1. Indice
2. Funzionalità del Network Layer
Il network layer fornisce due funzionalità:
- Forwarding: dirige i pacchetti dall’ingresso del router all’uscita appropriata. Opera nel data plane
- Routing: determina la rotta dei pacchetti dalla sorgente alla destinazione. Opera nel control plane
Nel tragitto di un datagramma, il ruolo dei data plane di ciascun router intermedio è quello di inoltrare il datagrama dal link d’ingresso a quello di uscita mentre quelle del control plane è quello di coordinare le tante azioni di inoltro locali in modo che i datagrammi vengano instradati su percorsi di router tra mittente e destinatario.
2.1. Control Plane
Esistono due approcci per strutturare il control plane di una rete:
- Per-router control: è il metodo tradizionale
- Logically centralized Control: è alla base del Software Defined Networking (
SDN). Non la copriamo in questo corso
Nel caso del per-router control le componenti dezi singoli algoritmi di routing in ciascun router interagiscono nel control plane. Infatti le tabelle di routing sono frutto di un confronto continuo tra le altre tabelle di routing degli altri router.
3. Protocolli di Routing
L’obiettivo dei protocolli di routing è:
Determinare le rotte dall’host mittente all’host destinatario attraverso i router di rete.
Le rotte sono dei percorsi buoni, dove:
- Percorso: sequenza di router che i pacchetti devono attraversare dalla sorgente alla destinazione
- Buono: metrica relativa che può indicare diversi aspetti, il meno costoso, il più veloce, il meno congestionato, …
Il routing rappresenta una delle 10 sfide principali in ambito networking.
Per rappresentare una rete utilizziamo i grafi con la seguente notazione: \(G = (N, E) \longrightarrow \begin{cases} \begin{align*} N &: \text{insieme di routers (nodi)} = \{u, v, w, x, y, z\} \\[0.5em] E &: \text{insieme di links (archi)} = \{(u,v), (u, x), (v, x), (v, w), ...\} \end{align*} \end{cases}\)
Ogni link diretto da $a \to b$ ha associato un costo, per semplicità ipotizzato simmetrico, $c_{a,b} = c_{b,a}$. Se non esiste un link $x \to y$ allora assumiamo che $c_{x,y} = \infty$
Il costo è definito dall’operatore di rete: può essere $1$ (metriche per minimizzare il numero di hop), inversamente proporzionale alla banda (minimizzare la banda), inversamente proporzionale alla congestione (evitare la congestione), … La metrica utilizzata da sistemi low-power è quella che si basa sull’affidabilità dei link, ovvero al numero di ritrasmissioni medie richieste per ogni link.
Gli algoritmi di routing si dividono in quattro categorie principali, a seconda di come rispondano domande
- Quanto veloce cambiano le rotte
- Se utilizza informazioni globali o è centralizzato
I protocolli di routing che si basano su informazioni centralizzate sono gli algoritmi link state:
Tutti i router hanno conoscenza globale della topologia della rete, e conoscono il costo di ciascun link
Quelli che invece si basano su informazioni globali sono gli algoritmi distance vector
Ogni router conosce solo il costo diretto con i router direttamente collegati. Attraverso un processo iterativo di calcolo e scambio di informazioni con i vicini riesce a ottenere una conoscenza globale della rete
Per quanto riguarda gli algoritmi che cambiano velocemente le rotte abbiamo gli algoritmi dinamici:
Algoritmi che cambiano velocemente le rotte attraverso aggiornamenti periodici o in risposta a cambiamenti del costo del link
L’altro tipo di algoritmi sono gli algoritmi statici che invece cambiano le rotte lentamente
3.1. Algoritmi di routing link-state - Dikkstra
È un algoritmo centralizzato, dove tutti i nodi sono a conoscenza della topologia della rete, attraverso l’invio di messaggi link-state broadcast, attraverso i quali tutti i nodi ricevono le stesse informazioni.
L’algoritmo calcola il percorso dal costo minimo da un nodo sorgente a tutti gli altri, fornendo quindi la forwarding table per quel nodo.
È un algoritmo iterativo, dopo $k$ iterazioni si conoscono i $k$ percorsi a costo minimo per $k$ destinazioni diverse.
La notazione che utilizzeremo è la seguente:
- $c_{x,y}$: costo diretto $x \to y$. Se non sono vicini diretti allora $c_{x, y} = \infty$
- $D(v)$: stima corrente del costo del percorso dal costo minimo dalla sorgente alla destinazione $v$
- $p(v)$: nodo predecessore lungo il percorso dalla sorgente a $v$
- $N’$: indieme di nodi il cui percorso dal costo minimo è noto definitivamente
Un esempio di algoritmo può essere il seguente:
start:
N' = {u}
for all nodes v
if v adjacent to u
then D(v) = c_{u,v}
else D(v) = \infty
Loop:
find w not in N' such as D(w) is minimum
add w in N'
update D(v) for all v adjacent to w and v not in N':
D(v) = \min{(D(v), D(w) + c_{w,v})}
until all nodes in N'
Questo algoritmo deve essere eseguito da tutti i router.
Ipotizzando una rete con $n$ router, ognuna delle $n$ iterazioni deve passare per tutti i nodi $w$ non in $N’$.
Questo comporta l’effettuare $\frac{n(n+1)}{2}$ confronti, ovvero una complessità $O(n^2)$.
Se utilizziamo l’implementazione più efficiente, utilizzando lo heap, abbiamo comunque una complessità $O(n\log{n})$.
Inoltre dobbiamo anche prendere in considerazione che ogni router manda il broadcast le sue informazioni link state agli altri $n-1$ router. Algoritmi di boradcasr efficienti permettono di diffondere un messaggio con $O(n)$ attraversamenti di link. Il messaggio di ciascun router attraversa quindi $O(n)$ link, per una complessità complessiva di tutti i messaggi di $O(n^2)$.
Inoltre, se i costi dei link dipendono dal volume del traffico, è un algoritmo che soffre delle oscillazione delle rotte, dove ad ogni cambio del costo di un singolo link è necessario ricalcolare tutte le tabelle.
3.2. Algoritmi di Distance Vector
Quasti algoritmi si basano sull’equazione di Bellmam-Ford $BF$: \(D_x(y): \text{costo del least-cost path } x \to y \\ \Downarrow \\ D_x(y) = \min_v{c_{x,v} + D_v(y)} \quad \wedge \quad c_{x,v} \ne \infty\)
L’idea dell’algoritmo è quella di far inviare a ciascun nodo, occasionalmente, la propria stima del vettore delle distanze $D_v$ ai vicini.
Quando un nodo $x$ riceve nuove stime per il $D_v$ per qualsiasi vicino, aggiorna anch’egli il proprio $D_v$ usando l’equazione $BF$: \(D_x(y) = \min_v{c_{x,v} + D_v(y)} \quad \forally \in N\)
In codizioni normali la stima $D_x(y) \to d_x(y)$, ovvero all’effettivo least cost.
Uno pseudocodice:
wait(cambio costo link locale o messaggio da vicino)
D'_v stime di D_v usando i nuovi valori
if D'_v != D_v
D_v = D'_v
then notifica i propri vicini
Questo algoritmo iterativo è asincrono, infatti ogni iterazione locale è causata da cambi locali dei link vicini.
Ha un carico minore, poiché distribuito, ed è anche self-stopping poiché ogni nodo notifica i vicini solo quando il suo $D_v$ cambia.
I cambi di costi nei link possono avere due effetti diversi, a seconda che il costo di un link diminuisca o aumenti. Nel caso si abbia un miglioramento nel costo di un link, viene subito rilevato, aggiornando opportunamente il proprio $D_v$ e ritrasmettendolo ai vicini.
I vicini ricevono l’aggiornamento modificando il proprio $D_v$ calcolando il nuovo percorso a costo minimo e comunicando ai loro vicini i $D_v$.
Quando $y$ riceverà gli aggiornamenti dai propri vicini, il suo costo minimo non varierà e $y$ non invierà altri messaggi.
In questo modo con soli 3 comunicazioni i nodi hanno ricevuto tutte le informazioni.
Se invece si avesse un peggioramento il primo nodo $y$ rileva un cambiamento, ma sa che uno dei nodi vicini $z$ ha un costo minore del cambiamento. Questo costo inferiore però potrebbe passare proprio dal link che adesso è peggiorato. Notifica quindi il peggioramento inviando il valore del proprio vicino più il costo per arrivare dal vicino. A questo punto però il vicino $z$ aggiornerà il percorso per arrivare alla destinazione, consco del fatto che il vecchio miglior percorso adesso è peggiorato di $c_{y,z}$ e ritrasmetterà questo valore. E così via finché non otterremo il valore desiderato.
Per risolvere questo problema, chiamato count-to-infinity, si utilizza la tecnica dell’ inversione avvelenata.
Quando un nodo $z$ instrada verso $x$ passando da $y$, notificherà $y$ che la sua distanza verso $x$ è infinita, così da evitare problemi relativi alle modifiche dei link di $y$. In questo modo $y$ pensa che $z$ non abbia un percorso verso $x$, e non creerà il ciclo di scambio tra i nodi adiacenti.
Questa tecnica funziona però solamente per risolvere cicli che si formano tra nodi adiacenti.
3.3. Confronto Link-State e Distance-Vector
| LS | DV | |
|---|---|---|
| Complessità dei messaggi | $n$ router, $O(n^2)$ messaggi inviati | Scambi tra vicini, con un tempo di convergenza variabile |
| Velocità di convergenza | Algoritmo $O(n^2)$, $O(n^2)$ messaggi. Susciettibile a oscillazioni |
Tempo di convergenza variabile per via di cicli o per il problema del count-to-infinity se non è predisposta l’inversione avvelenata |
| Robustezza (rottura e/o compromissione dei router) |
I router possono comunicare costi di link errati. Ogni router costruisce solo la propria tabella |
È possibile comunicare costi di percorsi non corretti (black-holing). Se ogni $D_v$ di ogni router è usato anche dagli altri, l’errore si propaga nella rete |
4. Routing Scalabile
Fin’ora abbiamom fatto una trattazione sul routing puraemntepuramente teorico, dove tutti i router sono uguali e la rete è “piatta”.
Nella realtà invece abbiamo miliardi di destinazioni, non possiamo quindi salvare tutti gli indirizzi nelle tabelle di routing, poiché, oltre a necessitare un ingente disponibilità di memoria, il loro scambio ingolferebbe i collegamenti.
DObbiamo quindi pensare ad alcuni approcci di scalabilità che permettano comunque un autonomia amministrativa all’interno delle singole reti.
L’approccio generale aggrega i router in regioni chiamate Autonomus Systems (AS), detti anche domains.
Si parlerà quindi di:
- Routing intra-AS: per il routing all’interno di un
AS, dove tutti i router devono eseguire lo stesso protocollo di routing. TraASdiversi possiamo avere protocolli di routing intra-domain diversi. È presente un gateway-router che permette la comunicazione traASdiversi - Routing inter-AS: È il protocollo seguito dai gateway per il routing inter-domain
Per AS interconnessi, la tabella di inoltro è configurata dagli algoritmi di routing:
- intra-AS: determina le entrate per le destinazioni dentro l’AS
- inter-AS e intra-AS: determina le entrate per le destinazioni esterne all’AS
Il sito bgp.he.net permette di recuperare informazioni sugli AS
4.1. Intra-AS routing
Supponiamo di avere un router in AS1 che riceve un datagram con destinazione esterna a AS1, il routing inter-domain deve fare due cose:
- Capire quali sono le destinazioni che si possono raggiungere attraverso gli
ASadiacenti - Propagare queste informazioni di raggiungibilità per tutti i router in
AS1.
I protocolli di routing intra-AS più comuni sono:
- Routing Information Protocol (
RIP): descritto in[RFC 1723]utilizza il classico distance vector scambiandoli ogni 30 secondi - Enhanced Interior Gateway Routing Protocol (
EIGRP): è anch’esso basato suiDVed è stato proprietario diCiscoper decenni fino al 2013 quando diventò open[RFC 7868] - Open Shortest Path First (
OSPF): descritto inRFC 2328, è un link-state routing. Non è standardRFCma è lo standardISO, identico aIS-IS protocol.
Il protocollo OSPF si basa sul link-state classico, ogni router invia a tutti degli OSPF link-state advertisements direttamente su IP a tutti gli altri router nell’AS, conoscendo la topologia e calcolando la tabella di forwarding attraverso l’algoritmo di Dikstra.
Il costo di un link si basa su diverse metriche (bandwidth, delay, …).
I messaggi OSPF sono autenticati.
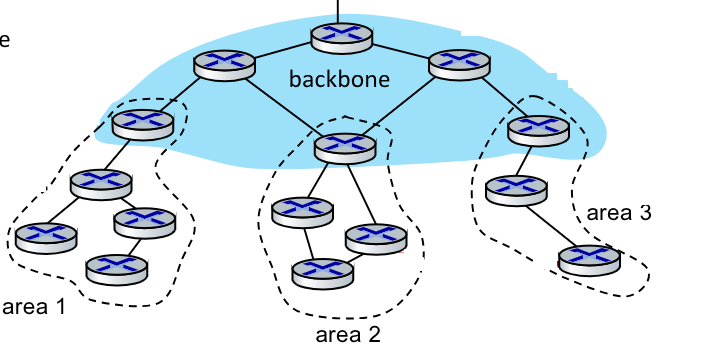
Il protocollo può essere gerarchico:
Nell’esempio sulla destra possiamo vedere la gerarchia a due livelli:
- Local Area
- Backbone
I link-state advertisements sono inviati solamente nella backbone.
Il gateway router si è in “cima” alla backbone.
I backbone router eseguono OPFS nella backbone.
In particolare gli Area border routers hanno le distanze per le destinazioni nella loro stessa area (local routers), comunicandole alla backbone.
I local routers inviano LS soo nella propria area, calcolando il proprio routing e inoltrando pacchetti all’esetrno attraverso il border router.
4.2. Inter-AS routing - BGP
Il protocollo standard per i protocolli di routing inter-domain è il Border Gateway Protocol BGP.
Consente ad una sottorete di pubblicizzare la sua esistenza al resto di Internet.
Il protocollo fornisce quindi ad ogni AS un mezzo per:
- Ottenere informazioni sulla raggiungibilità delle reti di destinazioni di
ASvicini, attraverso l’external BGP (eBGP) - Determinare le rotte per altre reti basandosi su informazioni di raggiungibilità e policy
- Propagare informazioni di raggiungibilità a tutti i router nell’
AS, attraverso l’internal BGP (iBGP) - Pubblicizzare alle reti vicine le informaizoni di raggiungibilità delle destinazioni
In una BGP session due router BGP si scambiano messaggi BGP su connessioni TCP semi-permanenti, con i quali pubblicizzano i path verso diverse sottoreti di destinazione che sono in grado di raggiungere.
I massaggi BGP (descritti in [RFC 4371]) pricipali sono:
OPEN: apre una connessioneTCPcon il peerBGPremoto e autentica il perrBGPmittenteUPDATE: pubblicizza un nuovo path o ne rimuove un nuovo vecchioKEEPALIVE: tiene la connessione viva in assenza diUPDATES, è utilizzato anche comeACKallaOPENreqeust.NOTIFICATION: riporta errori precedenti. È utilizzato anche per chiudere le connessioni.
Per pubblicizzare una rotta si costruisce un messaggio che segue il formato:
- Prefisso Sottorete: destinazione pubblicizzata
- Attributi: due attributi importanti sono:
AS-PATH: lista degliASper i quali è passata la pubblicizzazione del prefissoNEXT-HOP: indica l’indirizzo di un’interfaccia del gateway router in unASper andare a quello adiacente in un altroAS.
Nel routing basato su policy il gateway che riceve la pubblicazione di una rotta utilizza import policy per accettare o declinare la rotta. Inoltre, utilizza la policy anche per deterinare se e quando pubblicizzare un percorso agli AS vicini.
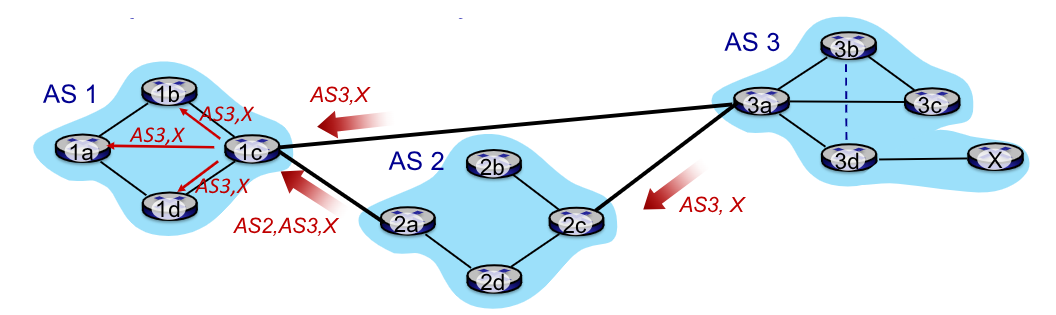
Il router 1c di AS1 riceve tramite eBGP entrambe le rotte, ma basandosi su una policy decide di pubblicizzare via iBGP il percorso AS3, X.
Nell’immagine sopra i router di AS1 conoscono tramite iBGP il percorso per X che passa da 1c.
Per il router 1d andrànno inseriti i record <1c, 1>, attraverso routing OSPF intra-domain e <X, 1> (ipotizzando che l’interfaccia 1 sia quella che lo collega corretta).
Un local router, quando deve scegliere un gateway per inoltrare verso l’esterno un pacchetto sceglie quello che ha costo intra-domain minore, indipendentemente dal numero di AS che questo poi attraverserà, in un processo chiamato Hot Potato Routing.
BGP permette inoltre di soddisfare le policy con pubblicazione.
Infatti un ISP potrebbe volere inoltrare il traffico solo da/verso le reti dei suoi client.
I router possono quindi conoscere più di una rotta per AS di destinazione, applicando le regole in ordine:
- Policy: preferenze locali date dai valori di alcuni attributi
- Shortest
AS-PATH - Hot Potato Routing scelta del
NEXT-HOProuter più vicin - Altro
4.3. Intra-AS vs. Inter-AS
I due protocolli sono diversi per i seguenti motivi:
| Inter-AS | Inter-AS | |
|---|---|---|
| Policy | Gli amministratori voglino il controllo su come il traffico viene instradato e su chi può instradare attraverso la propria rete | Si ha un amministratore singolo |
| Prestazioni | La policy è più importante delle prestazioni | Si può concentrare sulle prestazioni |
Inoltre il routing gerarchico riduce la dimensione delle tabelle, riducendo gli update da mandare.