1. Indice
- 1. Indice
- 2. Processi
- 3. Scheduling
- 4. Thread
- 5. Processi in UNIX
2. Processi
Il termine processo viene utilizzato in modo informale per indicare un programa in esecuzione. Una definizione più formale è la seguente:
Un processo rappresenta la sequenza di eventi osservabili generati dall’elaboratore durante l’esecuzione di un programma. Identifica quindi l’unità di esecuzione all’interno di un sistema operativo multiprogrammato.
Più processi possono essere associati allo stesso programma, in quel caso prendono il nome di istanze. Ciascuna istanza rappresenta quindi l’esecuzione dello stesso codice con dati in ingresso diversi.
Infatti al variare dei valori di ingresso uno stesso processo può avere storie diverse (svilupparsi in if-else-branch diversi, iterare più o meno volte uno stesso ciclo, …).
2.1. Stato di un processo
Un sistema operativo multiprogrammato in particolare consente l’esecuzione concorrente di più processi.
La CPU, in un sistema multiprogrammato, passa da un processo all’altro ad elevatissima velocità, tale per cui l’utente ha l’impressione che i vari processi vengano eseguiti parallelamente. In realtà la CPU non esegue nulla in parallelo, in quanto può eseguire sempre e solo una istruzione alla volta. Chiamiamo però questo fenomeno: parallelismo virtuale. Il parallelismo fisico invece è possibile solo in presenza di più CPU.
Dato il continuo scambio di processi la CPU deve essere in grado di salvare lo stato di ciasuno di esso nel momento in qui viene interrotto. Così facendo, quando riprenderemo con la sua esecuzione, saremo in grado di farlo senza generare errori.
Nei sistemi monoprogrammati gli stati possibili nei quali un processo può essere nel suo lifetime sono due:
attivo: quando il processo ha il possesso della CPUbloccato: quando il processo non ha il possesso della CPU, perché è in attesa del verificarsi di un evento.
In questi sistemi un processo cambia i due stati tramite:
- Sospensione: il processo si mette in CPU-idle e mette a lavoro una periferica
- Riattivazione: la periferica, terminato il lavoro, invia un interruzione esterna alla CPU riattivando il processo
Attenzione, il fatto che il processo è bloccato non significa che le sue risorse non possano cambiare. Infatti, se il processo è stato bloccato a seguito di una richiesta di recupero dati da parte di un dispositivo esterno nella memoria, il DMA sovrascrive la memoria del processo mentre questo è bloccato.
Inoltre, il fatto che la CPU sia nello stato idle, non significa che è spenta. È infatti proprio lei a rendersi conto dell’arrivo dell’interruzione esterna segnalata dall’APIC.
Dovrà quindi esistere un modo per effettuare controlli sull’arrivo delle interruzioni esterne.
Quindi i sistemi monoprogrammati hanno senso solo se:
L’unico processo presente deve includere anche il sistema operativo e le sue strutture dati
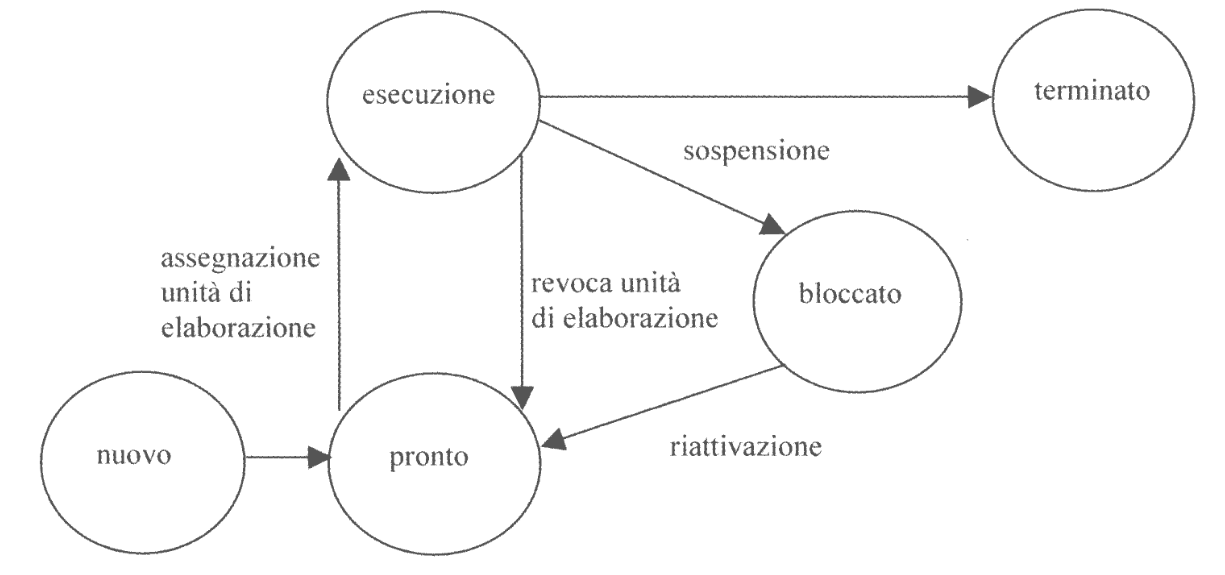
In sistemi multiprogrammati, se il numero di CPU è minore del numero di processi, esiste un ulteriore sotto-stato:
attivo: diviso adesso in due sotto-stati:in esecuzione: il processo ha assegnata la CPUpronto: il processo è in attesa di andare in esecuzione
bloccato: il processo è in attesa di qualche evento
La transizione esecuzione $\to$ pronto si chiama revoca della CPU, oppure reapage, mentre la transizione inversa si dice assegnazione.
In questa modalità solo i processi in esecuzione possono sospendersi nello stato bloccato. Inoltre, la CPU in questo caso non è necessariamente idle, ma potrebbe essere busy, sia con processi utente sia con processi sitema (come processi di manutenzione).
Oltre a ciò, un processo bloccato che viene riattivato va a finire nello stato pronto.
In questi sistemi si introduce adesso il problema di scegliere però quale processo pronto dovrà andare in esecuzione.
Il meccanismo che effettua questa scelta si chiama scheduler.
Lo scheduler va in esecuzione quando:
- Il processo in
esecuzionesi sospende - Al processo in
esecuzioneviene revocata la CPU - Il processo in
esecuzionetermina
A seconda del criterio di scheduling, lo scheduler potrebbe avviarsi anche quando un nuovo processo viene creato (scheduling per priorità).
Questo modello viene chiamato Modello a cinque stati:
Per riuscire a mantenere in maniera consistente e corretta le varie informazioni del processo mentre esso transita nei vari stati è necessario avere una struttura dati specifica, chiamata descrittore di processo. L’allocazione del descrittore di processo, e della memoria a lui risevata sanciscono la creazione del processo.
In questo modo il singolo processo non si rende conto che la sua esecuzione è stata interrotta, ma crede di aver avuto il possesso della CPU, chiamata proprio per questo CPU virtuale, per tutto il suo lifespan. Le CPU virtuali sono dotate di program counter e registri, che contengono le informazioni relative ad ogni processo alle quali sono associate,.
Un processo è quindi rappresentato da:
- Codice: puntatore a un file che contiene il codice del processo
- Dati: Dipendono dal programma. È quindi necessario che il codice eseguibile sia definito in modo tale da dare un idea chiara delle variabili e delle strutture dati necessarie al programa. Verosibilmente, anche in questo caso avremo un puntatore alla memoria principale, in quanto memorizzare tutti i dati in una struttura sarebbe estremamente difficile
- Program Counter, Registri e Stack: per poter descrivere un processo sospeso/bloccato è necessario avrer memorizzato lo stato di quando era in esecuzione. Questi strumenti ci permettono di farlo.
- Stato: specifica cosa il processo sta facendo in un determinato momento. Il fatto che possa essere bloccato o messo in attesa giustifica la necessità di memorizzare i campi del processo in un descrittore.
Ad un processo possono anche essere associate delle risorse:
- Memoria: il programma potrebbe chiedere di descrivere delle strutture dati in memoria heap attraverso delle
new. È quindi importante mantenere anche un puntatore a questa memoria - File: il processo potrebbe accedere anche ad un elenco di file per operazioni di lettura/scrittura, dobbiamo mantenere traccia anche di questi
- Dispositivi I/O: dobbiamo sapere anche a quali dispositivi di I/O il processo ta utilizzando.
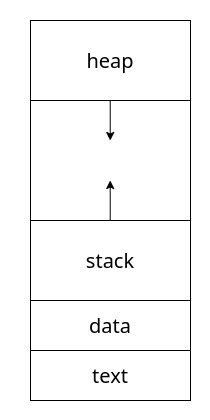
2.2. Spazio Virtuale di Memoria
Lo spazio virtuale di memoria di un processo è generalmente rappresentato come sulla destra.
Dobbiamo sicuramente trovare una sezione text nel quale è contenuto il codice del processo.
Nella sezione data si trovano invece le strutture dati definite dal processo.
Successivamente abbiamo due spazi complementari:
Heap: dall’alto verso il bassoStack: dal basso verso l’alto
Questi hanno dimensione variabile nel corso del lifespan del processo.
2.3. Descrittori di Processo e Code processi
Abbiamo già detto che ad ogni processo è associato un descrittore di processo (PCB, Process Control Block), che a livello software si implementa come una struttura dati.
I descrittori sono a loro volta organizzati in una tabella, chiamata tabella dei processi.
All’interno di un descrittore di processo sono salvati i dati:
- Nome del processo: nei sistemi
UNIXsi utilizza un numero naturale, detto Process ID (pid). Il numero dibitsul quale si codifica ilpiddetermina il numero massimo di processi. Inoltre, vanno gestiti ipiddei processi terminati (vedremo che lo farà direttamente un meccanismo all’interno del kernel) - Stato del processo
- Modalità di servizio dei processi: ha un ruolo diverso a seconda del tipo di sistema operativo:
- Nei sistemi priority contiene l’importanza relativa del processo nei confronti degli altri
- Nei sistemi a suddivisione del tempo contiene invece il quanto di tempo che la CPU può dedicare allo stesso
- Nei sistemi real-time contiene il tempo massimo entro il quale la richiesta deve essere soddisfatto
- Informazioni sulla gestione della memoria: vedremo che qui saranno contenuti dei puntatori che permettono di mantenere le informazioni sugli indirizzi di memoria allocati
- Contesto del processo: contiene le informazioni relative ai registri della CPU utilizzati durante il cambio di contesto
- Utilizzo delle risorse: in
UNIXci sono dei puntatori a tabelle logiche del sistema (dispositivi I/O assegnati, file aperti, tempo di uso della CPU, …) - Identificazione del processo successivo: L’ultimo dato è necessario per poter correttamente implementare le code di processi.
All’interno del sistema sono presenti tante code di processi, si dividono generalmente in due macrocategorie:
coda pronti: contiene i descrittori dei processi in attesa di andare in esecuzione.Vedremo come in alcuni casi potremmo anche averne più di unacoda processi bloccati: contiene i descrittori dei processi che attendono l’arrivo di una interruzione esterna per poter tornare nello statopronti
2.4. Cambi di Contesti
L’utilizzo della CPU viene commutato da un processo all’altro. Ogni volta che si effetta questa commutazione hanno luogo una serie di azioni
- Salvataggio stato: si salva il contesto del processo in
esecuzionenel suo descrittore - Inserimento del descrittore nella coda adeguata (
bloccati,pronti, …) - Short term scheduling: Lo scheduler seleziona un altro processo dalla coda dei processi
prontie si carica il suopidnel registro che identifica il processo in esecuzione. - Ripristino dello stato: detto anche dispatch, carica il contesto del nuovo processo dal suo descrittore ai registri del processore.
Vedremo più a fondo che non sono i processi ad effettuare le azioni, ma i Soggetti.
I Soggetti sono composti da:
- Processo
- User ID
- Group ID
Inoltre, analizzeremo come gli ultimi due permettono di implementare i sistemi di protezione in sistemi multiutente.
I processi si dividono in:
- Processi Pesanti: è necessario descrivere sia lo stato di esecuzione che lo stato di tutto lo spazio di memoria.
- Processi Leggeri o Thread: è necessario descrivere solo lo stato di esecuzione.
La più grande differenza è il fatto che i processi pesanti hanno spazi di memoria non condivisi, mentre i thread lavorano su spazi di memoria condivisi. Se un processo pesante ha dei thread interni, questi condividono lo spazio di memoria tra di loro e con il processo pesante che li contiene.
2.5. Creazione e Terminazioni di Processi
Un processo, detto padre, può richiedere tramite apposite syscall la creazione di un nuovo processo, chiamato figlio, generando una gerarchia di processi. Le politiche di scelta di quale programma il processo figlio eseguirà (così come i dati e le risorse condivise) possono variare da sistema a sistemi.
Ogni processo è quindi figlio di un altro processo, e può essere a sua volta padre di altri processi.
L’OS mantiene nel descrittore le informazioni relative alle relazioni paternali.
Alla terminazione di un processo ci possono essre più politiche di segnalazione ai processi antenati.
Nei sistemi UNIX quando un processo figlio termina mentre il padre non è ancora terminato non entra nello stato terminato, ma in uno stato zombie.
Grazie a questo stato intermedio, il processo padre può rilevare la terminazione dei propri processi figli. Quando la terminazione di un processo figlio viene rilevata, questo effettivamente termina.
Inoltre, sempre in UNIX la terminazione di un processo padre comporta la terminazione di tutti i processi figli.
2.6. Processi concorrenti
Due processi si dicono concorrenti se le loro esecuzioni si sovrappongono nel tempo, o, più in generale:
Se la prima operazione di un processo avviene prima che termini l’ultima operazione dell’altro, generando fenomeni di interleaving (1 processore) o overlapping (più processori).
Possiamo definire anche i processi indipendenti:
Se il risultato prodotto dall’esecuzione di uno non è influenzato da quella di dell’altro, e viceversa.
Non consideriamo nella relazione di indipendenza l’influenza temporale, che è innegabile e non trascurabile, ma ci limitiamo a considerare solamente l’influenza logica, chiamando la relazione proprietà della riproducibilità.
Definiamo quindi i processi interagenti:
Se il risultato prodotto dall’esecuzione di uno è influenzato da quella dell’altro, e viceversa
In questo caso, la presenza di un altro processo può andare a modificare il risultato prodotto dal processo.
I processi possono quindi interagire per:
- Competizione: se due processi vogliono utilizzare risorse comuni che non possono essere utilizzate contemporaneamente, generando problemi di mutua esclusione. Questi problemi non sono risolti internamente al programma (dato che questo non sa nemmeno che esistano altri processi), ma vengono gestiti dal sistema operativo
- Cooperazione: se due processsi vogliono eseguire un’attività comune mediante scambio di informazioni
Il ruolo del kernel è quello di realizzare l’astrazione di CPU virtuale fornendo la possibilità di:
- Avere funzioni di risposta alle interruzioni
- Permettere il cambio di contesto tra i processi
3. Scheduling
È l’attività mediante la quale il sistema operativo effettua delle scelte tra i processi, riguardo al caricamento in RAM e all’assegnazione della CPU.
Vi possono essere tre diverse attività di scheduling:
- A breve termine: è lo scheduling propriamente detto. È la politica con la quale il sistema operativo assegna la CPU ai processi pronti.
Interviene quando il processo in esecuzione perde il controllo della CPU, e può essere di due tipi:
- Non preemptive scheduling (senza diritto di revoca): il sistema operativo non può revocare la CPU, ma deve essere lui a rilasciarla
- Preemptive scheduling (con diritto di revoca): il sistema operativo può forzare la revoca della CPU ad un processo in base a determiate variabili. (quanti di tempo, priorità, …)
- A medio termine: Si riferisce principalmente allo swapping, che permette di utilizzare la memrooia secondaria per trasferire temporaneamente i processi qualora la memoria principale non sia sufficiente per soddisfare le richieste di tutti i processi nel sistema
- A lungo termine: si occupa di scegliere quali programmi caricare in memoria centrale dalla memoria secondaria. Controlla quindi il grado di multiprogrammazione, ovvero quanti processi possono essere attivi contemporaneamente.
Lo scheduling di breve termine è invocato molto spesso (nell’ordine dei millisecondi), perciò deve essere molto veloce. Quello di lungo termine invece viene invocato nell’ordine di secondi se non minuti, perciò può essere meno efficiente.
Per comprendere meglio le differenze tra gli algoritmi di scheduling, descriviamo i processi come:
- Legati all’I/O: impiegano la maggior parte del tempo effettuando comunicazioni
I/Opiuttosto che occupare la CPU - Legati alla CPU: impiegano la maggior parte del tempo effettuando computazioni sulla CPU piuttosto che comunicare attraverso le periferiche
I/O
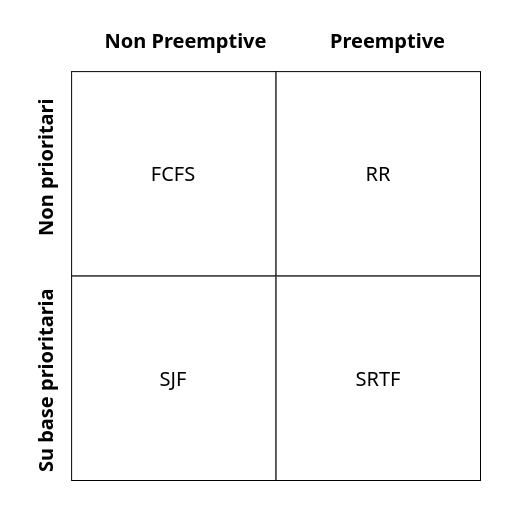
Gli algoritmi di scheduling che vedremo sono:
-
First-Come-First-Served
FCFS -
Shortest-Job-First
SJF -
Shortest-Remaining-Time-First
SRTF -
Round-Robin
RR
Questi possono essere classificati classificarli come sulla destra
Vedremo inoltre altre tecniche di schedulazione:
-
Schedulazione su base prioritaria
-
Schedulazione “a code multiple”
-
Schedulazione di sistemi in tempo reale
- Rate Monotonic
RM - Earliest Deadline First
EDF
- Rate Monotonic
3.1. Valutazione algoritmi di Scheduling
Definendo come $\Delta_{B_i}$ i CPU-Burst e come $\Delta_{a_i}$ i IO-Burst, possiamo valutare gli algoritmi secondo diversi parametri:
| Parametro | Formula | Valore Desiderato |
|---|---|---|
| Utilizzo della CPU | $E = \frac{\sum{\Delta_{B_i}}}{T}$ | Tendente a $1$ |
| Tempo medio di completamento (turnaround time) | $T_m = \sum{\Delta_{B_i}} + \sum{\Delta_{a_i}}$ | Il più piccolo possibile |
| Produttività (throughput rate) | $\frac{1}{T_M}$ | Il più grande possibile |
| Tempo di Risposta | $T_m = \sum{\Delta_{B_i}} + \sum{\Delta_{a_i}}$ | Minimizzato (coincide con il turnaround) |
| Tempo di Attesa | $A_m = \sum_i{\Delta_{a_i}}$ | Minimizzato |
| Rispetto dei Vincoli Temporali | - | Soddisfatto |
3.2. Algoritmo FCFS
È il più semplice tra gli algoritmi di scheduling della CPU.
Assegna la CPU al processo pronti in attesa da più tempo
Quando un processo entra nella coda dei processi pronti il suo descrittore viene collegato all’ultimo elemento della coda. Quando la CPU è libera viene assegnata al processo il cui descrittore si trova nella testa della coda.
È a tutti gli effetti equivalente alla politica FIFO.
La gestione della coda processi, mantenendo riferimenti alla cima e al fondo, ha quindi complessità:
- $O(1)$ per gli inserimenti
- $O(1)$ per le estrazioni
Uno schema per capire come funziona può essere il seguente:
Ipotizziamo i seguenti processi in arrivo:
| Processo | Tempo di Arrivo | CPU-Burst |
|---|---|---|
P0 |
0 | 10 |
P1 |
2 | 100 |
P2 |
4 | 24 |
P3 |
6 | 16 |
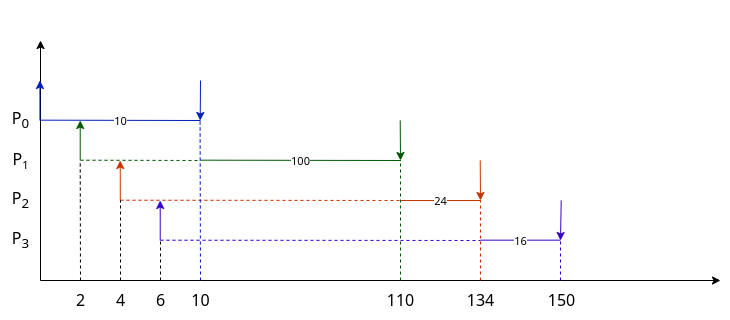
Grafico non in scala
Con questo algoritmo, in questo caso, abbiamo che:
| Parametro | Valore |
|---|---|
| $E$ | $\to 1$ (trascuro i cambi di contesto) |
| $T_m$ | $\frac{10 + (110-2) + (134-4) + (150 - 6)}{4} = 98$ |
| $A_m$ | $\frac{0 + (10 - 2) + (110 - 4) + (150-8)}{4} = 60,5$ |
Questo algoritmo è altamente dipendente dall’ordine nel quali i processi arrivano per quanto riguarda i tempi medi di attesa e di overhead.
Se infatti invertissimo l’entrata del processo P1 e del processo P3 otterremmo che $T_m = 56$ e $A_m = 18,5$.
Possiamo anche dedurre che questo algoritmo viene pesantemente deabilitato da processi con CPU-Burst grandi che arrivano prima di altri con CPU-Burst breve.
3.3. Algoritmo SJF
È un algoritmo a priorità statica non preemptive. La priorità viene assegnata ad ogni processo su base inversa rispetto al suo CPU-Burst, che per ora supponiamo noto.
Con lo stesso esempio di prima
| Processo | Tempo di Arrivo | CPU-Burst | Priorità |
|---|---|---|---|
P0 |
0 | 10 | 0 |
P1 |
2 | 100 | 3 |
P2 |
4 | 24 | 2 |
P3 |
6 | 16 | 1 |
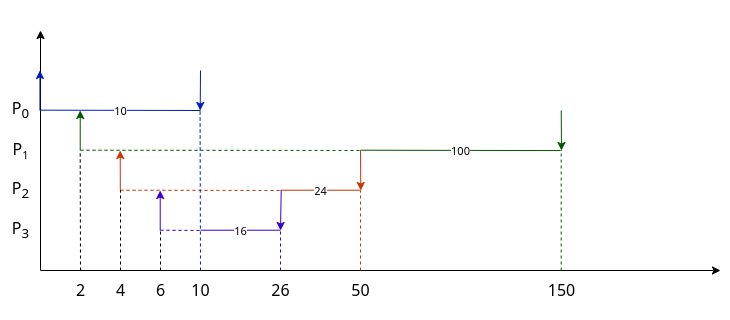
Grafico non in scala
Questo algoritmo, indipendentemente dall’ordine di arrivo, ordina i processi nel modo che abbiamo visto ottimizzava FCFS.
Tuttavia in questo algoritmo abbiamo più overhead.
Infatti l’inserimento in coda pronti è adesso un inserimento ordinato, perciò ha una complessità $O(n)$. Nel totale quindi sarà: $O(FCFS) + O(n) = O(1) + O(n) = O(n)$
Inoltre, essendo non preemptive, ha la limitazione che nel caso di arrivo di processi con elevati CPU-Burst prima di altri con tempi più bassi, ritorniamo nel problema di FCFS
3.4. Algoritmo SRTF
È un miglioramento di SJF, che introduce la possibilità di essere preemptive.
Inoltre, proprio per via della preemption, non si guarderà più la CPU-Burst iniziale del processo, ma quella che gli rimane da eseguire.
Infatti, nel caso un processo con CPU-Burst elevata (100) che però sta per finire (rimanente 2), non ha senso sostituirlo con un altro appena arrivato che magari ha CPU-Burst (50), che è sì più breve di quella iniziale ma molto più alta di quella rimanente.
| Processo | Tempo di Arrivo | CPU-Burst |
|---|---|---|
P0 |
6 | 10 |
P1 |
0 | 100 |
P2 |
4 | 24 |
P3 |
2 | 16 |
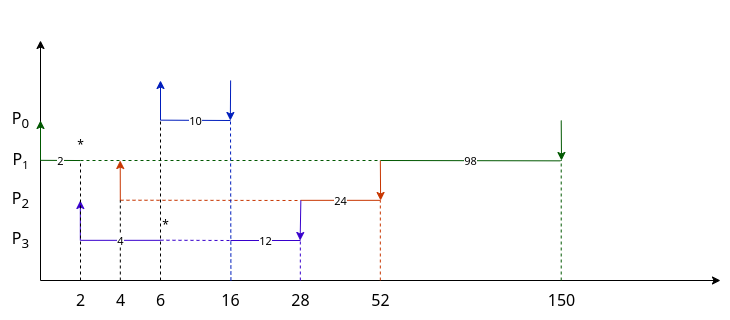
Grafico non in scala
È un sistema che funziona bene per sistemi statici, dove il numero di processi non varia e i loro CPU-Burst è noto, ad esempio sistemi embedded che hanno overhead bassissimo. Inoltre questo algoritmo, in caso di sistemi aperti con processi variabili, soffre di starvation. Infatti se arrivano continuamente processi con priorità più alta del primo, questo starà in attesa per un tempo che può diventare lunghissimo.
Per risolvere si utilizzano tecniche di aging, che monitorano i tempi di attesa e modificano opportunamente le priorità per rimediare alla starvation.
3.4.1. Stima della CPU-Burst
Non sempre sappiamo a priori il CPU-Burst di un processo. Si utilizza quindi la media esponenziale per stimarlo, tenendo conto della storia dei valori misurati nei precedenti intervalli di esecuzione:
\[\begin{align*} t_n &: \text{durata del CPU-Burst} \\ s_n &: \text{la sua stima} \\ a &: \text{fattore con } 0 \le a \le 1 \\ s_{n+1} &: at_n + (1-a)s_n \\ \end{align*}\;\]Al variare di $a$ abbiamo che:
- $a = 0$: tutte le stime sono uguali a quella iniziale $\to s_{n+1} = 0\cdot t_n + (1-0)s_n = s_n$
- $a = 1$: non si tiene conto della storia precedente $\to s_{n+1} = 1 \cdot t_n + (1- 1)s_n = t_n$
Tipicamente avremo che $a = \frac{1}{2} \to s_{n+1} = \frac{t_n + s_n}{2}$, performando di fatto una media artimetica tra l’effettiva durata del CPU-Burst e la sua stima.
3.5. Algoritmo RR
È un algoritmo progettato appositamente per i sistemi a partizione di tempo, rientrando negli algoritmi preemptive.
La coda dei proessi pronti è realizzata come una coda circolare, nella quale ogni processo ottiene la CPU per un quanto di tempo (tipicamente $10ms\sim100 ms$) al termine del quale perde il controllo della CPU e il suo descrittore viene inserito nella coda.
La coda viene gestita in questo caso con modalità FIFO (First-In-Fisrt-Out).
Prendendo questo esempio:
| Processo | Ordine della coda | CPU-Burst |
|---|---|---|
P0 |
1° | 100 |
P1 |
2° | 150 |
P2 |
3° | 10 |
P3 |
4° | 10 |
Con il quanto di tempo $Q = 20$ abbiamo la situazione mostrata sulla destra
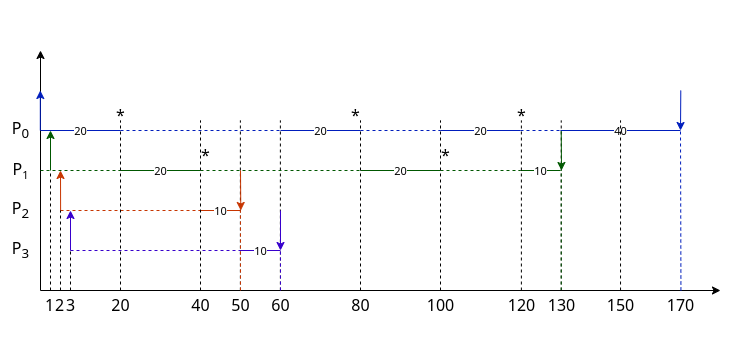
Grafico non in scala
È un algoritmo particolarmente adatto per i sistemi interattivi, in quanto è in grado di assicurare tempi di risposta abbastaza brevi, determinati esclusivamente da due fattori:
- Il quanto di tempo: il tempo di risposta è teoricamente migliore per piccoli valori del quanto di tempo. Tuttavia in questo caso non possiamo più ignorare il cambio di contesto tra processi. Infatti, cambi troppo frequenti comporterebbero un overhead che potrebbe addirittura diventare più grande del quanto stesso.
- Il numero medio di processi pronti: se fossero presenti tanti processi pronti, potremmo andare incontro a tempi di turnaround molto elevati, anche per processi con CPU-Burst molto brevi, che dovrebbero comunque attendere diversi cicli prima di poter terminare
Conoscendo il numero medio di processi in coda $n_m$, possiamo però calcolare il tempo di attesa massimo: \(A_m \le n_m \cdot Q\)
3.6. Sistemi Multi Level Queue
All’interno del nostro sistema non utilizzeremo solamente un algoritmo di scheduling, ma implementeremo un sistema che possiede più code, ognuna ordinata con un algoritmo diverso.
Ipotizziamo di avere 3 code ordinate con:
RR(10)RR(50)FCFS
Questo sistema introduce nuovi problemi:
- In quale coda inseriamo i nuovi processi?
- In quale coda inseriamo i processi al momento del’uscita dall’esecuzione
- Da quale delle code estraiamo il nuovo processo?
Per risolvere questi problemi assegnamo a ciascuna coda una priorità.
La logica che seguiremo sarà quindi la seguente:
- Lo scheduler controlla la coda con priorità più alta non ancora controllata
- Se è non vuota ne estrae un processo secondo l’algoritmo associato
- Se è vuota procede con la coda successiva
Come sempre, introducendo il concetto di priorità, introduciamo anche la generazione di problemi di starvation nelle code con priorità più bassa, tuttavia abbiamo anche visto come è possibile implementare processi di aging che permettono di aumentare la priorità di un processo, in questo caso cambandone eventualmente la coda.
Nell’assegnare le priorità ai processi viene spesso fatta una distinzione tra due gruppi di processi: interattivi (foreground) e batch (background).
Questi tipi di processi hanno tempi di risposta diversi, necessitando esigenze di priorità diverse:
- I processi interattivi sono caratterizzati da CPU-Burst brevi, supportando bene algoritmi
RRanche con intervalli piccoli, poiché tendono a terminare prima della fine della loro finestra sulla CPU. - I processi batch sono caratterizzati da CPU-Burst più grandi e prediligono algoritmi che effettuano meno scambi per unità di tempo.
Sarà uno dei compiti dello schedulatore quello di assegnare ad ogni processo la coda che lo rende più efficiente.
All’interno dei sistemi però non è noto a priori se un nuovo processo è batch o interattivo, perciò dobbiamo cercare di gestire dinamicamente queste code, implementando di fatto una Multi-Level Feedback Queue.
Il sistema operativo, alla creazione di un nuovo processo, lo inserisce nella coda di livello zero, ovvero in quella a priorità più alta. Un processo inserito in questa coda attenderà in media $\overline{N_0}\cdot 10$ unità di tempo prima di andare in esecuzione. ($\overline{N_i}$ indica il numero di processi per la coda $i$)
Se il CPU-Burst del processo fosse minore dell’intervallo di 10ms il processo può:
- Terminare: alché semplicemente si procede ad estrarne un altro
- Si sospende: il processo viene rimosso dalle code, per essere poi reinserito quando sarà di nuovo pronto
Se invece il CPU-Burst fosse maggiore, la preemption lo sostituisce e lo inserisce nella coda di livello 1.
Lo scheduler allora procede ad estrarre un nuovo processo sempre dalla coda 0.
Nel momento in cui questa fosse vuota (o per lo meno ci sia solamente il processo DUMMY_0), allora lo schedulatore procederà a estrarre dalla coda di livello 1.
Una stima del tempo medio di attesa di un processo nella coda 1 è $\overline{N_0} \cdot 10 + \overline{N_1} \cdot 50$. Ipotizzando che la coda di livello 0 sia vuota, attende “solamente” un tempo medio di $\overline{N_1} \cdot 50$.
Anche in questo caso il processo potrebbe andare in terminazione/sospensione, comportandosi analogamente a quando abbiamo fatto l’analisi per il livello 0.
Se il CPU-Burst rimanente fosse maggiore anche di 50ms verrà nuovamente sostituito dalla preemption, venendo inserito stavolta nella coda di livello 2.
Qui il processo attenderà non solo che le altre due code debbano essere vuote, ma che anche i processi inseriti precedentemente nella coda terminino. Questo tempo, per quanto non calcolabile, è certamente finito.
Nello studio fino a questo punto abbiamo però ignorato il fatto che il nostro sistema sia dinamico. Ciò comporta che con il passare del tempo si hanno costantemente nuovi processi in entrata nella coda di livello 0. Ciò comporta una starvation per le altre code a priorità minore, che si vedono sempre passare davanti i nuovi processi.
Nel caso del livello 1, l’algoritmo RR è di sua natura preemptive. Perciò alla creazione di un nuovo processo abbiamo già gli strumenti per effettuare preemption sul processo in esecuzione per reinserirlo nella sua coda, stando però attenti a mantenerlo allo stesso livello. Non dobbiamo infatti né penalizzare né premiare un processo perché ne è stato casualmente creato un altro durante la sua esecuzione.
Se invece stiamo eseguendo un processo P proveniente dalla cosa FCFS, che ricordiamo non implementa preemption, maggiore è il suo CPU-Burst, maggiore sarà il numero di nuovi processi che vengono inseriti nella coda RR(10), potendo arrivare persino a saturarla.
Per ovviare a questo problema, rendiamo la coda FCFS preemptive per l’inserimento dei nuovi processi. Anche in questo caso il processo rimarrà nella coda di livello 2, ma faremo attenzione ad inserirlo in testa. In questo modo, quando il sistema andrà a ripescare dalla coda a livello 2, il primo processo estratto sarà proprio quello al quale avevamo precedentemente revocato la CPU, senza penalizzarlo.
3.7. Schedulazione di sistemi in tempo reale
Gli algoritmi che abbiamo visto fin’ora, per quanto comunque funzionali, non si applicano bene a sistemi embedded dove dobbiamo soddisfare anche altri requisiti. I sistemi embedded infatti sono caratterizzati da un sistema operativo multiprogrammato che elabora parametri in tempo reale.
I sistemi in tempo reale possono essere rappresentati come sistemi con CPU, RAM, memoria flash e, soprattutto, due classi principali di periferiche: attuatori (output) e sensori (input).
In questi sistemi i sensori inviano periodicamente al sistema operativo misurazioni di dati che è necessario elaborare per poter produrre output agli attuatori.
Il periodo con il quale campioniamo i dati dipende dall’oggetto che stiamo misurando. I periodi di campionamento possono variare dall’ordine dei microsecondi (sistemi di bilanciamento, braccia robotiche, …) all’ordine dei secondi (misure di temperatura, pressione, …).
Proprio questa periodicità negli input è la prima caratteristica dei sistemi embedded, poiché di conseguenza anche i processi verranno generati periodicamente.
Possiamo quindi sviluppare il nostro sistema tenendo conto del fatto che gli input, e i relativi processi di elaborazione dell’input, sono periodici.
Dato un processo $i$ con periodo $t_i$, possiamo calcolare il prossimo inserimento in coda pronti in termini di quello precedente $r_j$:
\(r_{j+1} = r_j + t_i = r_0 + (j+1)\cdot t_i\)
Possiamo inoltre defire il CPU-Burst come la somma di $k_i$ CPU-Burst diversi \(C_i = \sum_{j=1}^{k_i}{C_i^{(j)}}\)
È tuttavia necessario che il turnaround del processo sia minore di $t_i$. In particolare vogliamo che termini entro una deadline $d_i < t_{i+1}$. Questo avviene perché i risultati che il processo produrrà devono essere trasmessi agli attuatori che dovranno quindi produrre cambiamenti opportunamente. Questo processo richiede del tempo, che identifichiamo proprio con l’intervallo tra $d_i$ e $t_{i+1}$. Tuttavia, esclusivamente per gli studi teorici possiamo considerare $d_i = t_{i+1}$.
Quello che abbiamo descritto è quindi un sistema composto da $N$ processi periodici, ovvero di un sistema periodico.
Possiamo quindi definire $T$ come il periodo del sistema nel suo complesso: \(T = mcm(t_i), \quad \forall i \in N\)
In un sistema hard real time lo scheduler deve garantire che tutte le deadline vengano rispettate, altrimenti si genera un errore fatale. In sistemi soft real time lo scheduler può permettersi che qualche deadline possa non essere rispettata senza la generazioni di errori fatali, ma andando incontro a brevi errori temporanei.
Avendo questa conoscenza aggiuntiva rispetto ai sistemi aperti, andiamo ad analizzare alcuni algoritmi di schedulazione.
3.7.1. Rate Monototic
È un algoritmo a priorità statica $\quad p(i) \propto \frac{1}{t_i}$
Esiste di due tipi, sia non preemptive che preemptive.
Vediamo il caso non preemptive
| Periodo | CPU-Burst massimo | |
|---|---|---|
Pa |
2 | 1 |
Pb |
5 | 1 |
Possiamo subito calcolare che la priorità di Pa sarà maggiore di quella di Pb.
Inoltre abbiamo che $T = mcm(t_i) = 10$
Sulla destra vediamo un esempio dell’evoluzione di questo sistema, ipotizzando che entrambi i processi siano già inseriti in coda pronti all’istante 0.
Notiamo come l’efficienza di questo sistema teorico sia al $70\%$. Il $30\%$ di tempo idle è tuttavia comodo per poter eseguire routine di sistema, gestire routine asincrone o fornire spazio di manovra per eventuali modifiche. Possiamo quindi ancora non considerarlo come un problema.
È banale notare che anche se avessimo dato la priorità proporzionalmente al periodo, questo esempio teorico sarebbe comunque schedulabile, mentre quello reale no. Infatti non sarebbe cambiato niente se non l’ordine di esecuzione nelle prime due unità. Il processo Pb sarebbe andato in esecuzione prima di Pa, che sarebbe entrato solamente solamente dopo la prima unità.
Questo avrebbe comportato che la terminazione della prima occorrenza di Pa sarebbe avvenuta in corsa con l’arrivo della seconda occorrenza, che nei sistemi reali è un problema.
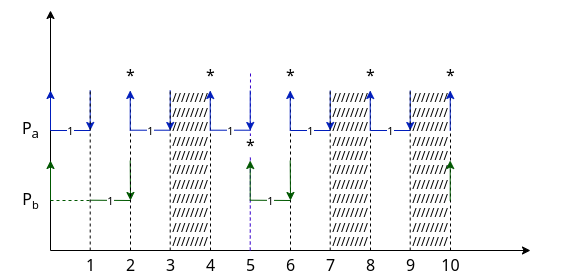
Le sezioni barrate sono le sezioni di CPU-idle.
Questo algoritmo è ottimo nella classe degli algoritmi a priorità statica. In particolare, esiste la proprietà che:
È possibile schedulare degli eventi a priorità statica se e solo se possiamo farlo tramite
RM.
3.7.2. Valutazione Esistenza dell’algoritmo
Fin’ora abbiamo quindi visto che abbiamo sistemi periodici di periodo $T$, composti da $N$ processi $i$ ognuno con periodo $t_i$ e CPU-Burst $C_i$. Come facciamo però a valutare che è possibie schedulare tutti i processi senza generare overflow?
La formula è abbastanza semplice, infatti: \(\begin{CD} { \sum_{i=0}^N{\underbrace{n_i}_{\text{frequenza}} \cdot C_i} \le T } @>>> { \sum_{i=0}^N{\frac{T}{t_i} \cdot C_i} \le T } @>>> \boxed{ \sum_{i=0}^N{C_i \over t_i} \le 1 } \end{CD}\)
Definiamo come Fattore di utilizzo della CPU: \(\quad U := \sum_{i=0}^N{C_i \over t_i}\)
Prendendo l’esempio precedente, otteniamo che il fattore di utilizzo: \(\quad U = \frac{1}{2} + \frac{1}{5} = \frac{7}{10} \le 1\)
Operativamente nella realtà la formula è leggermente diversa, dato che non possiamo far coincidere la deadline con il periodo, rendendo la formula reale qualcosa del genere: \(\quad U \le 1 - \alpha\)
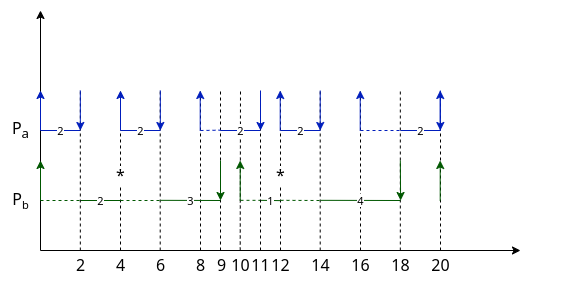
3.7.3. Earliest Deadline First
È un algoritmo preemptive a priorità dinamica. Questa viene calcolata per ogni processo in base alla vicinanza alla sua deadline.
Vediamo un esempio
| Periodo | CPU-Burst massimo | |
|---|---|---|
Pa |
4 | 2 |
Pb |
10 | 5 |
All’istante 0, p(Pa) > p(Pb) in quanto Pa ha la deadline prima di Pb.
Anche all’istante 4, sostituiamo il processo in esecuzione poiché Pa = 4 mentre Pb = 6.
All’istante 8 invece abbiamo che Pb = 2 < Pa = 4, e quindi manteniamo Pb in esecuzione.
All’istante 16 abbiamo che Pa = 4 == Pb = 4. La scelta che compiamo è quella di mantenere il processo in esecuzione.
4. Thread
Fin’ora abbiamo visto che un processo è sia un elemento che possiede risorse, sia un elemento al quale viene assegnata la CPU.
Ogni processo ha una spazio di indirizzamento distinto da quello degli altri processi. Questo dipende dalla tecnica di gestione della memoria adottata (pagine, segmenti, …).
In un sistema di processi concorrenti le operazioni di scambio possono generare overhead onerosi, comportando salvataggio e ripristino dello spazio di indirizzamento. Questo accade anche alla creazione e alla terminazione di un processo.
La separazione degli spazi di indirizzamento be favorsice sì l’utilizzo nei casi di interazioni basate sullo scambio di messaggi, ma rende complesso l’utilizzo di frequenti interazioni basate su strutture dati condivise.
Proprio per ottenere una soluzione a questi problemi è stata introdotta la separazione dei processi in due elementi:
- Thread (Processo Leggero): l’elemento al quale viene assegnata la CPU
- Task (Processo Pesante): l’elemento che possiede le risorse
Un thread rappresenta un flusso di esecuzione all’interno di un task. All’interno di un task è possibile definire più thread, attraverso tecniche di multithreading, ciascuno dei quali condivide le risorse del processo, risiedendo nello stesso spazio di indirizzamento e accedendo agli stessi dati.
Non possedendo risorse indipendenti (se non lo stack), i thread possono essere creati e distrutti più facilmente rispetto ai processi, così come ne è più semplice ed efficace il cambio di contesto.
A livello utente esistono delle librerie che permettono di strutturare un programma attraverso i thread in esecuzione parallela, permettendo i passaggi tra thread senza richiedere il supporto del sistema operativo.
Nei sistemi UNIX originali i programmi erano caratterizzati dal possedere un solo thread.
Nei sistemi Windows e Linux moderni, il kernel gestisce direttamente i thread, utilizzando al massimo le potenzialità di un sistema multiprocessore.
5. Processi in UNIX
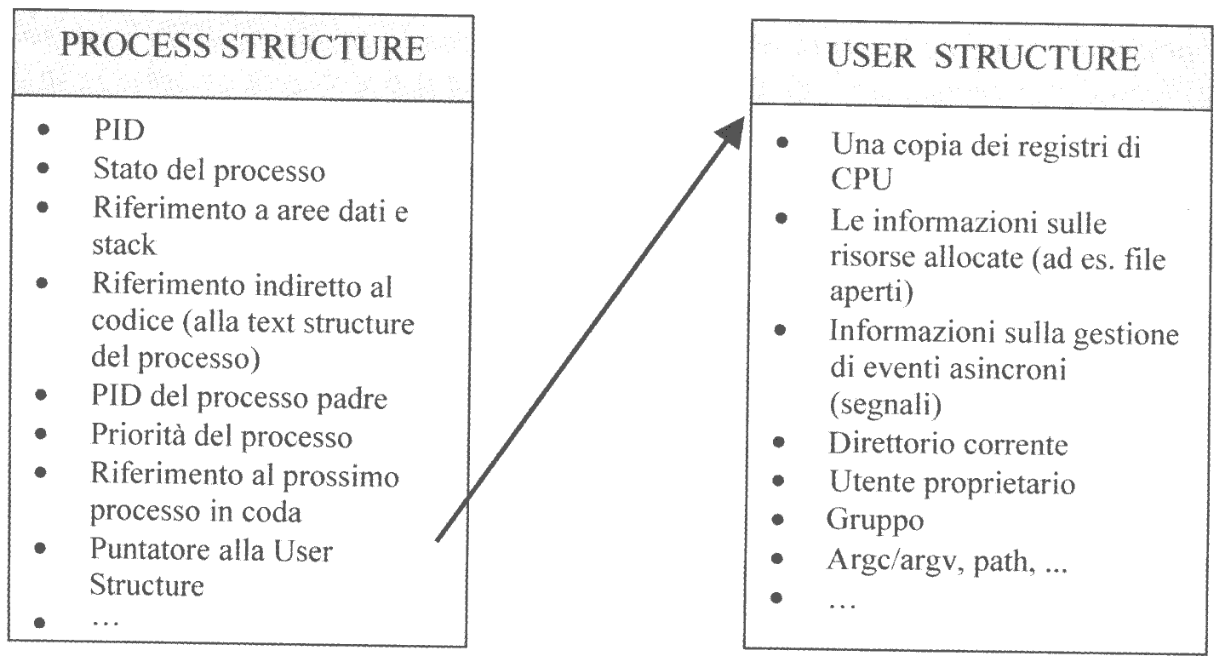
Il sistema UNIX suddivide le informaiozni tipicamente contenute nel PCB di un processo in due strutture dati distinte:
- Process Structure: contiene informazioni indispensabili per la gestione di un processo, anche se swapped. (non soggetta a swap-out)
- User Structure: contiene informazioni necessarie al sistema per la gestione del processo solamente quando esso è residente in memoria. (soggetta a swap-out)
Il codice dei processi UNIX si dice rientrante, ovvero può essere condiviso da più processi. Per permettere ciò, il kernel gestisce una struttura dati globale detta text table nella quale ogni elemento rappresenta il codice di un programma correttamente eseguito da uno o più processi.
In particolare, ogni elemento della text table è detto text structure e contiene un puntatore all’area di memoria in cui è allocato il codice.
Se il processo fosse swapped esso è un riferimento alla memoria secondaria.
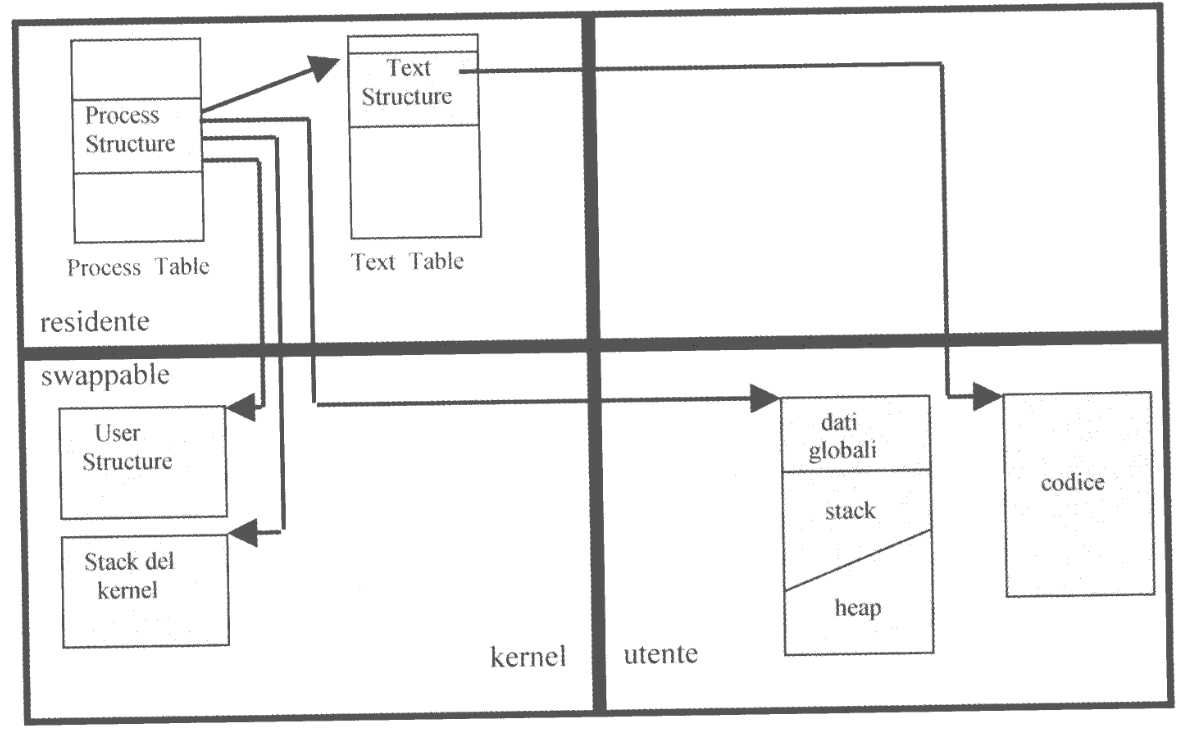
Una classificazione delle componenti in base alla visibilità (user/kernel) e alla possibilità di swapping (resident/swappable).