1. Indice
- 1. Indice
- 2. Il File System
2. Il File System
Il file system è quella parte del sistema operativo che fornisce i meccanismi necessari per l’accesso e l’archiviazione delle informazioni nella memoria persistente.

La struttura del file system può essere rappresentata da un insieme di componenti organizate in vari livelli, come nell’immagine a destra.
2.1. Struttura Logica
Il livello più alto rappresenta la Struttura Logica, che presenta all’utente una visione astratta delle informazioni presenti sul disco. Questo livello prescinde dalle caratteristiche del dispositivo e dalle tecniche di allocazione e accesso alle informazioni adottate dal sistema.
Realizza i concetti astratti di:
- File: unità logica di memorizzazione
- Directory: insieme di file e directory (cartella)
- Partizione: insieme di file associato ad un particolare dispositivo fisico o a una sua porzione
Le caratteristiche di questi concetti sono del tutto indipendenti dalla natura e dal tipo di dispositivo utilizzato.
I processi vedono quindi la memoria secondaria attraverso questa struttura astratta.
2.1.1. File
Un file è:
Un insieme di informazioni rappresentate mediante insieme di record logici (bit, byte, linee, record, …)
Ogni file è caratterizzato da un insieme di attributi, ad esempio:
- Tipo: stabilisce l’appartenenza del file ad una classe (eseguibili, batch, testo, …)
- Indirizzo: puntatore/i a memoria secondaria
- Dimensione: numero di record contenuti nel file
- Data e ora: vi sono sia di creazione che di ultima modifica
Nei sistemi multiutente troviamo anche:
- Utente proprietario: in
UNIXsono l’UID(User-ID) e ilGID(Group-ID) - Protezione: diritti di accesso al file per gli utenti del sistema
2.1.2. Directory
Una directory è:
Un astrazione che cosente di raggruppare più file. Una directory può contenere più file, così come altre directory.
Una directory può quindi essere vista come un operatore di composizione di file e directory.
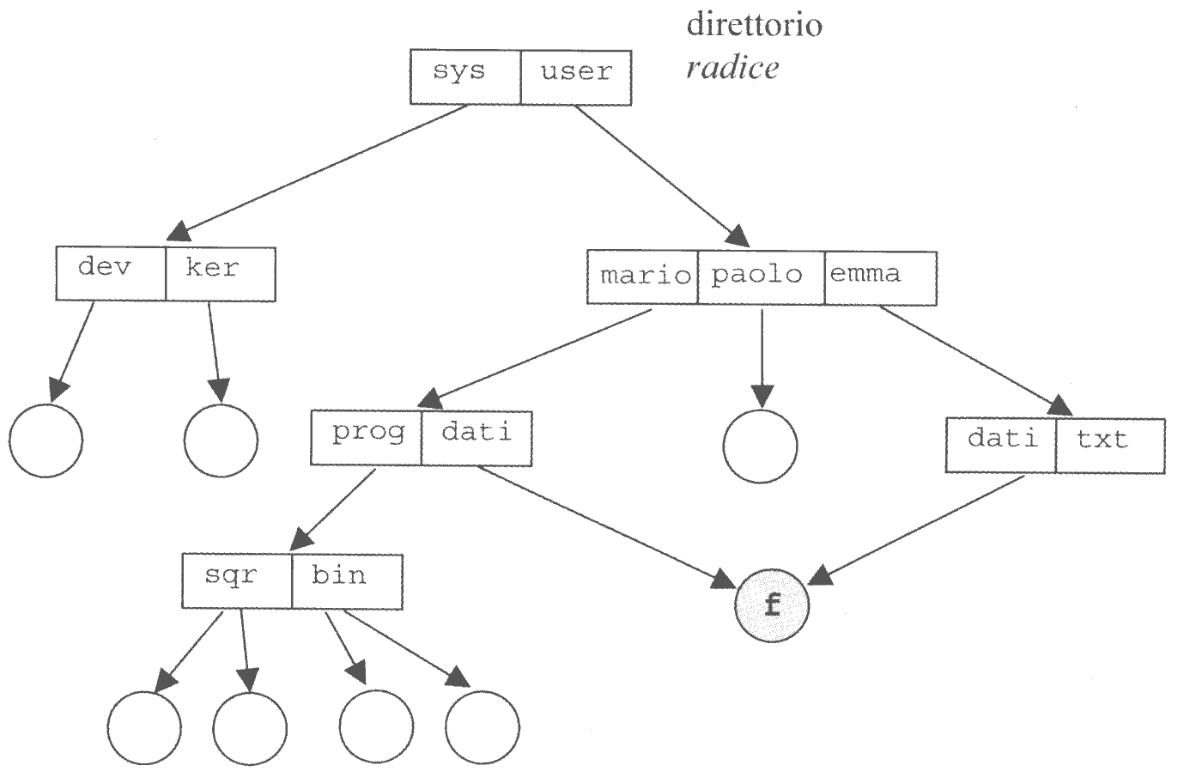
Nei sistemi operativi moderni file system sono rappresentati seguendo una struttura ad albero che segue le seguenti regole:
- Ogni file appartiene in una sola directory
- Ogni directory (tranne la
root) appartiene ad un altra directory
In alcuni sistemi, come in UNIX e Linux, viene permesso a più directory di condividere lo stesso file attraverso il linking.
Questa modifica cambia la struttura logica del file system rendendolo un grafo diretto aciclico.
2.1.3. Gestione del File System
Il sistema operativo realizza anche i meccanismi per la gestione del file system attraverso delle specifiche system call.
Le operazioni fondamentali per la gestione del file system sono:
- Creazione e cancellazione di directory: modificano la struttura logica del file system, aggiungendo/eliminando rami al grafo
- Aggiunta/Cancellazione di file
- Listing: permette di ispezionare il contenuto di uno o più directory
- Attraversamento della directory: permette la navigazione attraverso la struttura logica del file system.
Queste funzionalità sono disponibili per gli utenti sotto forma di comandi di shell.
2.2. Accesso al File System
Il secondo livello è detto di Accesso. Questo livello definisce e realizza i meccanismi mediante i quali è possibile eseguire operazioni sul contenuto dei file, generalmente lettura o scrittura.
In questo livello i file sono visti come un insieme di record logici, ovvero di unità di trasferimenti tra un processo e il file.
Il record logico è quindi caratterizzato da alcune proprietà come il tipo e la dimensione, in particolare in UNIX un record logico è 1 Byte.
Queste operazioni elementari di accesso ai file sono messe a disposizione dei processi attraverso opportune system-call, subordinatamente al soddisfacimento delle politiche di protezione. Queste politiche stabiliscono infatti chi e in che modo è abilitato ad accedere al file.
Questo livello utilizza quindi delle strutture dati che rappresentano concretamente i file, chiamate descrittori di file. I descrittori di file devono essere memorizzati in modo persistente mediante apposite strutture in memoria secondaria.
In UNIX questi descrittori sono gli i-node, conservati in i-list e indirizzati da i-number.
2.2.1. Rappresentazione delle Directory
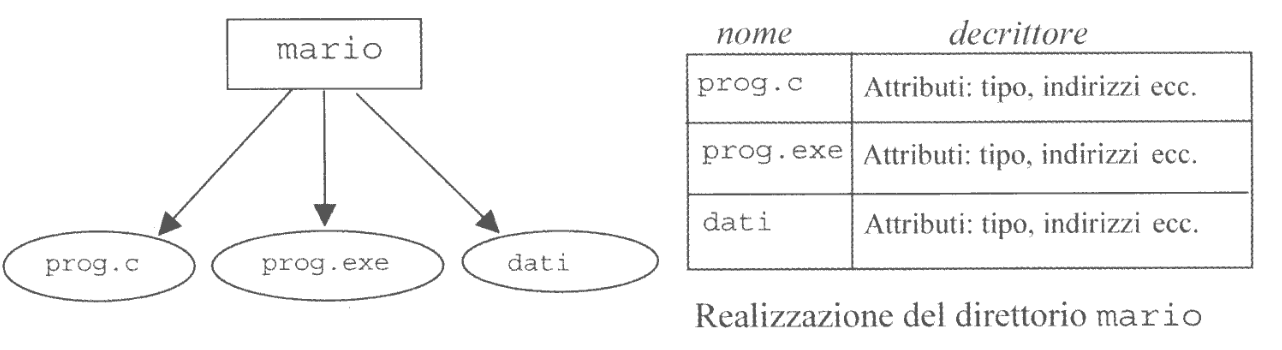
Poiché ogni file appartiene ad una directory, ogni directory mantiene il collegamento con i descrittori dei file contenuti in esso.
Ad esempio, in Windows si segue un approccio distribuito, dove la directory è una struttura dati di tipo tabellare che contiene i descritori dei file, come nell’immagine di seguito.
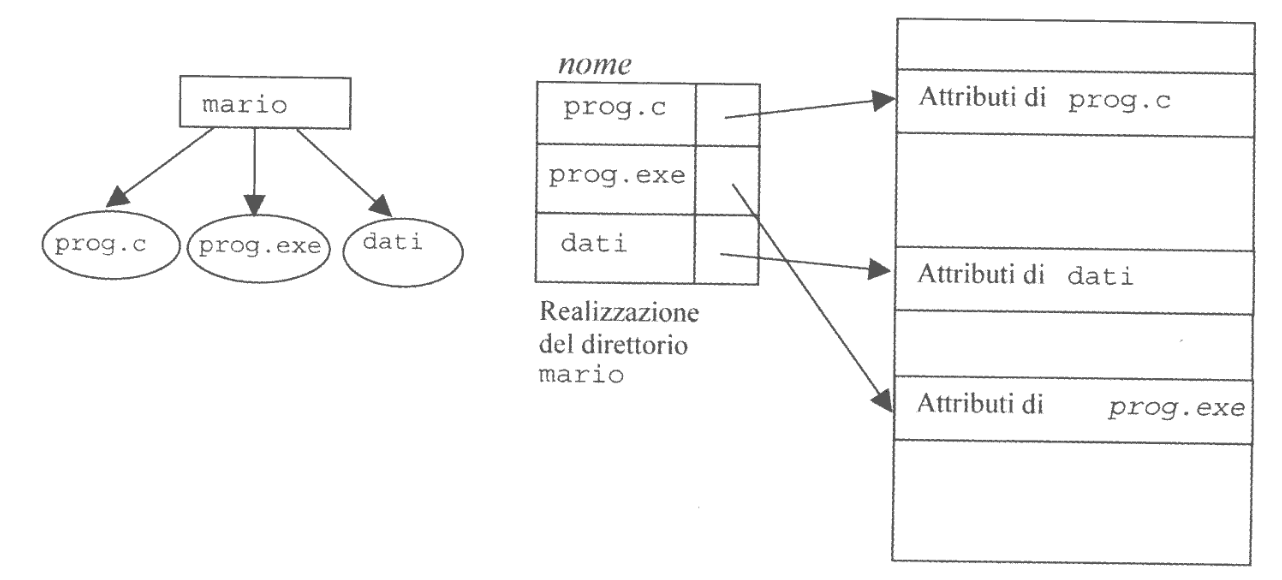
In UNIX invece si segue un approccio centralizzato, dove la tabella che rappresenta la directory contiene i riferimenti agli i-node (i-number), memorizzati nella i-list che si trovano in una struttura separata.
2.2.2. Accesso ai File
Abbiamo detto che è compito di questo livello implementare e mettere a disposizione l’accesso on-line ai file, che può essere:
- Lettura: leggere il contenuto di record logici dal file
- Scrittura: si divide in:
- Scrittura Pura: modifica il contenuto dei record all’interno di un file, diminuendo o mantenendo inalterato il numero di record del file
- Append: aggiunge ulteriori record al file senza modificare quelli già esistenti
Ogni operazione richiederebbe la localizzazione di informazioni su disco quali:
- Indirizzi dei record logici a cui accedere
- Gli altri attributi del file
- I record logici
Se dovessimo effettuare queste operazioni per ogni accesso introdurremmo un notevole overhead.
Per renderle efficienti invece i file system mantengono in memoria una struttura che registra i file attualmente in uso, detta tabella dei file aperti.
Per ogni file aperto sono conservate alcune informazioni, quali puntatore_a_file, posizione_su_disco, …
Si fa inoltre Memory Mapping dei file aperti, ovvero questi file vengono temporaneamente copiati (nella loro interezza o solo in alcune porzioni) nella RAM, così da consentirne un accesso più rapido.
È quindi necessario introdurre due nuove operazioni:
- Apertura: permette di introdurre un nuovo elemento nella tabella dei file aperti e eventualmente effettuare memory mapping del file
- Chiusura: salva il file in memoria secondara e elimina l’elemento corrispondente dalla tabella dei file aperti. Possono anche essere effettuate ulteriori operazioni che però dipendono dai singoli sistemi operativi.
2.2.3. Metodi di Accesso
L’accesso a un file più avvenire secondo varie modalità:
- Accesso Sequenziale
- Accesso Diretto
- Accesso a Indice
Poiche ogni metodo di accesso deve essere indipendente dal tipo di dispositivo utilizzato e dalla tecnica di allocazione dei blocchi in memoria, si presuppone implicitamente che i file abbiamo un organizzazione interna interpretata come sequenza di record logici numerati <$R_1, …, R_i, …, R_N$>.
2.2.3.1. Accesso Sequenzale
Nell’accesso sequenzale per accedere ad un particolare record $R_i$ è necessario accedere prima agli $(i-1)$ record che lo precedono nella sequenza.
Le primitive che permettono l’accesso seqeunziale seguono il modello generale:
/**
* @brief permette di leggere il prossimo record
* @param f nome del file
* @param V buffer dove copiare l'elemento letto
*/
readnext(f, &V);
/**
* @brief permette di scrivere sul prossimo record
* @param f nome del file
* @param V buffer da dove recuperare l'elemento da scrivere
*/
writenext(f, &V);
Ogni operazione di accesso posiziona il puntatore al file sull’elemento successivo a quello letto/scritto.
Questo tipo di accesso è quella che abbiamo nei sistemi UNIX.
2.2.3.2. Accesso diretto
Nell’accesso diretto è possibile accedere direttamente ad un particolare record logico $R_i$ mediante il suo indice.
Le primitive che permettono l’accesso diretto seguono il modello generale:
/**
* @brief permette di leggere il prossimo record
* @param f nome del file
* @param i indice del record da leggere
* @param V buffer dove copiare l'elemento letto
*/
readd(f, i, &V);
/**
* @brief permette di scrivere sul prossimo record
* @param f nome del file
* @param i indice del record sul quale scrivere
* @param V buffer da dove recuperare l'elemento da scrivere
*/
writed(f, i, &V);
2.2.3.3. Accesso a Indice
Ad ogni file viene associata una struttura dati contenente l’indice delle informazioni contenute nel file.
Le operazioni di accesso seguono quindi il modello generale:
/**
* @brief permette di leggere il prossimo record
* @param f nome del file
* @param key chiave che identifica l'elemento da leggere
* @param V buffer dove copiare l'elemento letto
*/
readk(f, key, &V);
/**
* @brief permette di scrivere sul prossimo record
* @param f nome del file
* @param key chiave che identifica l'elemento da scrivere
* @param V buffer da dove recuperare l'elemento da scrivere
*/
writek(f, key, &V);
Questo tipo di accesso presenta due svantaggi:
- Doppio accesso: per accedere al contenuto di un record, devo prima accedere al record del file indice dove è contenuta il riferimento al record logico
- Difficile scalabilità: per aggiungere un nuovo record è necessario aggiungerne due, raddoppiando la velocità di saturazione della memoria.
2.3. Organizzazione Fisica
Il terzo strato è il livello di Organizzazione Fisica, che ha come compito primario quello di allocare i record logici di ogni file nell’unità di memorizzazione secondaria.
In questo livello lo spazio disponibile per l’allocazione sul disco viene visto come un insieme di blocchi fisici.
Il blocco fisico è l’unità di allocazione e di trasferimento delle informazioni sul dispositivo, e gli è associata una posizione particolare sulla superficie del disco e una dimensione costante $D_b$, generalmente molto maggiore della dimensione di un record logico $D_r$.
In un singolo blocco possiamo contenere $N_b = \frac{D_b}{D_r}$ record logici.
Questo livello si occupa quindi di realizzare i metodi di allocazione, che stabiliscono il collegamento tra ogni file e l’insieme di blocchi fisici nel quale esso è allocato. Dobbiamo quindi utilizzare delle tecniche di allocazione che stabiliscano una corrispondenza tra i record logici contenuti in ogni file e l’insieme dei blocchi nei quali sono effettivamente memorizzati.
Partiamo dal dire che non tutta la memoria è utilizzata per l’allocazione dei file. Vedremo in seguito che una parte è riservata all’allocazione di alcune strutture dati per la descrizione della struttura logica del file system e per il supporto della gestione degli accessi ai file da parte dei processi.
2.3.1. Allocazione contigua
Questa tecnica mappa ogni file su un insieme di blocchi fisicamente contigui.
Per fare ciò è innanzitutto necessario calcolare il numero di blocchi necessari per salvare un file, e successivamente si procede a cercare una partizione di blocchi liberi abbastanza grande da contenere il file.
Questo tipo di allocazione ha diversi vantaggi, tra i quali:
- Semplice ricerca di un blocco: noto l’indirizzo del primo blocco del file $(B)$ e l’
IO pointerdi un dato record $(i)$, un dato blocco si trova in posizione: $B + \Big\lfloor\frac{i}{N_b}\Big\rfloor$ - Possibilità di accesso sequenzale e diretto allo stesso costo
Tuttavia ha anche molti svantaggi:
- Frammentazione Esterna: man mano che si riempie il disco si rimangono zone contigue sempre più piccole, rendendo necessario il compattamento
- Costo della ricerca dello spazio libero: è necessario analizzare tutto il disco finché non si trova uno spazio sufficientemente grande per conservare il file
- Crescita delle dimensioni del file: qualora il file aumentasse di dimensione potrebbe essere necessario rilocare l’intero file se non fossero disponibili ulteriori blocchi contigui liberi.
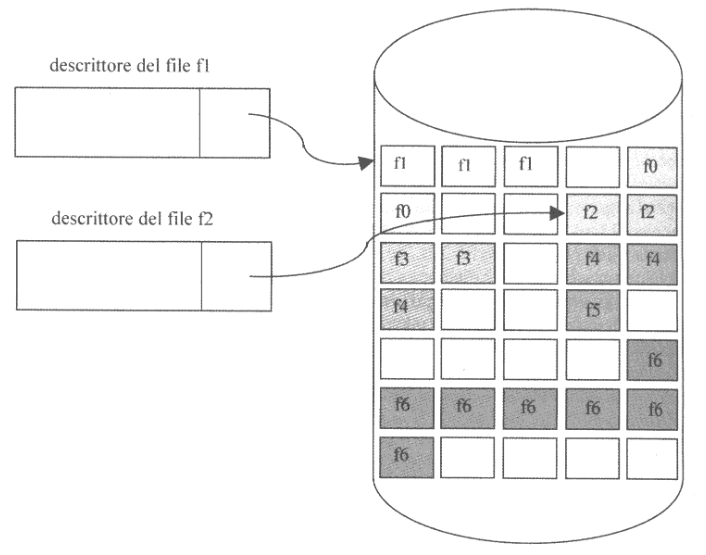
2.3.2. Allocazione a Lista Concatenata
Questa tecnica memorizza ogni file in un insieme di blocchi non contigui organizzati in una lista concatenata.
L’organizzazione è ancora di tipo sequenziale, ma stavolta blocchi successivi non devono necessariamente essere vicini.
Cio ci fornisce diversi vantaggi:
- Non soffre di frammentazione esterna
- Minor costo di allocazione: non è più necessario scorrere l’intero disco per allocare un file
- Accesso sequenzale a basso costo: dato il primo blocco abbiamo il puntatore al successivo
Vi sono ancora diversi svantaggi:
- Broken Links: se un blocco viene danneggiato, non solo perdiamo le informazioni che contiene ma anche le informazioni sul successivo, rendendo irraggiungibile il resto del file
- Overhead spaziale: dover salvare i puntatori diminuisce lo spazio effettivo utilizzabile
- Accesso diretto oneroso: in questo caso, per accedere all’$i$-esimo blocco sono necessari $\Big\lfloor\frac{i}{N_b}\Big\rfloor$ accessi al disco
- Costo della ricerca di un blocco
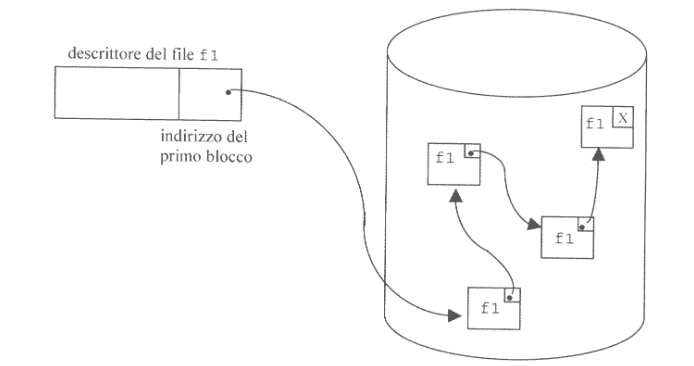
Per arginare il problema dei broken links è possibile realizzare una double-linked-list, andando a sacrificare un altra porzione del blocco per salvare un secondo puntatore che punta al blocco precedente.
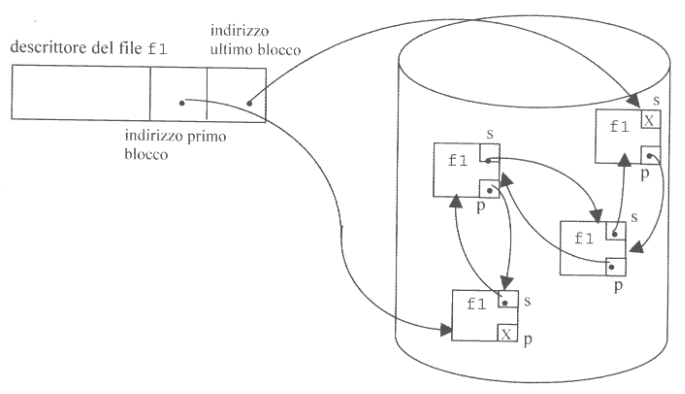
Nel caso del descrittore di file il primo puntatore punta al primo blocco, mentre il secondo punta all’ultimo blocco. Ciò aumenta ad uno la tolleranza ad errore.
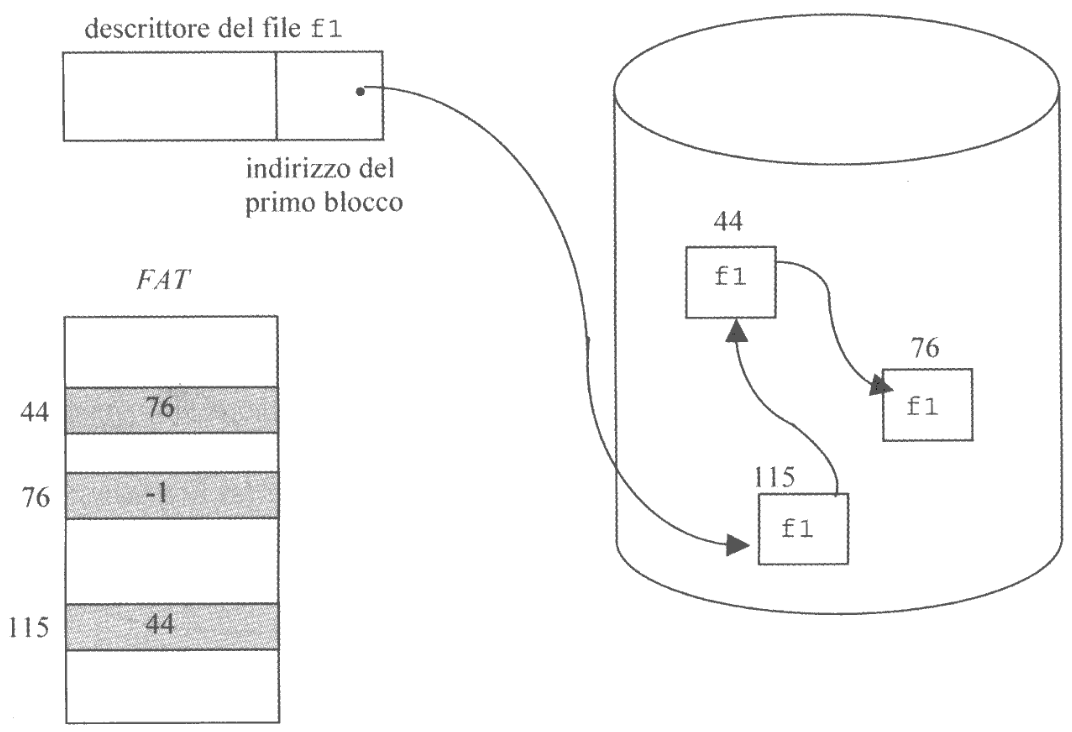
Alcuni sistemi operativi, ad esempio Windows, affronato il problema affiancando ad una allocazione basata su una linked-list una struttura dati nella quale viene descritta la mappa di allocazione di tutti i blocchi, detta File Allocation Table FAT.
Questa tabella viene memorizzata in una posizione predefinita della memoria, così da essere reperibile in qualsiasi momento.
Essa contiene tanti elementi quanti sono i blocchi del dispositivo, ed in ogniuno è presente un valore che indica:
- Se il blocco è libero
- L’indice dell’elemento della tabella che rappresenta il blocco successivo nella lista
In questo modo, anche in perdita di concatenamento è possibile effettuare il recupero del puntatore perso accedendo alla FAT.
La FAT può anche essere copiata in memoria centrale o in una cache, così da velocizzare notevolmente l’accesso diretto.
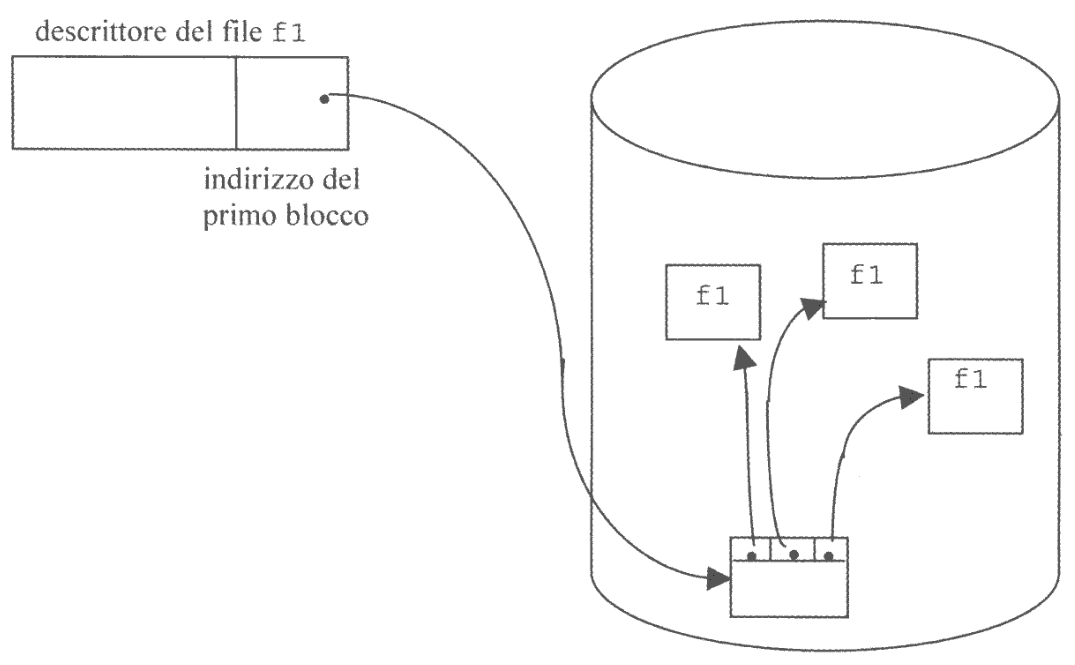
2.3.3. Allocazione a Indice
Questo tipo di allocazione si basa ancora sull’utilizzo di blocchi non contigui per l’allocazione di un file, ma in questo caso ad ogni file è associato un blocco indice in cui sono contenuti tutti gli indirizzi dei blocchi su cui è allocato il file.
Questo tipo di allocazione ha gli stessi vantaggi dell’allocazione tramite linked-list introducendo però anche:
- Possibilità di accesso diretto
- Maggiore velocità di accesso
Il grande svantaggio di questa tecnica è la non scalabilità, infatti se il file crescesse tanto da necessitare più blocchi di quelli indicizzabili da un unico blocco avremmo un problema.
In particolare dato un disco di capacità $C$, otteniamo quanti bit sono necessari per indicizzare tutti i blocchi di dimensione $D_b$: \(\quad I = \log{(\frac{C}{D_b})} \text{ indici}\)
Ciò significa che in un singolo blocco è possibile salvare al massimo $\frac{D_b}{I}$ indici.
Per ottenere la dimensione massima di un file è quindi sufficiente moltiplicare per ogni indice salvato la dimensione di un blocco: \(\quad D_M = \frac{D_b^2}{I} = \frac{D_b^2}{\log{(\frac{C}{D_b})}}\)
2.3.4. Allocazione in UNIX
Il metodo di allocazione utilizzato in UNIX è a indicizzazione su più livelli di indirizzamento basata su un grafo aciclico diretto.
La regola sulla quale ci dobbiamo basare è che:
In
UNIXtutto è un file.
I file si dividono in tre categorie:
- Ordinari: sono i veri e propri file
- Directory: sono dei file che rappresentano delle raccolte di altri file
- Speciali: rappresentano i dispositivi (ad esempio quelle in
/dev/)
Ad ogni file possono essere associati uno o più nomi simbolici detti link/alias. Ogni link si riferirà però ad uno ed un solo descrittore, detto i-node.
I singoli i-node sono identificati univocamente dagli i-number e sono contenuti nella i-list.
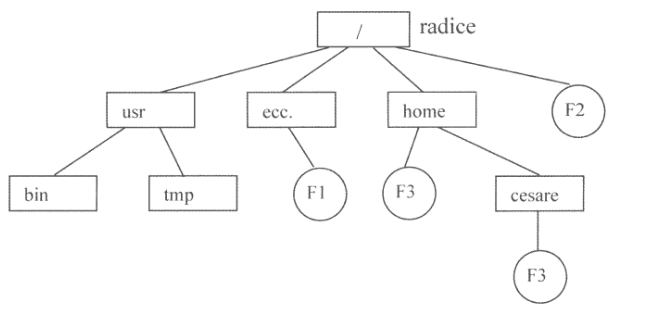
Il metodo di allocazione utilizzato in UNIX è quindi ad indice a più livelli.
Questa tecnica formatta il disco in blocchi fisici di dimensione costante e prefissata, dividendo la superficie del disco in quattro regioni.
La prima regione, detta BootBlock, occupa un blocco fisico, allocato ad un indirizzo prefissato, e contiene il programma di inizializzazione del sistema da eseguire nella fase di bootstrap.
La seconda regione è il SuperBlock. Occupa anch’essa la dimensione di un blocco e descrive l’allocazione del file system. In particolare qui sono contenuti:
- I limiti delle quattro regioni
- Il puntatore alla lista dei blocchi liberi
- Il puntatore alla lista degli
i-nodeliberi.
La terza regione è la i-List che contiene il vettore di tutti gli i-node.
L’ultima area è il DataBlocks. Questa area è tipicamente molto più grande delle altre, poiché rappresenta la zona effettivamente diposnibile per la memorizzazione dei file.
I blocchi liberi di questa zono sono organizzati in una lista collegata il cui primo indirizzo è contenuto nel SuperBlock.
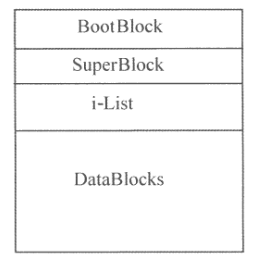
Gli i-node sono quindi formati da:
- Tipo: indica se il file è ordinario, directory o speciale (dispositivi)
- Proprietario e Gruppo: indicano chi è l’utente proprietario del file e qual è il gruppo di appartenenza del proprietario
- Dimensione: indica in numero di blocchi occupati dal file in memoria di massa
- Data: indica la data dell’ultima modifica effettuata sul file
- Link: il numero di nomi che riferiscono il file (hard-link). Se si ha un solo nome, questo valore è
1 - Bit di Protezione: è l’insieme dei
12bitche esprime la politica di protezione da applicare sul file. contiene i 9 bit dei premessi,SUID,GUIDeSTIcky bit. - Vettore di Indirizzamento: è costituito da un insieme di indirizzi che consente l’indirizzamento dei blocchi di dati sui quali è allocato il file (tipicamente sono
13 - 15).
Per capire meglio come vengono gestiti gli indirizzi nel vettore di indirizzamento supponiamo di avere:
- 13 indirizzi nel vettore (così come nelle prime versioni del sistema operativo)
- Blocchi di dimensione $D_b = 512 B$ con indirizzi su
32bit. Ciò significa che un blocco contiene $128$ indirizzi.
Se tutti gli indirizzi indirizzassero direttamente ai blocchi di dati avremmo che un file può essere al massimo $13 \cdot 512B = 6,5KB$, poco per gli standard moderni. Quello che si fa quindi è sfruttare l’indirizzamento multiplo:
- I primi
10indirizzi nel vettore accedono direttamente ai blocchi di dati, per una dimensione totale di $10 \cdot 512B = 5KB$ - L’
11-esimo indirizzo nel vettore punta a un blocco indice sfruttando l’indirizzamento singolo. Ciò significa che solo questo permette l’accesso a $128 \cdot 512B = 64KB$ di memoria - Il
12-esimo indirizzo nel vettore punta invece a un blocco indice che punta a blocchi indici sfruttando l’indirizzamento doppio. In questo caso questo indirizzo permette l’accesso a $128 \cdot 128 \cdot 512B = 8MB$ di memoria - Il
13-esimo indirizzo nel vettore utilizza l’indirizzamento triplo indicizzando $128^3 \cdot 512B = 1GB$ di memoria.
Avendo solamente 13 indirizzi nel vettore la dimensione massima di un file è nell’ordine del Giga Byte $(5KB + 64KB + 8MB + 1GB)$.
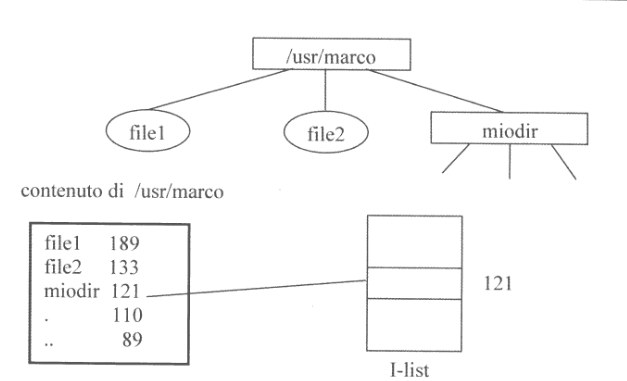
Le directory sono rappresentati da un file, in cui contenuto ne descrive la struttura logica. In particolare ogni record coniene la coppia di informazioni <nome_relativo, i-number> associate al file, come nell’immagine di seguito.
2.3.4.1. Strutture Dati del Kernel per l’accesso a File
Ogni file è quindi organizzato come una sequenza di byte detta stream.
Il metodo di accesso adottato nel sistema UNIX è quello sequenzale, ad ogni file aperto è quindi associato un I/O Pointer che indica implicitamente il prossimo elemento a cui accedere. Ogni accesso in memoria provoca un avanzamento dell’I/O pointer, fino a che non si incontra la sequenza EOF (End-Of-File) che indica la terminazione del file.
Per comprendere al meglio i meccanismi di accesso analizziamo le caratteristiche delle strutture dati del kernel.
A livello globale il kernel mantiene una Tabella dei File Aperti del Sistema (TFAS) allocata nella user structure del processo. Questa tabella contiene un elemento per ogni file aperto nel sistema, individuato da un indice intero detto file descriptor fd. Questo elemento non è altro che un puntatore all’i-node del file salvato nella Tabella dei File Attivi, copiata dalla memoria di massa.
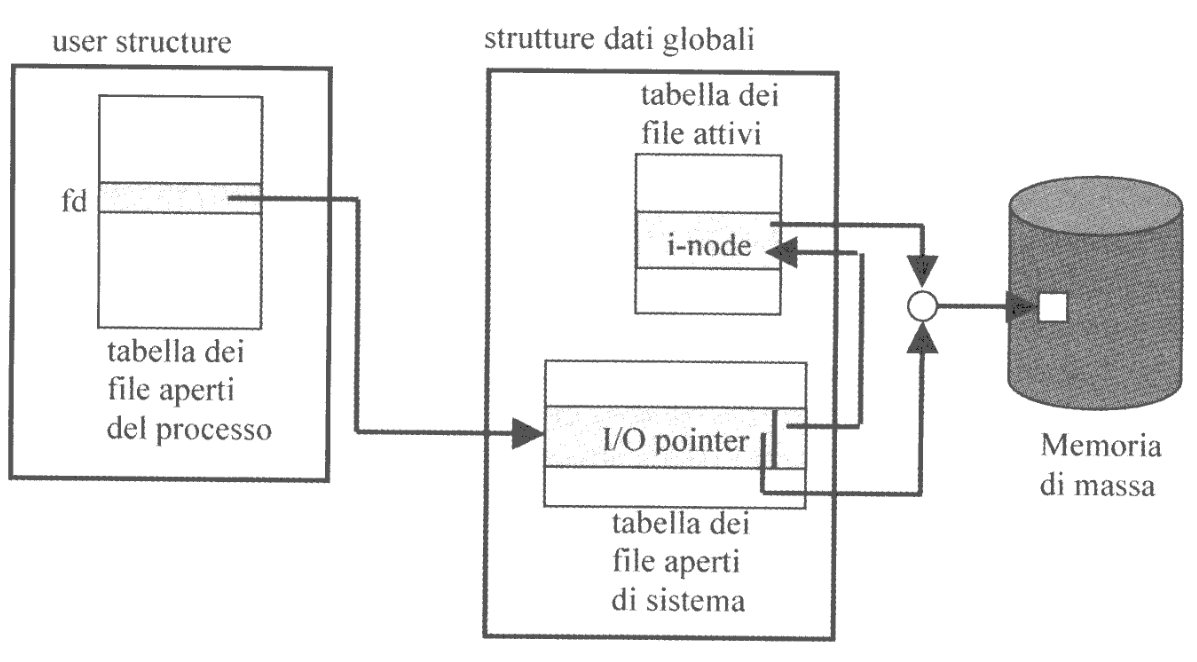
Più precisamento viene allocato un elemento nella TFAS per ogni operazione di apertura di file. Ciò implica che se due processi distinti aprono lo stesso file, avremo due elementi distinti nella TFAS, ma comunque uno solo nella tabella dei file attivi.
Se invece un processo genera dei figli (ad esempio con una fork()) questi condivideranno con il padre i vari file descriptor e di conseguenza anche gli I/O Pointer.
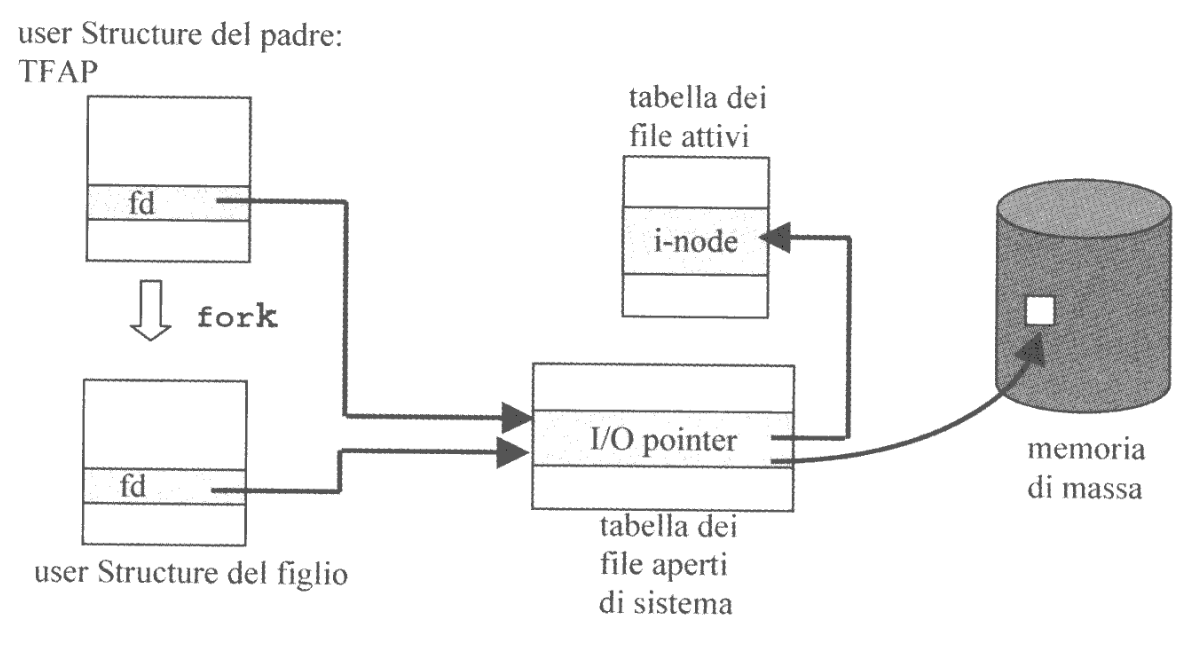
Di default sono aperti automaticamente i file speciali di standard input STD_IN, standard output STD_OUT e standard error STD_ERR.
Per ulteriori informazioni su come manipolare i file da codice è possibile consultare gli appunti di laboratorio.