem x_sem = sem_ini(0);
int x_count = 0;
public void wait() {
x_count++;
if (next_count > 0)
signal(next);
else
signal(mutex);
wait(x_sem);
x_count--;
}
public void signal() {
if (x_count > 0) {
next_count++;
signal(x_sem);
wait(next);
next_count--;
}
}
}
Se più processi fossero in coda sulla stessa condizione x, dobbiamo decidere quale risvegliare alla chiamata x.signal().
Un algoritmo FCFS non è adeguato, in quanto può portare i processi a starvation.
Quello che quindi possiamo fare è implementare un costrutto di conditional-wait nella forma x.wait(c) dove c indica la priorità (dove 0 è la priorità massima, come se fosse il tempo). A questo punto gestiamo la coda secondo un ordine di priorità decrescente.
3.4.3. Monitor per una singola risorsa
Possiamo vedere l’implementazione di un monitor per un allocatore di risore:
monitor ResourceAllocator{
bool busy;
condition x;
void acquire(int time) {
while (busy) {
x.wait(time);
}
busy = true;
}
void release() {
busy = false;
x.signal();
}
intialization_code() {
busy = false;
}
}
3.5. Sincronizzazione Pthread
La libreria Pthreads API è una libreria indipendente dal sistema operativo.
Fornisce nativamente mutex locks e condition variables e, tramite estensioni, permette di includere r/w locks e spinlocks.
4. Deadlock
La definizione di deadlock è la seguente:
Si verifica deadlock quando si ha una serie di processi bloccati dove ogni processo trattiene una risorsa e ne richiede un’altra già trattenuta da un’altro
Un esempio semplice che ci può aiutare a capire cos’è un deadlock è quando un sistema ha due hard disks e due processi dove:
P1utilizza il disco 1P2utilizza il disco 2
Immaginiamo poi che P1 richieda il disco 2 e P2 richieda il disco 1, ecco generato un deadlock.
Recuperanodo l’esempio del problema dei cinque filosofi, rappresentiamo le azioni con due semafori:
sem A = sem_ini(1);
sem B = sem_ini(1);
// --- Processo 0 --- //
wait(A);
wait(B);
// --- Processo 1 --- //
wait(B);
wait(A);
Se il processo 0 venisse interrotto dopo wait(A) ma prima di eseguire wait(B), il processo 1 farebbe la wait(B) generando di fatto il deadlock poiché da quel punto in qualsiasi istruzione wait compete per risorse già bloccate e non ancora rilasciate.
Abbiamo già detto che esistono diversi modi per affrontare il problema del deadlock:
- Deadlock Prevention: consiste nel cambiare la logica del programma al fine di evitare le situazioni di deadlock
- Deadlock Avoidance: consiste nel mantenere la logica del programma ma aggiungere dei controlli che evitano le situazioni di deadlock
- Deadlock Detection: consiste nel implementare un algoritmo che cerca di capire se si è verificato un deadlock e slegarlo
4.1. Condizioni di Deadlock
Per avere deadlock sono necessarie quattro condizioni che si verificano simultaneamente
- Mutua Esclusione: solo un processo per volta può usare una risorsa
- Hold and Wait: un processo che trattiene almeno una risorsa sta attendendo altre risorse attualmente trattenute da altri processi
- No preemption: una risorsa può essere rilasciata solo volontariamente dal processo che la sta trattenendo dopo che questo ha terminato il task
- Attesa Circolare: esiste un set <$P_0, P_1, …, P_n$> di processi in attesa dove
- $\forall i \in [0, n-1]$ il processo $P_i$ sta attendendo una risorsa trattenuta da $P_{i+1}$
- $P_n$ attende la risorsa trattenuta da $P_0$
4.2. Grafo di allocazione risorse
Avevamo già introdotto il concetto di grafo per identificare il deadlock, adesso formalizziamone la definizione:
Un grafo di allocazione è un insieme di vertici $V$ e edges $E$ dove:
- $V$ è partizionato in due gruppi:
- $P = {P_1, …, P_n}$ è il set che rappresenta i processi nel sistema
- $R = {R_1, …, R_m}$ è il set che rappresenta le risorse nel sistema
- $E$ rappresenta le relazioni tra i vertici:
- $P_i \to R_j$ rappresenta la richiesta della risorsa
- $R_j \to P_i$ rappresenta l’assegnazione della risorsa
Attraverso la rappresentazione grafica possiamo dire che:
- Se un grafo non contiene cicli, allora non è presente deadlock
- Se un grafo contiene un ciclo allora:
- Se tutte le risorse coinvolte hanno un istanza allora è presente deadlock
- Se almeno una risorsa coinvolta ha più di un istanza, allora è possibile ma non certa la possibilità di deadlock
Vediamo alcuni esempi:
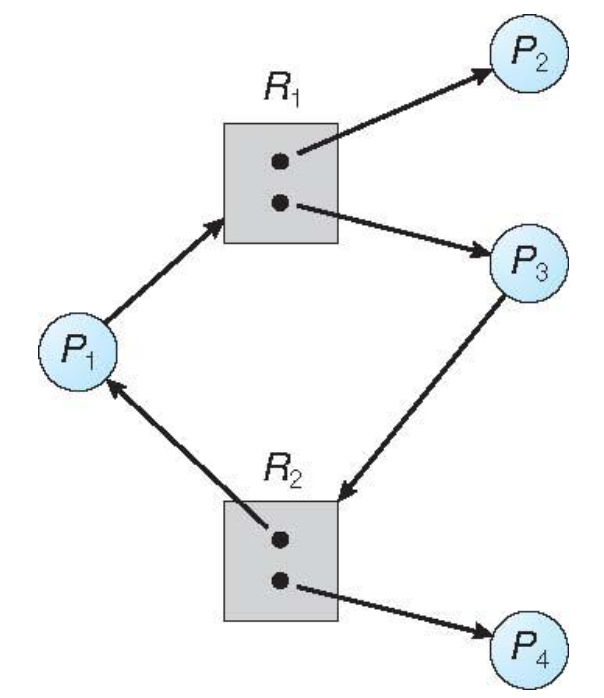
Grafo senza deadlock
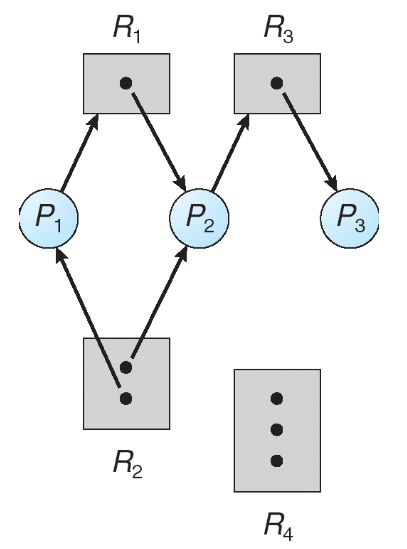
Grafo con deadlock
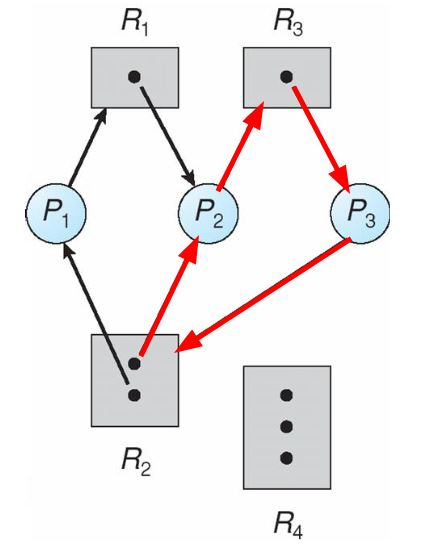
Grafo con cicli ma senza deadlock
4.3. Deadlock Prevention
Esistono diversi metodi che permettono di assicurasi che un sistema non entri mai in uno stato di deadlock.
Alcuni di questi metodi permettono comunque al sistema di entrare nello stato di deadlock, ma forniscono metodi per effettuare quello che si chiama deadlock recovery.
Nella realtà la maggior parte dei sistemi operativi, compresi quelli basati su UNIX, fanno la cosa più semplice: ignorano il problema e fanno finta che i deadlock non possano mai avvenire nel sistema, noi vedremo comunque dei metodi di prevenzione.
Nel caso di mutua esclusione un modo per prevenire i deadlock è utilizzarla solo ed esclusivamente per le risorse che ne hanno necessità, ovvero quelle non condivisibili.
Per ovviare ai deadlock della hold and wait dobbiamo garantire che quando un processo richiede una risorsa, non ne possegga già un altra. Possiamo quindi obbligare il processo a richiedere e allocare tutte le risorse prima che inizi l’esecuzione. Oppure potremmo permettergli di richiedere le risorse solo quando non ne ha altre. È importante tenere a mente che il fatto stesso di utilizzare poche risorse comporta un’alta probabilità di starvartion.
Nel caso di sistemi non preemptivi se un processo che ha il possesso di una risorsa ne richiede un altra che non può essergli immediatamente allocata, allora tutte le risorse che trattiene vengolno rilasciate. Le risorse vengono quindi tutte messe in una lista sul quale il processo andrà in attesa. Il processo verrà ripreso solo quando potrà recuperare le vecchie risorse e quelle nuove.
Per ovviare invece all’attesa circolare si impone un ordinamento totale di tutte le risorse, e si richiede che ogni processo richieda una risorsa in un ordine crescente di enumerazione. In altre parole se $P$ possiede la risorsa $R_k$, non può chiedere alcuna risorsa $R_{k-i}$ con $i = 1, 2, …, k$.
4.4. Deadlock Avoidance
Le tecniche per poter evitare i deadlock, dette tecniche di deadlock avoidance, richiede che il sistema abbia accesso ad alcune informazioni aggiuntive a priori.
Il modello più semplice e più efficace è quello nel quale ogni processo dichiara il numero massimo di risorse di ogni tipo che può necessitare.
Un altra opzione è l’algoritmo di deadlock-avoidance che esamina dinamicamente lo stato dell’allocazione delle risorse affinché non si abbia mai una condizione di attesa circolare.
Lo stato dell’allocazione delle risorse è definito da:
- La somma delle risorse disponibili e di quelle già allocate
- La massima domanda di risorse del processo.
Questo comporta che quando un processo richiede una risorsa, il sistema debba decidere se l’allocazione di quella risorsa mantiene il sistema in uno stato sicuro.
Si dice stato sicuro:
Un sistema nel quale esiste una sequenza <$P_1, P_2,…,P_n$> di tutti i processi nel sistema tali che per ogni $P_i$ le risorse che $P_i$ può richiedere possono essere soddisfatte con:
- Le risorse attualmente disponibili
- Le risorse utilizzate da tutti i processi $P_j$ con $j < i$
Questo comporta che se le richieste di $P_i$ non fossero disponibili immediatamente, $P_i$ deve essere messo in attesa finché il processo che lo precede nella sequenza $P_{i-1}$ non è terminato. Quando $P_{i-1}$ sarà terminato, allora $P_i$ può ottenere le risorse richieste, eseguire e renderle nuovamente disponibili. Quando $P_i$ terminetà allora $P_{i+1}$ potrà ottenere le risorse a lui necessarie e così via…
Quando un sistema è nello stato sicuro allora non possono verificarsi deadlock. Se il sistema non fosse nello safe state allora è possibile avere deadlock. L’avoidance si occupa di garantire che il sistema non entri mai in uno stato unsafe
Nel caso di utilizzo di una risorsa in single instance è sufficiente utilizzare un grafo di allocazione risorse.
Nel caso invece di risorse in multiple instance si utilizza l’algoritmo del banchiere.
4.4.1. Resource-Allocation Graph
Definiamo claim edge una relazione $P_i \to R_j$ che indica che il processo $P_j$ possa richiedere la risorsa $R_j$, e lo indichiamo come una linea tretteggiata.
I claim edge si trasformano in archi di attesa con quando un processo richiede una risorsa, che a sua volta diventano archi di possesso quando la risorsa viene allocata al processo. Quando una risorsa viene rilasciata, un arco di possesso ritorna un claim edge.
La risorsa deve essere richiesta a priori dal sistema.
La regola diventa quindi la seguente:
Una richiesta può essere garantita solo se la conversione di un arco di attesa in un arco di possesso non risulta nella formazione di un ciclo nel grafo
4.4.2. Algoritmo del Banchiere
Permette la deadlock avoidance nel caso di risorse con multiple istanze.
Affinché l’algoritmo possa funzionare richiede che ogni processo dichiari a priori il massimo utilizzo di una risorsa che potrà effettuare.
L’algoritmo sfrutta infatti la possibilità di mettere in attesa un processo quando questo effettua una richiesta, e si basa sull’assunzione che quando un processo ottiene tutte le risorse, dovrà rilasciarle in un tempo finito.
Per spiegarlo immaginiamo di avere $n$ processi e $m$ risorse diverse.
Definiamo quindi le seguenti strutture dati:
available: un array di lunghezza $m$.available[j] = kindica che vi sono $k$ istanze disponibili della risorsa $R_j$max: una matrice $n\times m$.max[i][j] = kindica che il processo $P_i$ può richiedere al massimo $k$ istanze della risorsa $R_j$allocation: una matrice $n\times m$.allocation[i][j] = kindica che il processo $P_i$ possiede $k$ istanze di $R_j$need: una matrice $n\times m$.need[i][j] = kindica che $P_i$ potrebbe necessitare altre $k$ istanze di $R_j$ per completare il proprio taskrequest: una matrice $n\times m$.request[i][j] = kindica che $P_i$ ha richiesto $k$ istanze di $R_j$
La relazione tra queste variabili è la seguente: need[i,j] = max[i,j] - allocation[i][j].
Supponendo di avere queste funzioni di supporto:
int* copyArray(int* ar2) {
int* ar1 = new int[M];
for (int j = 0; j < M; ++j) {
ar1[j] = ar2[j];
}
return ar1;
}
bool* initAll(bool val) {
bool* ar = new bool[M];
for (int j = 0; j < M; ++j) {
ar[j] = val;
}
return ar;
}
bool compareRow(int* ar1, int* ar2) {
for (int j = 0; j < M; ++j) {
if (ar1[j] > ar2)
return false;
}
return true;
}
void sumByElement(int* ar1, int* ar2, bool minus) {
for (int j = 0; j < M; ++j) {
ar1[j] += ((minus)? -ar2[j] : ar2[j]);
}
}
L’algoritmo di verifica dello stato sicuro è qualcosa del genere:
bool isSafe() {
// step 1
int* work = copyArray(available);
bool* finish = initAll(false);
int i;
bool skipToFour;
do{
// step 2
i = 0;
skipToFour = true;
for (; i < N; ++i) {
if (!finish[i] && compareRow(need[i], work)) {
skipToFour = false;
break;
}
}
if (!skipToFour) {
// step 3
sumByElement(work, allocation[i], false);
finish[i] = true;
}
} while (!skipToFour)
for (int j = 0; j < M; ++j) {
if (!finish[j])
return false;
}
return true;
}
L’algoritmo di richiesta di una risorsa di un processo i diventa quindi:
void bankerAlgorithm(int i) {
if (!compareRow(request[i], need[i])) {
throw new Exception("Il processo ha richiesto più di quanto aveva detto avrebbe fatto");
}
if (compareRow(request[i], available)) {
// Almeno una delle risorse non è disponibile
wait();
}
while (true) {
sumByElement(available, request[i], true);
sumByElement(allocation[i], request[i], false);
sumByElement(need[i], request[i], true);
if (!isSafe()) {
// oggetto allocato
return;
}
// annullo l'operazione di allocazione e metto in attesa
sumByElement(available, request[i], false);
sumByElement(allocation[i], request[i], true);
sumByElement(need[i], request[i], false);
wait();
}
}
Facciamo un esempio.
Ipotizziamo 5 processi e tre risorse available[3] = {10, 5, 7}
Al tempo $t_0$ la situazione è la seguente:
| Processo | allocation |
max |
need |
|---|---|---|---|
| $P_0$ | [0, 1 ,0] |
[7, 5, 3] |
[7, 4, 3] |
| $P_1$ | [2, 0 ,0] |
[3, 2, 2] |
[1, 2, 2] |
| $P_2$ | [3, 0, 2] |
[9, 0, 2] |
[6, 0, 0] |
| $P_3$ | [2, 1, 1] |
[2, 2, 2] |
[0, 1, 1] |
| $P_4$ | [0, 0, 2] |
[4, 3, 3] |
[4, 3, 1] |
Al tempo $t_0$ available = {3, 3, 2}.
Eseguendo l’algoritmo possiamo constatare che la sequenza <$P_1, P_3, P_4, P_2, P_0$> soddisfa il criterio di sicurezza, quindi il sistema è in uno stato sicuro.
Se $P_1$ richiedesse {1, 0, 2} (richiesta garantibile in quanto {1, 0, 2} <= {3, 3, 2}) trasformerebbe lo stato totale in:
| Processo | allocation |
max |
need |
|---|---|---|---|
| $P_0$ | [0, 1 ,0] |
[7, 5, 3] |
[7, 4, 3] |
| $P_1$ | [3, 0 ,2] |
[3, 2, 2] |
[0, 2, 0] |
| $P_2$ | [3, 0, 2] |
[9, 0, 2] |
[6, 0, 0] |
| $P_3$ | [2, 1, 1] |
[2, 2, 2] |
[0, 1, 1] |
| $P_4$ | [0, 0, 2] |
[4, 3, 3] |
[4, 3, 1] |
Con available = {2, 3, 0}.
In questo stato, ad esempio, se $P_4$ richiedesse {3, 3, 0} la richiesta non sarebbe accettata, in quanto le risorse che richiede non sono disponibili. Questo comporta che $P_4$ andrà in attesa.
Allo stesso modo la richiesta da parte di $P_0$ di {0, 2, 0} non sarebbe accettata.
In questo caso è vero che le risorse sono disponibili, ma eseguendo l’algoritmo isSafe() sullo stato aggiornato, è immediato verificare che non esiste sequenza di algoritmi che permette di mantiene il safe state. Quindi anche $P_0$ andrà in attesa.
4.5. Dealock Detection
Un altra tecnica per gestire i deadlock è attraverso la deadlock detection.
Questa tecnica permette al sistema di entrare in deadlock, avendo però a disposizione un detection algorithm che permette di riscontrare il deadlock e annullarne gli effetti, secondo un recovery scheme.
A seconda delle istanze di ogni risorsa abbiamo due algoritmi diversi.
4.5.1. Istanza Singola
In caso di risorse ad istanza singola, si mantiene un wait-for graph dove ogni nodo rappresenta un processo, e la relazione $P_i \to P_j$ indica che $P_i$ è in attesa di $P_j$.
Periodicamente il nostro sistema chiamerà un algoritmo che cerca un ciclo nel grafo, poiché se esiste un ciclo allora esiste un deadlock. Questo algoritmo avrà complessità computazionale $O(n^2)$ dove $n$ sono il numero di vertici del grafo.
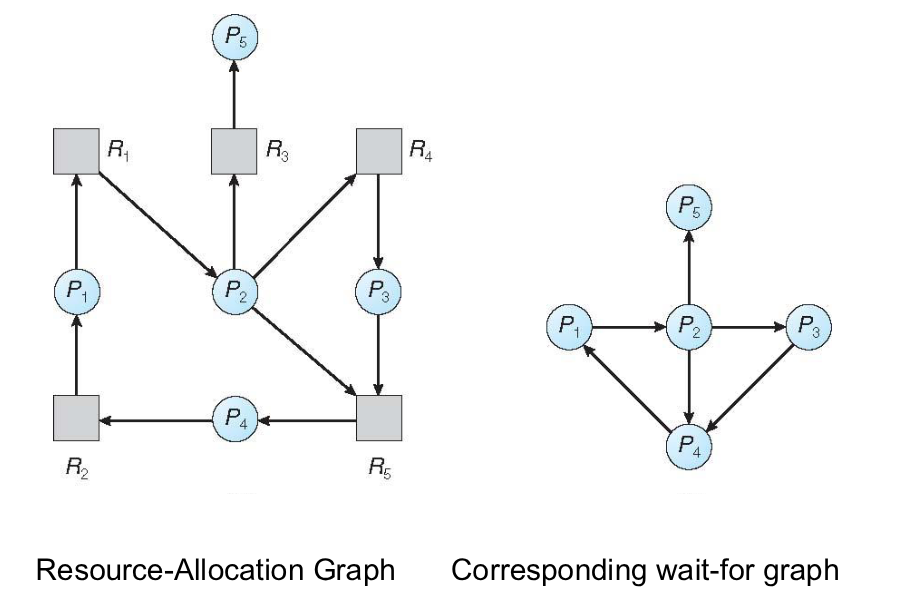
Sulla sinistra abbiamo il grafo dell’allocazione risorse, sulla destra il corrispondente grafo wait-for.
4.5.2. Istanze Multiple
In caso di risorse con istanze multiple introduciamo delle nuove variabili:
available: vettore di lunghezza $m$, indica il numero di istanze disponibili per ogni risorsaallocation: matrice di dimensioni $n \times m$, per ogni processo indica il numero di istanze attualmente allocate per ogni risorsa.request: matrice di dimensioni $n \times m$, indica per ogni risorsa il numero di risorse richieste per ogni processo. Serequest[i][j] = kindica che il processo $P_i$ sta richiedendo altrekistanze della risorsa $R_j$
Un esempio di detection algorithm (ipotizzando di avere le solite funzioni di supporto):
bool* isInDeadlock() {
bool* deadlock_array = initAll(false);
// step 1
int* work = copyArray(available);
bool* finish = initAll(true);
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (allocation[i][j] != 0) {
finish[i] = false;
break;
}
}
}
// step 2
int i;
bool skipToFour;
do{
i = 0;
skipToFour = true;
for (; i < n; ++i) {
if (!finish[i] && compareRow(request[i], work)) {
skipToFour = false;
break;
}
}
// step 3
if (!skipToFour) {
work = sumByElement(work, allocation[i], false);
finish[i] = true;
}
} while (!skipToFour);
// spet 4
for (int i = 0; i < n; ++i) {
deadlock_array[i] = !finish[i];
}
return deadlock_array;
}
Questo è un algoritmo di esempio, tuttavia qualsiasi algoritmo di deadlock detection è un algoritmo di complessità $O(m \times n^2)$.
Facciamo adesso un esempio per visualizzare meglio.
Ipotizziamo 5 processi e tre risorse available[3] = {7, 2, 6}
Al tempo $t_0$ la situazione è la seguente:
| Processo | allocation |
request |
|---|---|---|
| $P_0$ | [0, 1 ,0] |
[0, 0, 0] |
| $P_1$ | [2, 0 ,0] |
[2, 0, 2] |
| $P_2$ | [3, 0, 2] |
[0, 0, 0] |
| $P_3$ | [2, 1, 1] |
[1, 0, 0] |
| $P_4$ | [0, 0, 2] |
[0, 0, 2] |
Al tempo $t_0$ available = {0, 0, 0}.
Eseguendo l’algoritmo otteniamo che attraverso la sequenza <$P_0, P_2, P_3, P_1, P_4$> otteniamo che per tutti i processi finish[i] = true.
Immaginiamo però che $P_2$ effettui una nuova richiesta di risorsa:
| Processo | allocation |
request |
|---|---|---|
| $P_0$ | [0, 1 ,0] |
[0, 0, 0] |
| $P_1$ | [2, 0 ,0] |
[2, 0, 2] |
| $P_2$ | [3, 0, 2] |
[0, 0, 1] |
| $P_3$ | [2, 1, 1] |
[1, 0, 0] |
| $P_4$ | [0, 0, 2] |
[0, 0, 2] |
A questo punto, eseguendo l’algoritmo, il processo $P_0$ termina senza problemi, ma le risorse che rilascia non sono sufficienti a per soddisfare le richieste delgi altri.
L’algoritmo trova quindi un deadlock, in particolare gli indici ancora true (e quindi il ciclo) è nei procsssi $P_1, P_2, P_3, P_4$.
4.5.3. Utilizzo degli algoritmi
Questi algoritmi possono essere eseguiti in qualsiasi momento da parte del nostro sistema. Tuttavia, entrambi gli algoritmi producono notevole overhead. Una buona programmazione dovrebbe quindi eseguirlo il numero minimo di volte.
Infatti, nonostante abbia senso eseguirli ogni volta che un processo richiede una risorsa, in pratica non sarebbe sostenibile. Inolte, sapendo che la probabilità di deadlock è notevolmente bassa, rischiremmo di eseguire l’algoritmo quasi sempre “senza motivo”.
Un metodo per migliorare l’efficienza del sistema potrebbe però essere introdurre un monitor sulla CPU, in modo che l’algoritmo venga eseguito qual’ora l’utilizzo della CPU sia sotto una certa soglia, ad esempio il $30\%$.
Una via intermedia potrebbe inoltre essere quella di eseguire questi algoritmi periodicamente. Attraverso lo studio con dei testbench è possibile stimare il rischio di deadlock in relazione al tempo, così da poter eseguire l’algoritmo solo nei momenti dove è statisticamente probabile che il deadlock sia realmente avvenuto.
Un altra soluzione intermedia può essere quella di eseguire gli algoritmi ogni volta che una richiesta non può essere soddisfatta.
4.5.4. Recovery
Una volta rilevato il deadlock, dobbiamo decidere come fare per ripristinare il sistema.
Un metodo sicuramente funzionante è quello di abortire tutti i processi in deadlock. Questa soluzione, seppur semplice ed efficace, è estremamente drastica e non sempre strettamente necessaria.
Un metodo più “tranquillo” è quello di abortire un processo alla volta finché non riusciamo a eliminare il ciclo.
Esistono quindi tanti criteri attraverso i quali scegliere l’ordine con il quale abortire ogni processo:
- Priorità
- Tempo di computazione già trascorso in relazione al tempo di computazione totale
- Risorse che il processo ha utilizzato
- Risorse che il processo necessita per terminare
- Numero di processi da terminare
- Tipologia del processo (interactive, batch)
In generale dobbiamo selezionare una vittima in modo di minimizzare il costo.
Questa azione si chiama rollback, e permette di tornare al safe state, dal quale il processo abortito ripartirà da zero.
Questa scelta può provocare starvation, infatti potremmo scegliere come vittima sempre lo stesso processo, ma è facilmente evitabile, prendendo ad esempio in considerazione anche il numero di rollback già effettuati per un dato processo quando scegliamo la vittima.