1. Indice
2. Gestione delle Periferiche (I/O)
Il compito del sottosistema di I/O è quello di nascondere i dettagli hardware dei controllori dei dispositivi, garantendone una gestione omogenea idnipendentemente dalla loro struttura.
Infatti le periferiche di I/O sono in realtà composte da due parti:
- Periferica propriamente detta: componenti hardware con le quali l’utente si interfacia fisicamente
- Controllore: dell’hardware special purpose che ha il duplice scopo di gestire la periferica tramite un bus dedicato, e comunicare con il sistema attraverso il bus condiviso.
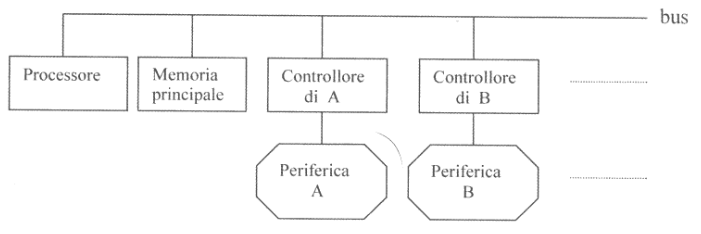
Il controllore è a tutti gli effetti un dispositivo programmabile, anche se questo avviene molto raramente. Tendenzialmente esegue un firmware interno, che gli permette di eseguire delle azioni che possiamo a tutti gli effetti classificare come processi esterni.
La gestione dei dispositivi di I/O quindi diventa un problema di sincronizzazione tra processi applicativi e processi esterni.
Il sottosistema di I/O deve anche:
- Definire lo spazio dei nomi con cui identificare i dispositivi
- Gestire i malfunzionamenti
- Garantire la sincronizzzazione tra l’attività di un dispositivo e quella del processo che lo ha attivato
- Gestire la bufferizzazione, ovvero il disaccoppiamento temporale e spaziale fra processi e periferiche
2.1. Organizzazione logica del sottosistema di IO
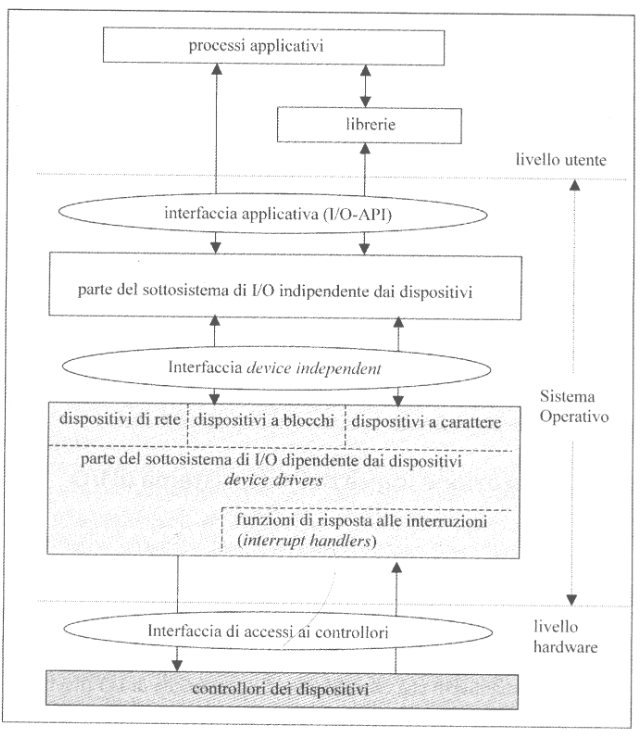
Sulla destra possiamo vedere l’organizzazione logica del sottosistema I/O.
Nel livello utente troviamo i processi applicativi e le librerie che questi utilizzano.
Nel livello sistema troviamo un interfaccia applicativa standard chiamata I/O-API, che utilizza anch’essa le librerie del livello utente e che tratta tutti i dispositivi in maniera indipendnete.
In particolare, in UNIX i dispositivi sono visti come dei file. L’I/O-API comunica proprio con questi file, quindi non si preoccupa del tipo del dispositivo, ma si occupa di gestire il flusso di dati da/a questo file.
Le funzioni definite nell’interfaccia sono implementate in buona parte nella sezione del sottosistema indipendente dai dispositivi. Questo software comunicherà con un interfaccia interna (non visibile al programmatore) chiamata Interfaccia device independent.
Questa interfaccia comunica con dell’altro software che stavolta è device-dependent dividendo le periferiche in diverse categorie:
- Dispositivi di rete: permettono l’input/output tramite interfacce
- Dispositivi a blocchi
- Dispositivi a carattere
Si trova in questa sezione anche il codice relativo ai device-drivers e la gestione delle interrupt-handlers delle interruzioni esterne.
Nel livello hardware si trova l’interfaccia di accesso ai controllori e i veri e propri controllori.
La funzione di naming permette l’identificazione di ogni dispositivo mediante un nome simbolico, che agirà da puntatore al descrittore del dispositivo.
In UNIX il naming traduce il nome simbolico (nel formato di pathname) in un inode, ma vedremo meglio più avanti come questo avviene.
Un’altra delle funzioni più importanti offerte dal livello software indipendente dai dispositivi è quello di fornire una o più aree di memoria tampone, dette buffer, destinate a contenere i dati durante il trasferimento tra il dispositivo e l’area di memoria virtuale del processo applicativo da cui i dati devono essere prelevati/inseriti.
Ci sono diverse ragioni per le quali riserviamo questi buffer, prima fra tutte quella di far fronte alla notevole differenza fra la velocità con cui il processore può produrre/consumare informazioni e quella del dispositico di consumarle/produrle. Il loro utilizzo introduce però anche dell’overhead, dovuto proprio alla doppia copia dei dati, prima dal dispositivo al buffer e dopo dal buffer all’u-buf del processo applicativo.
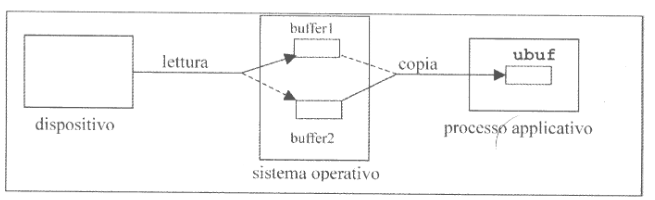
La presenza di più buffer permette di avere trasferimenti più efficienti, mantenendo la trasparenza.
Nel caso in cui i dati vengano trasferiti in blocchi di dimensione fissa, una tipica operazione di lettura potrebbe essere:
/**
* @param fd nome simbolico del file da leggere
* @param ubuf indirizzo del buffer nella memoria virtuale del processo
* @param nbytes numero di byte richiesti
*/
n = read(fd, ubuf, nbytes);
Normalmente un processo applicativo deve sospendere la propria esecuzione fino a quando i dati richiesti sono stati scritti in ubuf.
Se la read è implementata facendo ricorso a un buffer di sistema l’operazione di lettura:
- Trasferise i dati di un intero settore dal disco al buffer,
- Copia il contenuto dal buffer all’area
ubufdel processo utente solo per la dimensionenbytes - Libera l’
ubufcancellando in maniera del tutto trasparente i caratteri letti in più
È possibile cogliere il vantaggio di questa organizzazione nei casi in cui un processo deve leggere ed elaborare sequenze multiple di blocchi.
In questi casi è possibile ridurre notevolmente il tempo di attesa del processo e il numero di commutazioni di contesto se l’elaborazoine di un blocco di dati viene eseguita in parallelo alla lettura nel buffer del successivo blocco di dati, in una politica di read-ahead. Soprattutto se, come nell’immagine sopra, sono presenti più buffer di sistema da poter utilizzare in modo circolare.
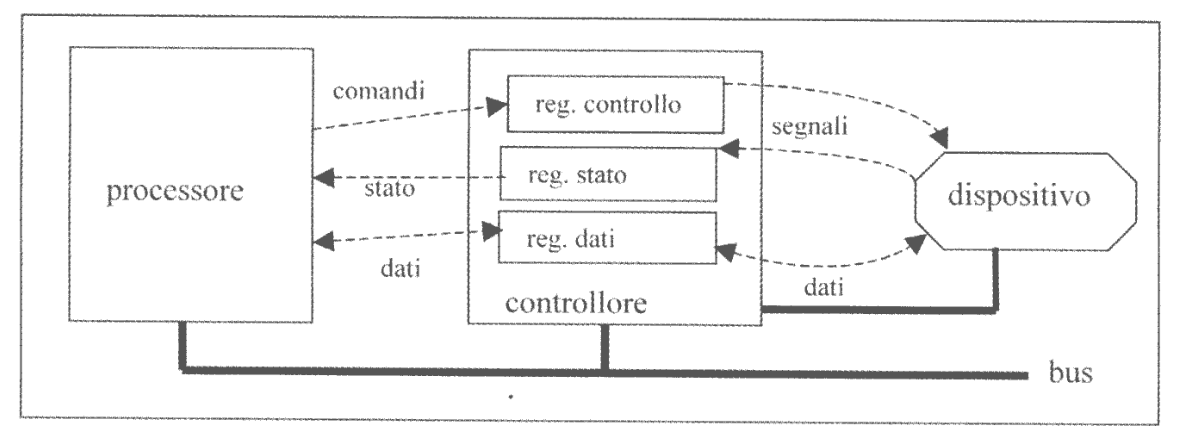
Per comprendere la struttura di un driver è conveniente partire da un possibile schema semplificato di come si presenta al processore il controllore di un dispositivo.
La CPU agisce sul controllore tramite i registri di cui questo dispone e che vengono indirizzati mediante le istruzioni macchina di I/O.
Il numero e il tipo di registri di presenti nel controllore varia da caso a caso in base alla complessità delle funzioni che il dispositivo è in grado di svolgere.
In generale possiamo rappresentare in modo estremamente semplificato tre registri:
- Registro di Controllo
- Registro di Stato
- Registro Dati
Il primo è un registro di sola scrittura attraverso il quale la CPU può controllare il funzionamento del dispositivo. In questo registro possiamo ipotizzare la presenza di un bit start che permette di attivare il dispositivo.
Nel caso il dispositivo possa svolgere più operazioni, ha senso immaginare alla presenza di altri bit che permettono di selezione il comportamento che il dispositivo deve assumere.
È poi sicuramente presente un bit di abilitazione alle interruzioni che abilita il controllare a inviare segnali di interruzioni alla CPU per segnalare la terminazione dell’operazione del dispositivo.
Il secondo è un registro di sola lettura per la CPU attraverso il quale il dispositivo mantiene aggiornato il proprio stato. Anche in questo caso ha senso immaginare la presenza di uno o più flag bit e di uno o più error bit che vengono settati qual’ora si verificassero uno o più eventi anomali di natura diversa.
Il terzo coincide con il buffer del controllore.
2.2. Processi Esterni
Possiamo illustrare il comportamento di un dispositivo con il relativo controllore come nella figura sulla destra.
Ogni dispositivo esegue permanentemente una sequenza di azioni equiparabile con l’esecuzione di un processo. La differenza però è che il processo non corrisponde all’eseuzione di un programma, ma piuttosto ad una sequenza di azioni cablate eseguite in parallelo al flusso della CPU. Per distiguenre questo tipo di “processi” li identificheremo con il termine di processi esterni.
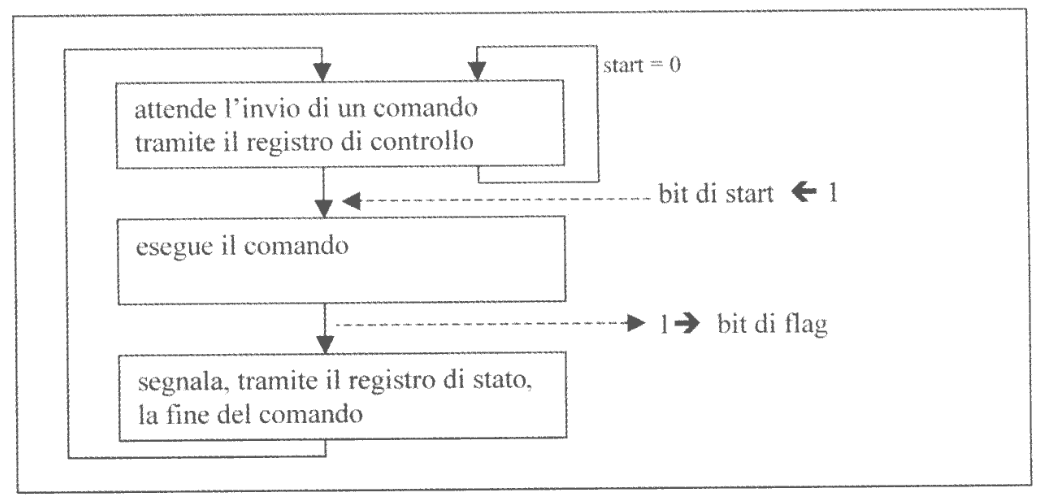
Normalmente un dispositivo si trova in stand-by, in attesa che il bit di start del registro di controllo venga settato.
Una volta attivato il dispositivo esegue il comando e alla fine registra l’evento ponendo a uno il relativo bit di flag, procedendo poi a tornare in attesa di una nuova attivazione. Possiamo quindi riassumere il comportamento con questo codice:
while (true) {
// Attendo l'invio di un comando
while (Start == 0);
// Eseguo il comando
executeComand();
// Registro l'evento
setComandOutputAndFlag();
}
Per forzare la sospensione del processo in attesa su un flag è possibile associare al dispositivo un semaforo inizializzato a zero e sostituire il ciclo di attesa attiva una wait su tale semaforo.
Il comportamento divenra quindi qualcosa del genere:
semaforo dato_disponibile = 0;
// ...
for (int i = 0; i < n; ++i) {
/*
* preparo il comando:
* assemblo in un registro della CPU
* un valore da trasferire nel registro
* di controllo
*/
executeComand();
wait(dato_disponibile);
// verifico l'esito
}
Poiché adesso il processo si sospende, non siamo più in grado di controllare direttamente la disponibilità del dato nel registro del controllore.
Dovrà quindi essere il controllore stesso a segnalarci l’evento, risvegliando il processo applicativo attraverso una funzione specifica, l’interrupt handler (inth).
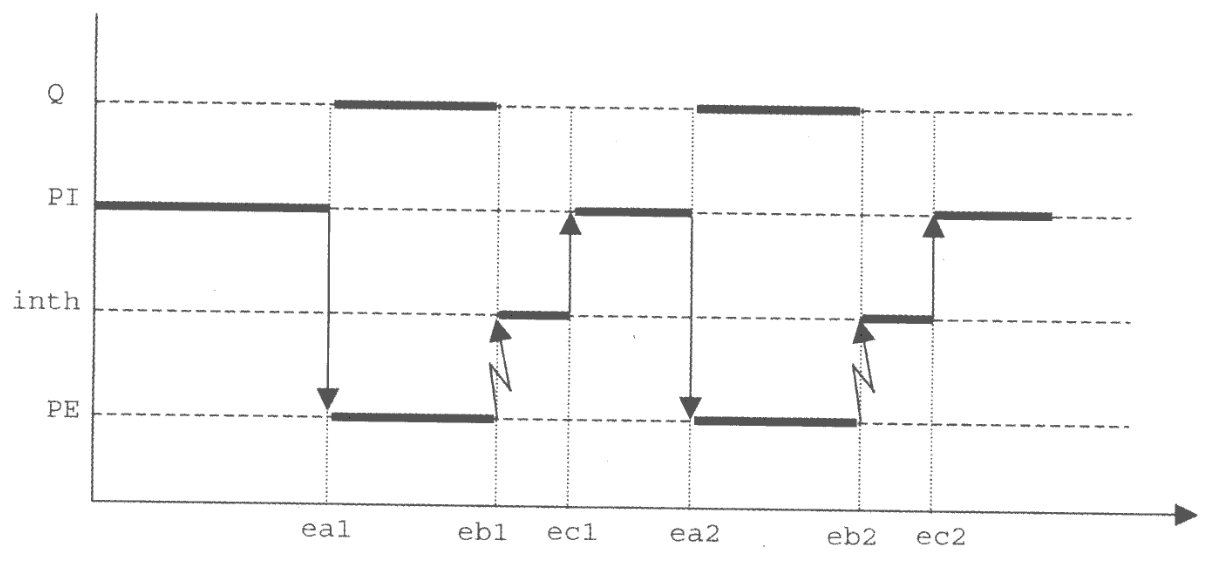
Nella figura sulla destra possiamo analizzare un diagramma temporale che illustra come si alternano le fasi di esecuzione.
Indichiamo:
-
PI: il processo applicativo che esegue l’operazione di input deglindati trasferendo un byte alla volta -
PE: il processo esterno che elabora i dati -
inth: funzione di risposta alle interruzioni del dispositivo che si occuperà di effettuare lesignal -
Q: generico processo applicativo schedulato quandoPIsi sospende sul semaforo.
All’istante ea1, PI si blocca sul semaforo dopo aver eseguito il primo ciclo.
Il processo subisce un cambio di contesto schedulando un altro processo generico Q mentre il parallelo all’attività della CPU inizia l’attività del dispositivo PE.
All’istante ea2, PE termina l’attività viene posto a uno il flag, interrompendo la CPU, mandando in esecuzione la routine di interruzione inth che esegue una signal sul semaforo, riattivando PI.
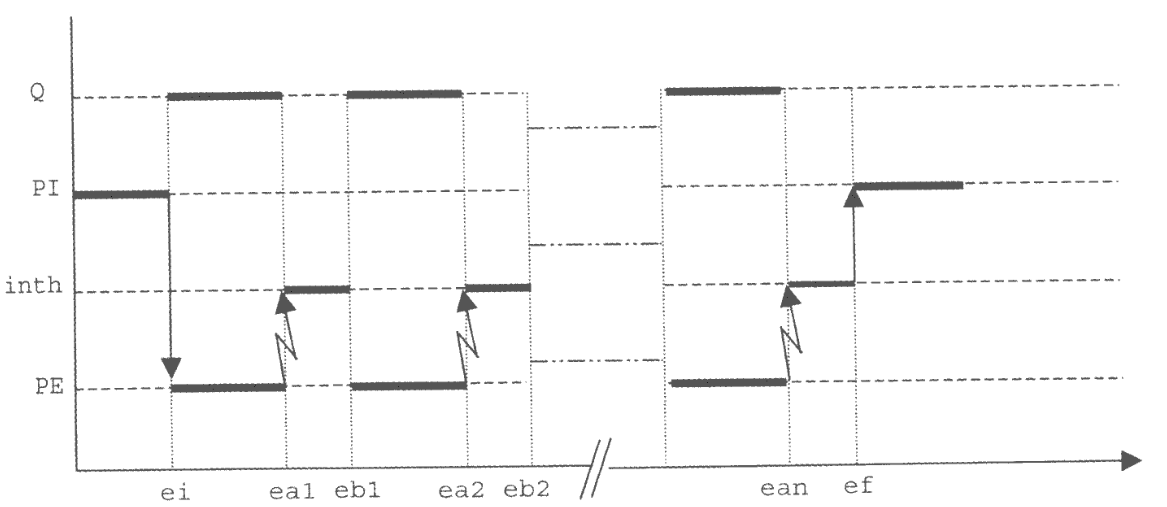
L’esempio appena fatto questo è altamente inefficiente, per trasferire $n$ byte abbiamo infatti un processo che per $n$ volte viene schedulato solo per poi tornare in attesa.
Come suggerisce l’immagine sulla destra possiamo delegare ad inth l’operazione di caricare il singolo byte affinché PE lo possa leggere.
In questo caso PI non carica il singolo dato, ma piuttosto la locazione di memoria dove si trovano tutti i dati. inth si occuperà di accedervi e fornire i singoli byte a PE.
Questo ci permette di almeno dimezzare il numero di cambi di contesto nello stesso arco temporale.
2.2.1. Descrittore e Driver di un dispositivo
Per ottenere il comportamento descritto fin’ora è necessario che la routine di interruzione riesca a discriminare tra interruzioni intermedie di ogni blocco di trasferimenti e interruzione finale in corrispondenza della quale deve essere riattivato il processo applicativo.
Un modo per fare ciò è riservare in memoria una struttura dati destinata a rappresentare il dispositivo, chiamata descrittore del dispositivo, sulla quale possano operare:
- Il processo applicativo attraverso le funzioni offerte dall’interfaccia device independent
- La routine di gestione delle interruzioni sollevate dal dispositivo.
L’unione tra il descrittore del dispositivo e le funzioni di accesso costituisce il device driver.
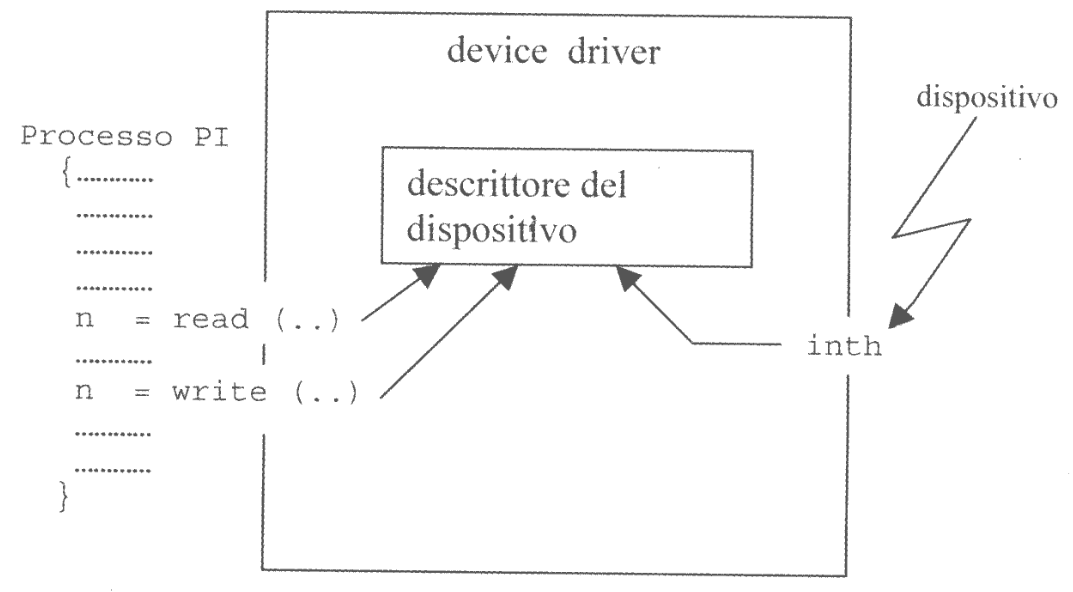
Il descrittore del dispositivo è una struttura dati utilizzata per due scopi diversi:
- Nascondere al proprio interno tutte le informazioni che sono associate al dispositivo
- Consentire le comunicazioni di informazioni tra processo applicativo e dispositivo e viceversa.
I descrittori possono avere parametri diversi, ma in generale i seguenti dati sono sempre presenti:
- Indirizzo registro di controllo
- Indirizzo registro di stato
- Indirizzo registro dati
- Stato di sincronizzazione:
dato_disponibile - Contatore dati da trasferire:
contatore - Indirizzo del buffer:
puntatore - Risultato del trasferimento:
esito
Per semplificare quanto è stato già detto, possiamo adesso illustrare come è strutturato il driver di un dispositivo, mostrando le funzioni di lettura o scrittura che appartengono all’interfaccia device independent.
La funzione di lettura:
/**
* @param disp indica il dispositivo su cui operare
* @param pbuf il puntatore al buffer di sistema in cui trasferire i dati letti
* @param cont il numero di dati da leggere
* @return il numero di dati letti, -1 in caso di terminazione erronea
*/
int read(int disp, char* pbuf, int cont) {
// descrittore è la lista dei descrittori indicizzati tramite il numero dispositivo
descrittore[disp].contatore = cont;
descrittore[disp].puntatore = pbuf;
// non diamo dettagli sulle applicazioni device-dependent
<attivo il dispositivo settando `bitStart = 1`>
// sospendiamo quindi il processo in attesa che il trasferimento sia terminato
descrittore[disp].dato_disponibile.wait();
if (descrittore[disp].esito == ERROR_CODE) {
return -1;
}
else {
return (cont - descrittore[disp].contatore);
}
}
All’arrivo di un’interruzione il processo in esecuzione viene interrotto e, via hardware, va in esecuzione la funzione inth che leggerà per prima cosa il registro di stato per verificare la causa dell’interruzione.
Se questa non è dovuta ad errori, inth leggerà il dato prelevandolo dal registro dati e trasferendolo nel buffer di sistema all’indirizzo contenuto in puntatore.
Viene poi incrementato puntatore e decrementato contatore. Se contatore != 0 allora il trasferimento non è ancora completato e quindi il dispositivo viene riattivato per il prossimo trasferimento, altrimenti viene riattivato il processo applicativo settando opportunamente il campo esito.
Se invece l’interruzione fosse dovuta ad errore:
- Se è mascherabile, viene eseguita una routine di gestione dell’evento anomalo
- Se non è mascherabile, la routine setta l’errore nel campo
esitoe termina riattivando il processo applicativo.
void inth() {
char b;
<leggo il registro di stato del controllore>
if (ERROR_BIT == 0) {
// non ci sono errori
<leggo il registro dei dati assegnando la variabile locale b>
*(descrittore[disp]).puntatore = b;
++(descrittore[disp].puntatore);
--(descrittore[disp].contatore);
if (descrittore[disp].contatore != 0) {
<riattivo il dispositivo>
}
else {
descrittore[disp].esito = CORRECT_TERMINATION;
<disattivo il dispositivo>
// riattivo il processo applicativo
descrittore[disp].dato_disponibile.signal();
}
}
else {
// presenza di errori
<routine di gestione errore>
if (<errore non recuperabile>) {
descrittore[disp].esito = <codice errore>;
descrittore[disp].dato_disponibile.signal();
}
}
return;
}
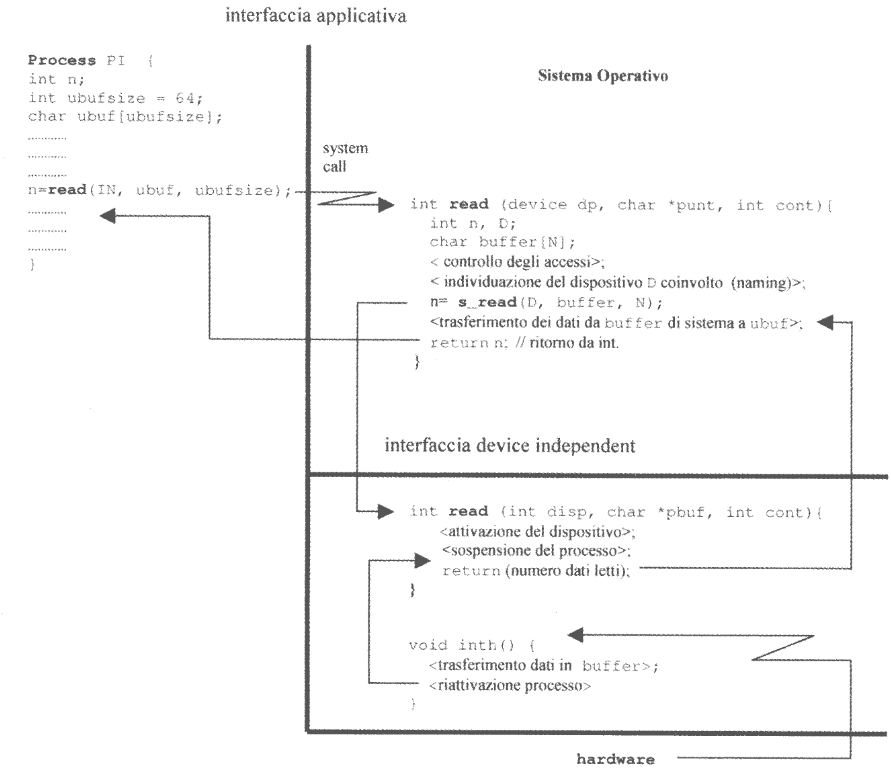
Al fine di chiarire quanto detto finora, illustriamo com’è strutturato il flusso di controllo durante l’esecuzione di una chamata di sistema relativa ad un trasferimento di dati.
Nell’immagine sulla destra troviamo tre sezioni principali:
- Quella sulla sinistra è l’equivalente dell’
IO-API - Quella in alto sulla destra rappresenta il codice del sistema operativo che è device independent
- Quella in basso sulla destra invece è l’implementazione device dependent, con la funzione
_read(le funzioni di questo tipo sono tipicamente precedute dal carattere_).
2.2.2. Gestione del temporizzatore
Tra i vari dispositivi all’interno di calcolatore, uno dei molto particolare è il timer.
La sua particolarità risiede nel fatto che viene utilizzato come una fonte di interruzioni cadenzate nel tempo.
Un primo esempio di utilizzo di un timer è in relazione agli algoritmi di schedulazione della CPU in sistemi time-sharing.
Dal punto di vista hardware il controllore di un timer contiene:
- Indirizzo registro di controllo
- Indirizzo registro di stato
- Indirizzo registro contatore
- Array di semafori privati:
fine_attesa[N] - Array di interi:
ritardo[N]
Ciascun semaforo viene utilizzato per bloccare il corrispondente processo che invocca la primitiva delay.
void delay(int n) {
int proc;
proc = <indice del processo in esecuzione>;
descrizione.ritardo[proc] = n;
descrittore.fine_attesa[proc].wait();
}
void inth() {
for (int i = 0; i < N; ++i) {
if (descrittore.ritardo[i] != 0) {
--(descrittore.ritardo[i]);
if (descrittore.ritardo[i] == 0) {
descrittore.fine_attesa[i].signal();
}
}
}
}
2.3. Gestione e organizzazione dei dischi
Le unità di memoria di masse, soprattutto i dischi, rappresentano dei dispositivi di particolare importanza agli effetti dell’efficienza e dell’operatività dell’intero sistema.
Andiamo a trattare i dischi magnetici così costruiti:
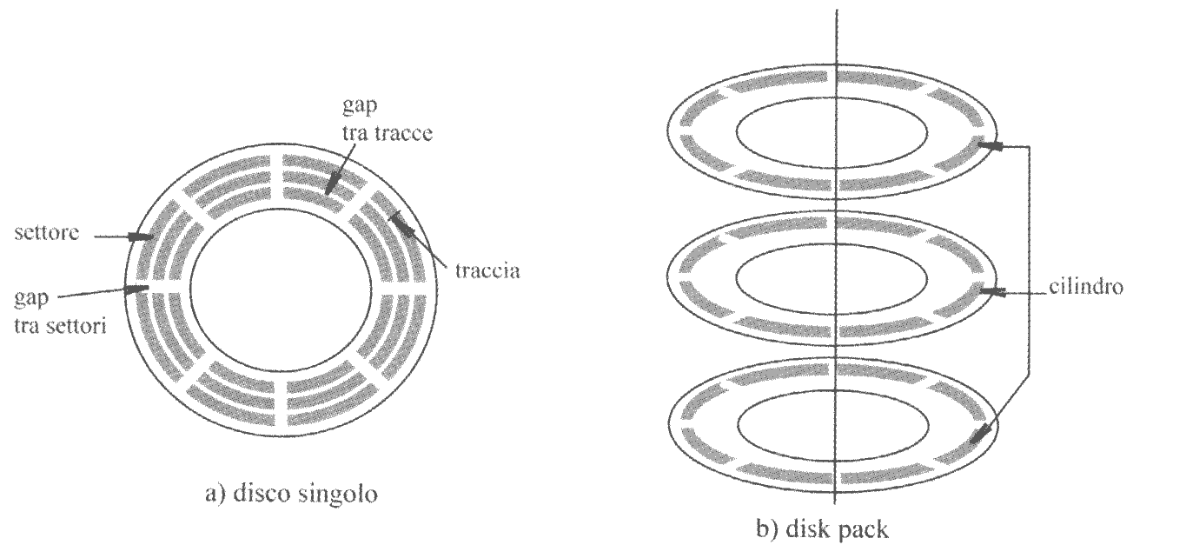
I dati sul disco sono letti/scritti da delle testine magnetiche mobili che si spostano tramite un pivot leggendo un arco di dati. Per poter leggere tutti i dati il disco ruota. Nel caso di disk-pack i dischi possono essere utilizzati anche su entrambe le facce.
Il numero di bit memorizzabili all’interno di ogni traccia è lo stesso per tutte le tracce, così da semplificare la logica di controllo del dispositivo.
Il trasferimento di dati tra memoria principale e disco avviene in termini di unità di trasferimento, quantità di dimensione fissa corrispondenti ai settori nei quali è divisa ogni traccia (tipicamente 512-1024 Byte).
Il numero di settori all’interno di una stessa traccia è dell’ordine di alcune centinaia.
Nella tabella di seguito vediamo i dati di alcuni dischi Western Digital:
| Parametri | Descrizione | AC2540 |
WDE18300 |
|---|---|---|---|
| Numero di cilindri | Numero dei cilindri | $1048$ | $13614$ |
| Tracce per cilindro | Tracce contenute in un cilindro | $4$ | $8$ |
| Settori per traccia | Numero di settori contenuti in una traccia | $252$ | $320$ |
| Byte per settore | Numero di byte contenuti in un settore | $512$ | $512$ |
| Capacità | Capacità totale del disco | $540 MB$ | $18.3 GB$ |
| Minimo seek tra cilindri adiacenti | Tempo minimo necessario alla testina per spostarsi sulla traccia corretta | $4ms$ | $0.6ms$ |
| Tempo medio di seek | Tempo medio necessario alla testina per spostarsi sulla traccia corretta | $11ms$ | $5.2ms$ |
| Tempo di rotazione | Tempo necessario al disco per effettuare una rotazione completa | $13 ms$ | $6 ms$ |
| Tempo di trasferimento di un settore | Tempo necessario per trasferire tutti i Byte di un settore | $53 \mu s$ | $19 \mu s$ |
Alcuni parametri che è possibile calcolare sono:
- Tempo medio di trasferimento $TF$: tempo necessario per trasferire 1 Byte.
- Tempo medio di Accesso $TA$: tempo necessario affinché un settore arrivi sotto la testina
- Tempo medio di trasferimento $TT$: tempo necessario per traferire 1 Byte se la testina e il disco fossero fissi (tempo di trasferimento di un settore / dimensioni settore)
- Seek time $ST$: tempo che occorre alla testina per posizionarsi sulla traccia corretta.
- Rotational Latency: tempo medio dovuto alla rotazione (tipicamente la metà del tempo di rotazione)
Le relazioni che mette in relazione questi parametri sono le seguenti: \(TF = TA + TT \\ TA = ST + RT\)
Per i dischi presenti sopra possiamo calcolare:
AC2540 |
WDE18300 |
|
|---|---|---|
| $TA$ | $11 + 6.5 = 17.5 ms$ | $5.2 + 3 = 8.2 ms$ |
| $TF$ | $17.5 + 0.053 = 17.553 ms$ | $8.2 + 0.019 = 8.219 ms$ |
Quello che notiamo è che tra il tempo medio di trasferimento e quello di accesso, quello che ha più influenza sulle prestazioni è il $TA$. Per poterlo ottimizzare quindi è auspicabile salvare i dati in maniera contigua su settori adiacenti sulla stessa traccia, così da minimizzare i vari parametri.
Un settore è indicizzato da una terna (f, t, s) (faccia, numero della traccia/cilindro nella faccia, numero del settore nella traccia), dove l’indice del settore si ricava come i = f * Nt * Ns + t * Ns + s, dove Ns indica il numero di settori per traccia e Nt il numero di tracce per cilindro.
Attraverso questo indirizzamento possiamo considerare un disco come un array di settori.
A questo punto discutiamo come il disco gestisce la coda delle richieste pendenti ad una traccia così da minimizzare il tempo complessivo di accesso ai dati.
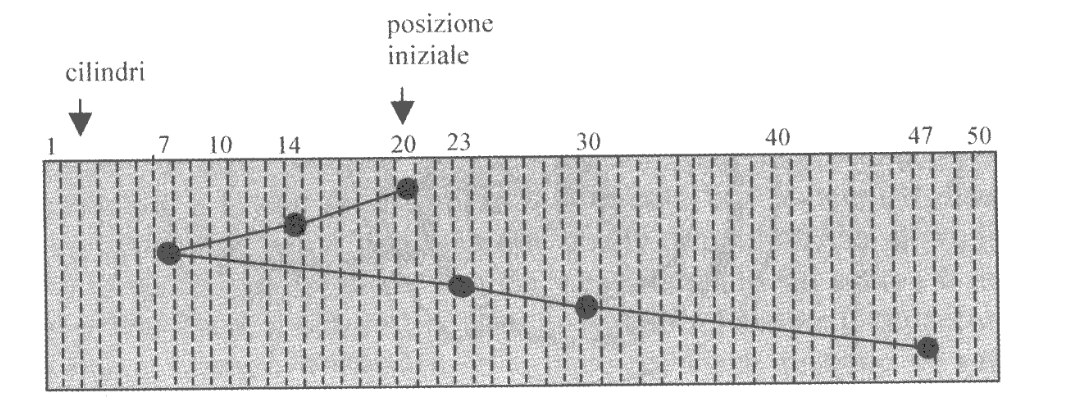
Ipotizziamo che la testina si trovi sulla traccia 20 e abbia le richieste, in ordine, 14, 40, 23, 47 e 7, per uno spostamento totale di $113$.
L’algoritmo più “semplice” è il FCFS, nel quale si soddisfano le richieste nell’ordine nelle quali sono arrivate.
Questa soluzione non rispetta alcuna ottimalità, non minimizzando gli spostamenti della testina al fine di ridurre al minimo i tempi di seek.
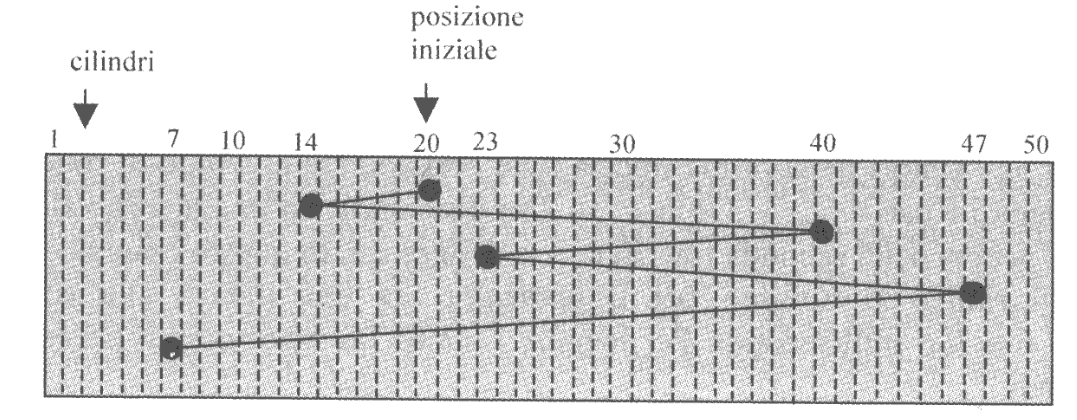
Un criterio molto più efficiente potrebbe essere un approccio greedy, che scceglie quella che chiede di operare sul cilindro più vicino alla posizione attuale della testina, così da minimizzare localmente il tempo di seek.
In riferimento all’esempio precedente, le richieste verrebbero adesso servite in ordine 23, 14, 7, 40 e 47, per uno spostamento totale di $59$ cilindri.
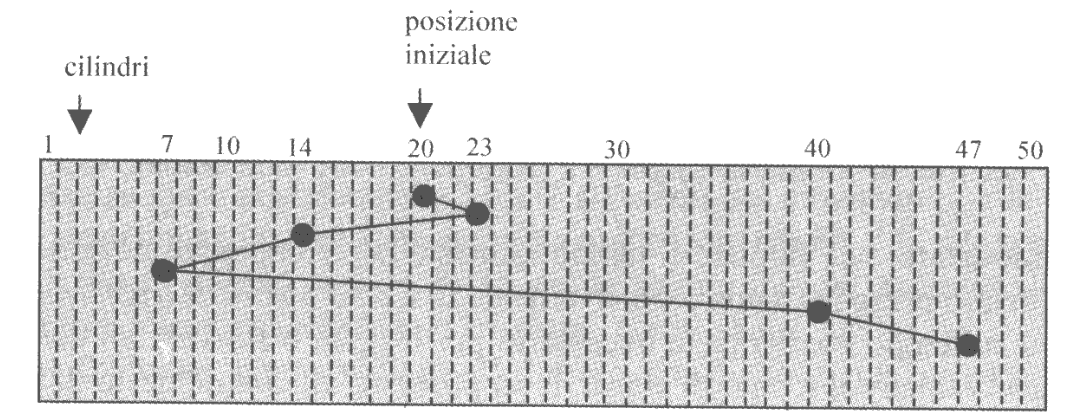
Questo algoritmo si chiama Shortest-Seek-Time-First (SSTF), e soffre di starvation.
Per risolvere la starvation si utilizza un algoritmo diverso, noto col termine di SCAN algorithm. In questo algoritmo la testina parte da un bordo del disco e serve tutte le richieste pendenti in ordine crescente. Una volta raggiunta l’altro bordo (o in assenza di richieste pendenti con indice maggiore) si cambia verso e si iniziano a servire le richieste in ordine decrescente.
Con riferimento all’immagine precedente (immaginando che la situazione di partenza sia decrescente) le richieste sarebbero servite nell’ordine 20, 14, 7, 23, 40 e 47, per uno spostamento totale di $53$ cilindri.