1. Indice
- 1. Indice
- 2. Introduzione
- 3. Servizi e Funzionalità del data link
- 4. Point to Point Protocol (
PPP) - 5. Multiple Access Protocol
- 6. Local Area Network -
LAN
2. Introduzione
Vedremo adesso come i dati sono trasferiti tra noti adiacenti.
Le reti a connessione diretta sono il più semplice tipo di connessione tra host, e consiste nella connessione attraverso un link fisico. Tuttavia, il link fisico non è intrinsecamente affidabile, in quanto può generare degli errori nella trasmissione dei dati. Vedremo quindi delle tecniche che rendono la comunicazione su questo link inaffidabile, affidabile. Successivamente indagheremo su come ampliare questi concetti a reti più ampie.
Un link fisico permette la trasmissione di bit di dati attraverso l’invio di segnali (elettrici, eletromagnetici o ottici) che lo attraversano. È connesso a dei trasmettitori/ricevitori che permettono di effettuare le codifiche/decodifiche tra segnali fisici e bit logici attraverso protocolli specifici.
Quando diciamo che i link sono inaffidabili, è proprio a causa del fatto che vengono trasmessi segnali fisici. Questi infatti possono andare incontro a diversi effetti esterni che li disturbano (attenuazioni di segnali, noise, interferenze, fading, ….). È quindi possibile che i segnali vengano alterati durante la trasmissione, rendendo la traduzione del ricevitore diversa da quella inviata originalmente.
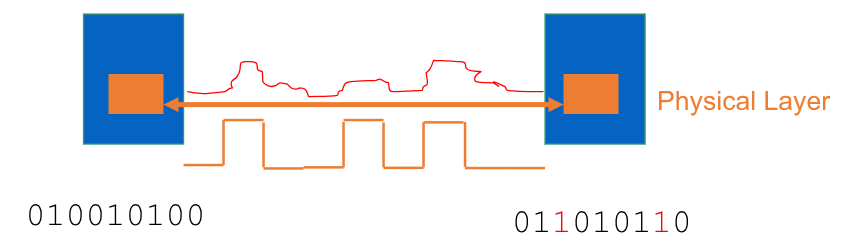
La quantità di errori verrà misurata attraverso il bit-error-rate, che misurerà l’affidabilità di un link
Sarà quindi necessario introdurre una serie di servizi che permetteranno di rendere le comunicazioni più affidabili. Questi servizi sono implementati al livello data link.
3. Servizi e Funzionalità del data link
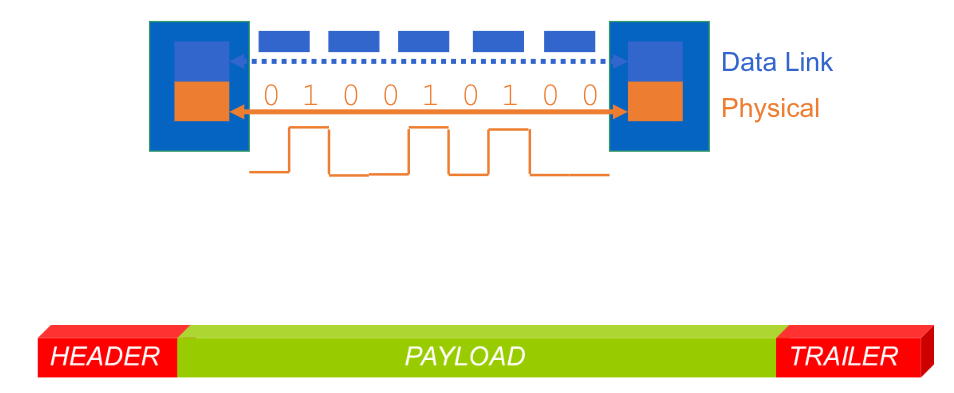
Uno dei servizi che introduciamo è il framing. Questo servizio incapsula il datagramma all’interno di più frames/trame.
Ogni frame è incapsulato in due informazioni di controllo, che forniscono informazioni sul singolo frame per permettere al ricevitore di ricostruire correttamente il frame:
- Header: contiene diverse informazioni sul frame
- Payload (contenuto)
- Trailer: contiene altre informazioni sul frame
Questo servizio comporta un maggiore overhead, tuttavia permette di diminuire la probabilità di errore. Nel caso di messaggi grossi, per qualsiasi invio si ha la quasi certezza che arrivi corrotto. Se invece dividiamo il grosso messaggio in più frame più piccoli la probabilità complessiva che il messaggio sia corrotto rimane la stessa se non aumenta (a causa di header e trailer), ma quella che un singolo messaggio lo sia diminuisce drasticamente. Possiamo quindi limitarci a chiedere il reinvio dei frame corrotti, diminuendo quindi la probabilità complessiva di errore.
Gli altri servizi che vedremo saranno quindi:
- Rilevazione di errore: permettono al ricevitore di rilevare errori durante la comunicazione
- Correzione dell’errore: il ricevitore identifica e corregge gli errori
- Ritrasmissione: il ricevitore segnala quali frame sono stati corrotti, e il trasmettitore li invia nuovamente
- Controllo del flusso: permette di controllare la velocità di trasmissione tra due nodi che comunicano
- Half-duplex: due nodi possono trasmettere sullo stesso link, ma solo uno alla volta
- Full-duplex: due nodi possono trasmettere sullo stesso link anche simultaneamente
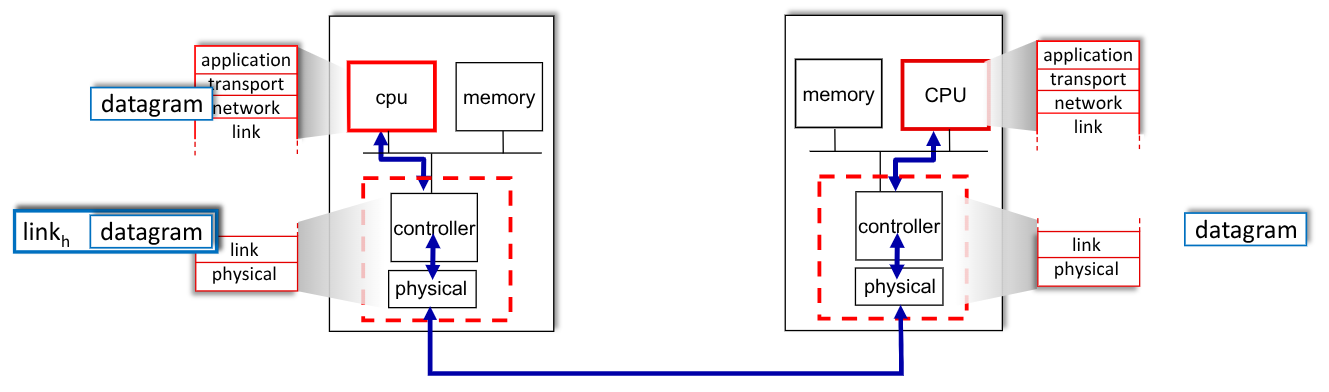
Il link-layer si trova all’interno di tutti gli host. È implementato nel NIC (Network Interface Card) sui chip, che implementano il physical layer.
Il NIC si attacca al bus dell’host di sistema, ed opera sfruttando una combinazione di hardware, software e firmware.
Durante una trasmissione la parte che invia si occupa di incapsulare il datagrama in frames e aggiunge gli header/trailer inserendovi error-checking-bits, reliable-data-transfer, flow-control, …
Il ricevitore controllerà che non vi siano errori e, in caso positivo, estrarrà il datagramma fornendolo al layer superiore.
3.1. Error Detection
Definiamo:
R: Ridondanza, bit di controllo aggiuntivi che permettono l’error detectionD: Dati Protetti, bit mantenuti dall’error checking (potrebbero includere i file di header)
Prima di iniziare cominciamo subito dicendo che non esiste un sistema di error detection efficace al 100%. Nonostante ciò, i vari protocolli che vedremo possono comunque non prevenire qualche errore, ma accade raramente. Vedremo inoltre che la probabilità di individuare un errore e correggerlo aumenta all’aumentare dei bit R, così come la probabilità che R stesso sia corrotto.
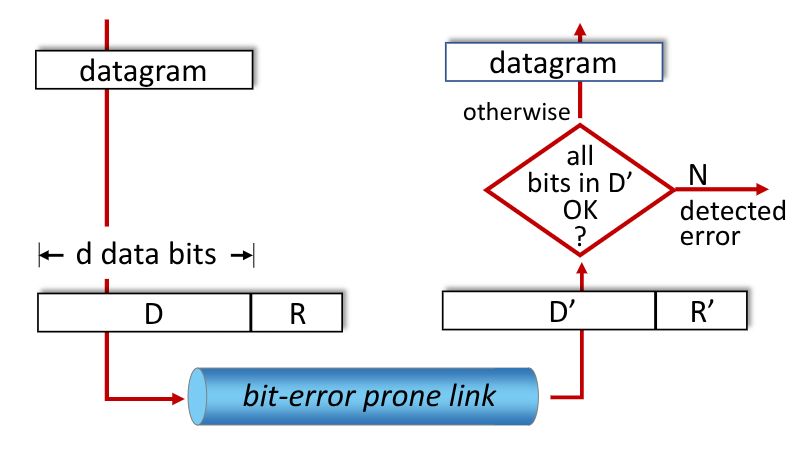
La sfida del ricevitore è valutare se D' e D coincidono, valutando R' (anch’esso potenzialmente corrotto)
Vediamo quindi tre tecniche per rilevare errori nei dati.
3.1.1. Parity Checking
È probabilmente la forma di error detection più semplice.
Permette di scovare errori nel messaggio attraverso un singolo parity bit P.
Ciò significa che in un messaggio di $d$ bit, il messaggio finale sarà di lunghezza $d+1$ bit.
Questo bit è codificato così:
Even Parity: Se il numero di
1all’interno del messaggio è dispari alloraP = 1, altrimentiP = 0
Odd Parity: Se il numero di1all’interno del messaggio è dispari alloraP = 0, altrimentiP = 1
In parole povere, rende pari/dispari il numero di 1 all’interno del messaggio.
Il trasmettitore dovrà semplicemente contare il numero di bit settati all’interno del messaggio per valutarne la correttezza.
Si vede subito che questo metodo, per quanto semplice, è fallace in caso di errori multipli in numero pari sul singolo messaggio.
Nel caso infatti di 01101|1 $\to$ 11111|1 non verrebbe rilevato alcun errore in quanto in entrambi i casi il numero di bit settati è pari.
Se è vero che la probabilità di errore su un bit è bassa, quella che più bit consecutivi lo siano dovrebbe essere ancora più bassa. Tuttavia, vari esperimenti hanno mostrato che gli errori hanno la tendenza di raggrupparsi in gruppo. Varie misurazioni hanno stimato che la probabilità di errore con questa tecnica è vicina al $50\%$.
3.1.2. Metodi di Checksum
Nelle tecniche di checksum i D bit sono trattati come una sequenza di interi ognuno su $k$ bit.
Uno dei più semplici metodi di checksum è quella di sommare questi $k$ interi e utilizzare il controllo con la somma come metodo di error-detection.
Il metodo di checksum utilizzato da internet si basa su questo approccio, trattando i byte come interi su 16bit.
Il complemento a 1 di questa somma forma l’Internet Checksum trasportato dall’header.
Il ricevitore controllerà anch’egli il checksum e lo confronterà con quello ricevuto.
Questo algoritmo è spiegato in dettaglio all’interno del RFC 1071.
È più sicuro del semplice parity checking ma meno dei CRC, tuttavia è ampiamente utilizzato anche su Internet proprio per la sua elevata semplicità computazionale.
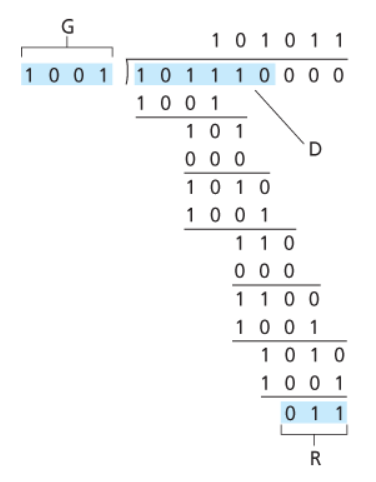
3.1.3. Controlli di Ridondanza Ciclica - CRC
Il CRC (Cycilc Redundancy Check) è l’algoritmo di error detection più potente.
Introduciamo un nuovo parametro:
G: Generator, bit pattern dato di $r+1$ bit tale per cui ilMSD = 1
L’obiettivo di questo algoritmo è di scegliere $r$ CRC bit R tali che $\langle D, R\rangle = D\cdot 2^r \text{XOR} R$ sia esattamente divisibile per G in modulo 2.
In altre parole: \(D \cdot 2^r \text{ XOR } R = nG \\ D \cdot 2^r = nG \text{ XOR } R\)
Possiamo vedere di lato un semplice calcolo con:
D = 101110,d = 6G = 1001,r = 3
Per valutare R utilizziamo la seconda equazione ottenuta:
\(D \cdot 2^r = nG \text{ XOR } R\)
Ed effettuiamo la divisione $D \cdot 2^r \over G$. Il resto di questa operazione sarà proprio R, mentre il quoziente sarà n.
La sequenza trasmessa sarà quindi: <D, R> = 101 110 011
Sono stati definiti standard internazionali per generatori a 8, 12, 16 e 32 bit, con lo standard CRC-32 a 32bit, utilizzato nella maggior parte dei protocolli a livello link, che utilizza il seguente generatore:
GCRC-32=100000100110000010001110110110111
Ogni standard CRC permette di rilevare errori di bit consecutivi per gruppi inferiori a r+1 bit
3.2. Error Correction
Sono algoritmi che permettono non solo di identificare se c’è stato un errore, ma di individuarlo e correggerlo.
3.2.1. 2-Dimension Parity Check
Un modo per migliorare il parity checking è introdurre un 2-dimention parity checking. Invece di valutare i messaggi come un array lineare, li rendiamo un array bidimensionale quadrato. A questo punto effettuiamo il parity check sia sulle colonne che sulle righe.
In questo modo possiamo non solo individuare gli errori sui singoli bit, ma anche localizzarli nella griglia e correggerli.
Permette inoltre di migliorare significatamente la probabilità di rilevare errori multipli, ma non sempre si riesce a correggerli.

3.3. Reliable Data Transfer
Dobbiamo riuscice a implementare un livello tra il link inaffidabile e i sender/receiver per rendere affidabile la trasmissione dei pacchetti.
Definiamo quindi il protocollo rdt (Reliable Data Transfer), eseguito al livello sottostante al sender/receiver per rendere il canale di comunicazione affidabile.
Le interfacce di questo protocollo sono:
rdt_send(): chiamata dall’alto. Passa i dati da trasferireudt_send(): chiamato dal protocolo per trasferire i datirdt_rcv(): chiamato dal protocolo quando arriva il pacchetto dal lato del ricevitore che fa da ricevitoredeliver_data(): chiamato dardtper fornire i dati al layer soprastante
Il protocollo avrà “impacchettato” i dati con l’header di protezione durante l’invio, e lo avrà rimosso durante la ricezione, senza che i due interpreti ne siano a conoscienza.
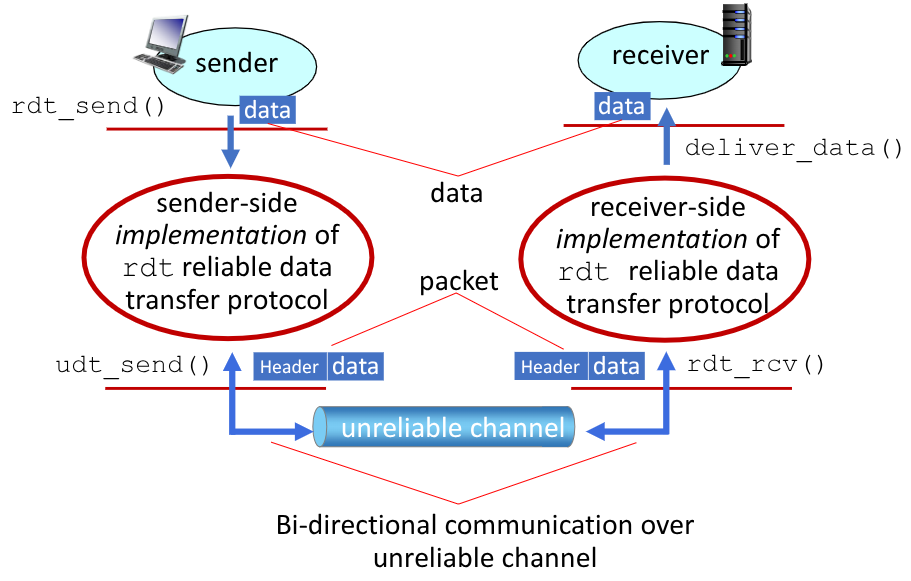
Svilupperemo questo protocollo in maniera incrementale, in maniera chiara e non ambigua, basandoci su alcune assunzioni:
- Consideremo solamente trasferimenti unidirezionali, permettendo però il controllo in entrambe le direzioni.
- Per specificare i mittenti e i destinatari utilizzeremo le macchine e stati finiti (già viste e ampiamente utilizzate nel corso di Reti Logiche).
3.3.1. rdt1.0
Facciamo le seguenti ipotesi per capire come funziona la macchina a stati finiti:
- Il canale sottostante è perfettamente affidabile
Svilupperemo due macchine a stati finiti:
- Per il trasmettitore: che invia i dati sul canale sottostante
- Per il ricevitore che legge i dati dal canale sottostante
Avremo quindi le seguenti macchine e stati finiti:

3.3.2. rdt2.0 e rdt2.1
Ipotizziamo adesso che il canale sottostante possa invertire bit in gruppi.
È quindi adesso necessario introdurre dei bit di ridondanza (CRC o checksum, sceglieremo il secondo per comodità) per rilevare gli errori.
Dobbiamo però adesso scegliere un modo per gestire gli errori. Abbiamo più modi:
ACKs(ACKnowledgements): il ricevitore informa esplicitamente il trasmettitore che il pacchetto ricevuto èOKNAKs(Negative AcKnowledgements): il ricevitore informa esplicitamente il trasmettitore che il pacchetto ricevuto presenta errori
Quando il trasmettitore riceve un NAK procede a ritrasmettere il pacchetto incriminato.
Questo protocollo segue una politica di stop-and-wait. Infatti il trasmettitore, dopo aver inviato un pacchetto, attende il messaggio del ricevitore prima di procedere con il successivo invio.
Le due macchine a stati finiti per questo protocollo sono le seguenti:
Trasmettitore
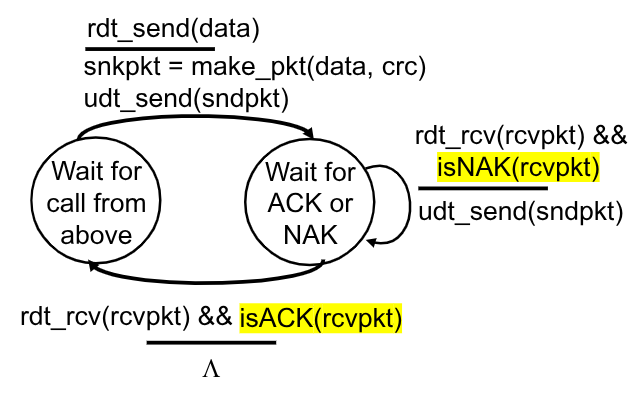
Ricevitore
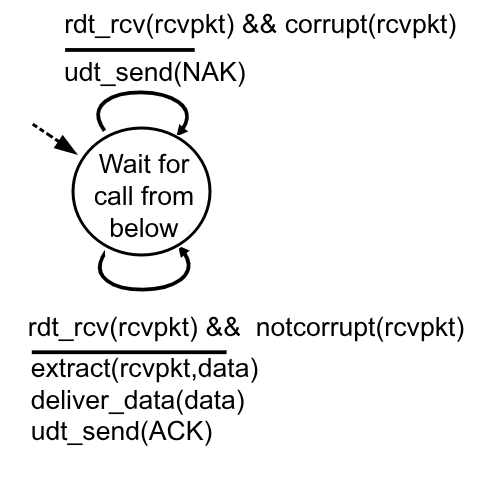
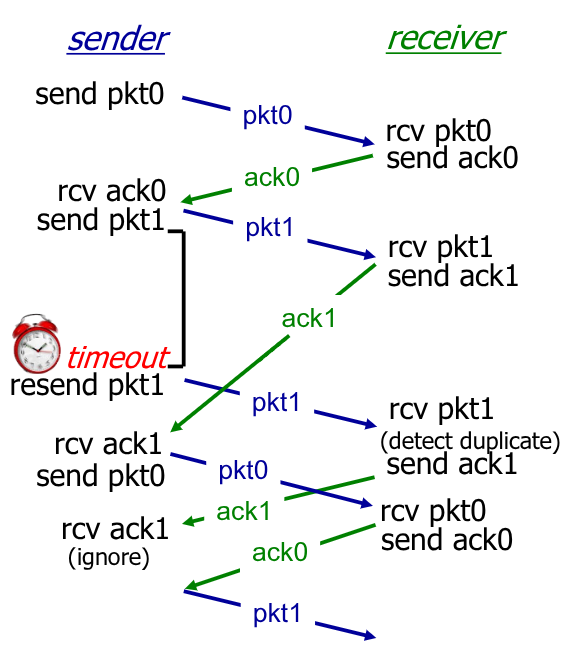
Questo tipo di protocollo ha però un punto debole. Che succede se l’ACK/NAK viene corrotto nell’invio?
Il trasmettitore non avrebbe idea dello stato del ricevitore, e la mera ritrasmissione potrebbe provocare dei duplicati.
È quindi necessario che il trasmettitore aggiunga un sequence number che specifica il numero del pacchetto nel messaggio. In questo modo, qual’ora il ricevitore ricevesse un duplicato riesce ad identificarlo scartandolo.
Le macchine a stati finiti si complicano:
Trasmettitore
Ricevitore
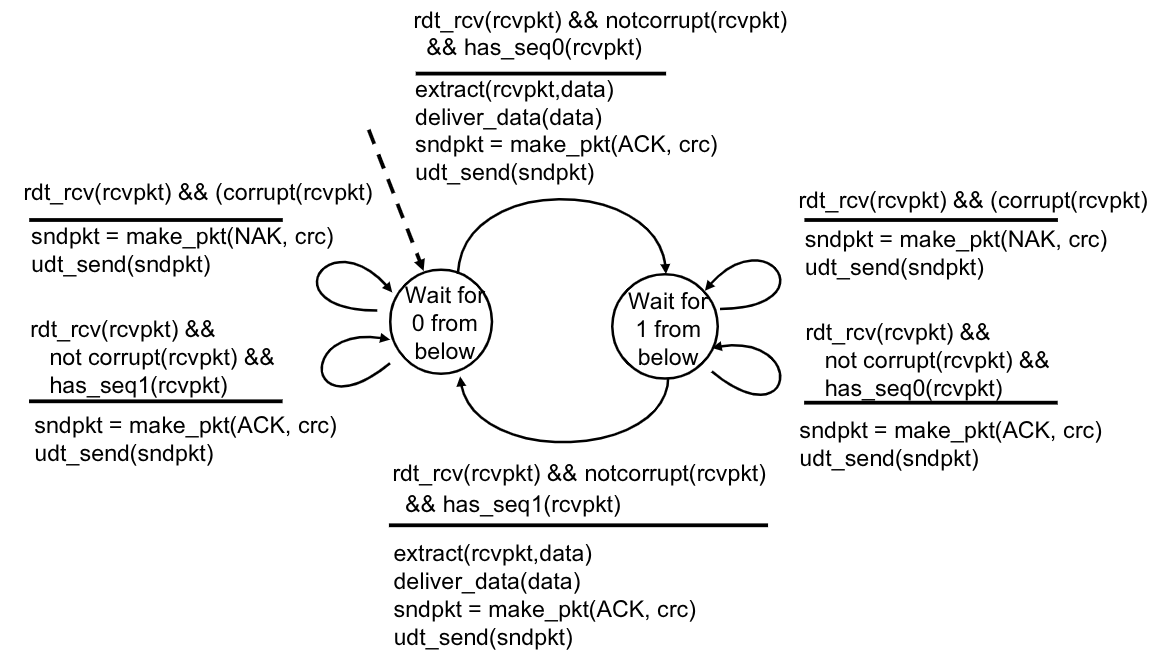
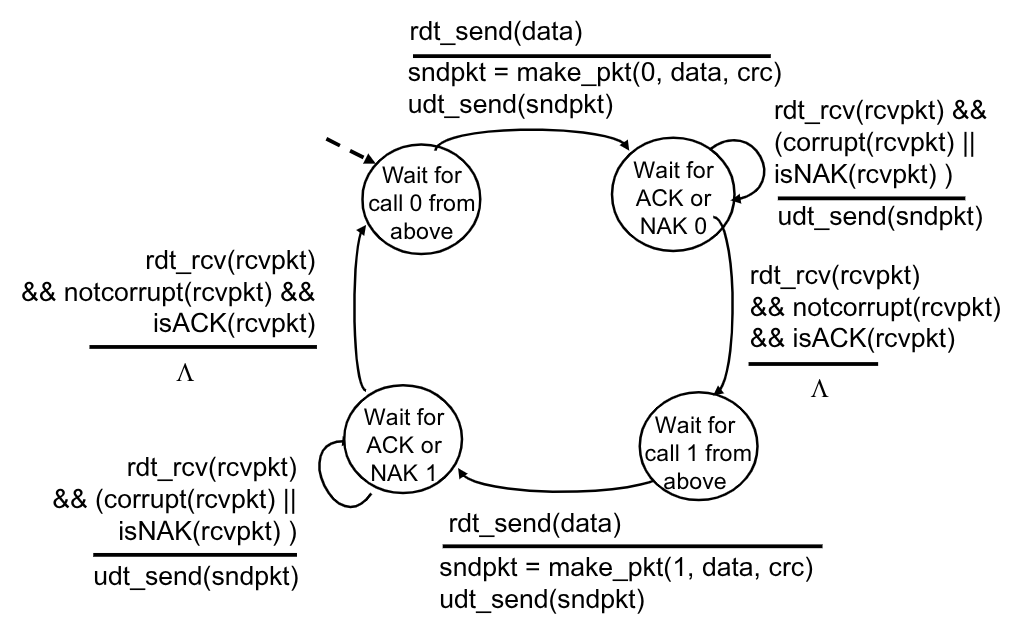
Il trasmettitore adesso aggiunge ai vari pacchetti un numero di sequenza che ne indica la posizione. In realtà per implementare questa funzionalità è sufficiente un solo bit. Questo bit verrà invertito dopo l’invio di ogni pacchetto. Se il trasmettitore riceverà due volte di fila un pacchetto con lo stesso bit sequenza, interpreterà l’ultimo come duplicato del pacchetto precedentemente ottenuto, ipotizzando che il trasmettitore abbia interpretato il precedente ACK come NAK e lo abbia ritrasmesso.
Questo però complica la nostra macchina a stati finiti per il trasmettitore, in quanto è necessario ricordarsi adesso il valore dell’ultimo bit di sequenza, andando di fatto a raddoppiare gli stati.
3.3.3. rdt2.2
È un ulteriore implementazione del rdt2.1, che utilizza esclusivamente gli ACK.
Invece di utilizzare un NAK, il ricevitore invia ACK multipli per segnalare di ritrasmettere l’ultimo pacchetto inviato, includendo esplicitamente il bit di sequenza all’interno del messaggio di ACK.
È ancora una volta sufficiente un solo bit per indicare a quale pacchetto facciamo riferimento, infatti ipotizzando che il trasmettitore abbia inviato un pacchetto 0:
- Se riceve
<ACK, 0>allora il pacchetto è stato ricevuto correttamente - Se riceve
<ACK, 1>è come se il ricevitore dicesse “Ho ricevuto correttamente il pacchetto di prima, non questo”, quindi il trasmettitore lo reinvia
Molti protocolli, incluso quello TCP, utilizzano questo approccio per evitare l’utilizzo dei NAK.
3.3.4. rtd3.0
Introduciamo una nuova ipotesi, quella che il nostro canale di comunicazione, oltre a poter corrompere i bit, possa perdere pacchetti, sia contenenti dati che contenenti ACK.
Il nostro obiettivo sarà quindi quello di riuscire a dedurre e gestire opportunamente queste perdite. Un primo approccio è quello di far attendere al trasmettitore un tempo ragionevole per l’arrivo dell’ACK.
Se entro questo tempo il messaggio di ACK non arriva, supponeremo che il messaggio non sia arrivato, e procederemo a reinviarlo.
Questo metodo infatti è efficace anche nel caso in cui i pacchetti non si siano davvero persi ma abbiano subito un ritardo. Infatti, il ricevitore è già in grado di gestire pacchetti duplicati.
Le macchine a stati finiti del trasmettitore si complicano ulteriormente:
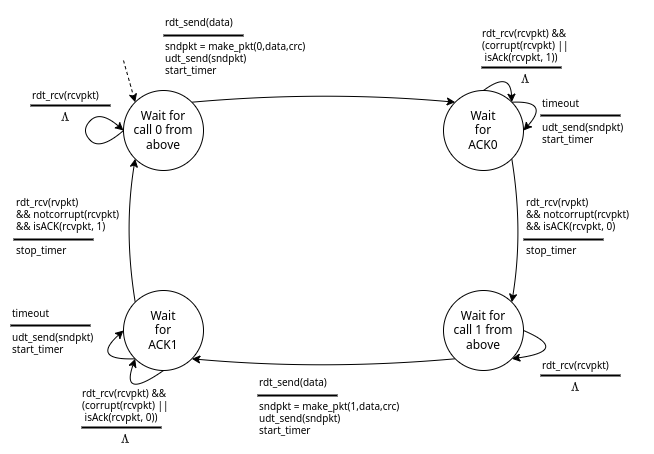
Il fatto che quando arriva un ACK “sbagliato” non si faccia nulla è detto approccio pigro, dato che comunque prima o poi si verificherà l’evento del timer che procederà al reinvio del messaggio.
In questo caso è ancora più fondamentale inserire all’interno dell’ACK il pacchetto di riferimento, vediamo di seguito perché:
Possiamo valutare le performance di questo protocollo rdt3.0, detto di stop-and-wait.
Definiamo la performance di utilizzo $U_{\text{sender}}$ la frazione di tempo nella quale il trasmettitore è impegnato ad inviare pacchetti sul totale.
Ipotizziamo il seguente caso:
- Banda del link:
1Gbps - Ritardo di propagazione:
15ms - Dimensioni pacchetti:
8000 bit/pkg
Il tempo necessario a trasferire un pacchetto attraverso il canale è di: \(D_{\text{trans}} = \frac{L}{R} = \frac{8000\text{ bits}}{10^9\text{ bits/sec}} = 8\;\mu s\)
Prima di inviare il pacchetto successivo, il nostro protocollo richiede però l’arrivo dell’ACK.
Dobbiamo quindi considerare anche il RRT (Round-Trip-Time) nel nostro calcolo, in questo caso di $15ms + 15ms = 30ms$
Possiamo quindi calcolare la performance di utilizzo: \(U_{\text{sender}} = \frac{\frac{L}{R}}{RTT + \frac{L}{R}} = \frac{0.008}{30.008} = 0.00027\)
Possiamo quindi dedurre che la performance di utilizzo del protocllo rdt3.0 fa schifo.
3.3.5. rdt3.0 pipeline
Per migliorare le performance di utilizzo del protocollo rd3.0 si introduce la tecnica del pipelining.
Attraverso questa tecnica il trasmettitore non invia solo un pacchetto, ma permette l’invio di più pacchetti non ancora verificati.
Questa introduzione comporta però delle modifiche:
- Il numero di bit dedicati a indicare il numero di sequenza deve aumentare.
- Dobbiamo introddurre dei sistemi di buffering nel trasmettitore e/o nel ricevitore.

Possiamo notare che inviare $n$ pacchetti in una pipeline moltiplica la performance per un fattore di $n$.
Il numero massimo di pacchetti inviabili in una finestra $\frac{L}{R} + RTT$ è proprio $1 + \frac{RTT \cdot R}{L}$.
Sia il numero di sequenza che il sistema di buffering saranno dipendenti dalle modalità con le quali il protocollo gestisce gli errori (pacchetti persi, corrotti e in ritardo).
In particolare, se forniamo $k$ bit al numero di sequenza, potremo inviare in una pipeline un massimo di $2^k$ pacchetti
Vediamo quindi alcuni protocolli di pipelining:
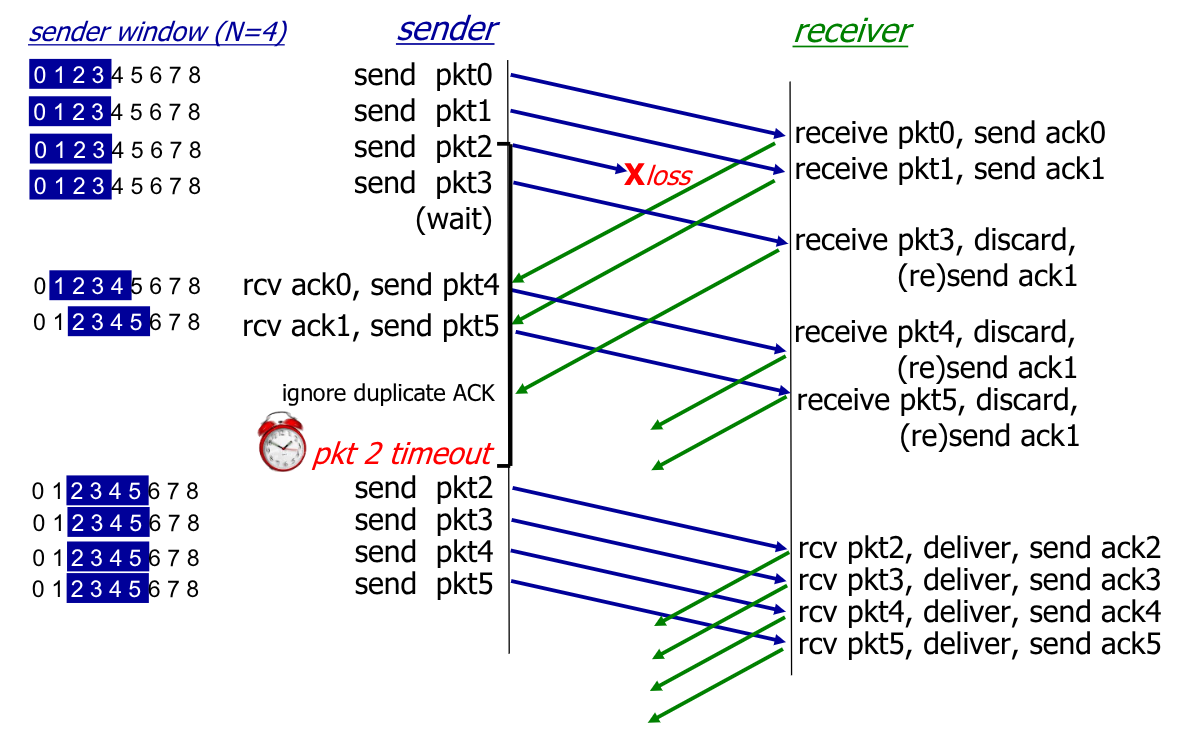
3.3.5.1. Go-Back-N
Con questo protocollo il trasmettitore può trasmettere più pacchetti senza attendere per alcun ACK. Tuttavia esiste un numero massimo di pacchetti non verificati inviabili, chiamato Window Size $N$.
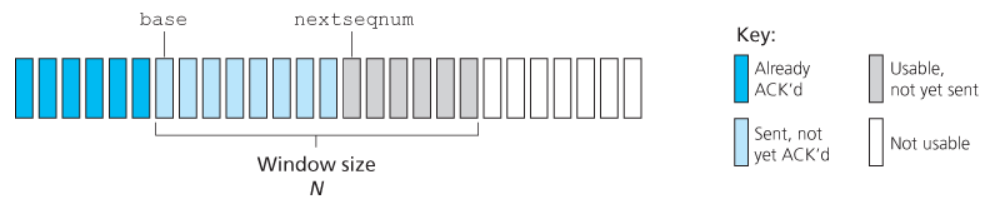
Definiamo come base il numero di sequenza del più vecchio pacchetto non verificato, e come nextseqnum il più piccolo numero di sequenza non utilizzato.
Possiamo quindi identificare quattro intervalli:
[0, base-1]: pacchetti inviati che sono già stati verificati tramiteACK[base, nextseqnum - 1]: pacchetti inviati che non sono ancora stati verificati tramiteACK[nextseqnum, base + N - 1]: pacchetti che possono essere inviati immediatamente[base + N, end]: paccchetti che non possono essere inviati se prima non riceviamo l’ACKdel pacchetto con numero di sequenzabase.
In questo protocollo gli ACK in realtà non sono relativi ai singoli pacchetti, ma sono inviati per gruppi di essi.
Infatti il messaggio di ACK(n) conterrà un numero di sequenza $n$, che indica l’ultimo pacchetto validato.
Quando il trasmettitore riceverà ACK(n), setterà base = n+1.
È inoltre introdotto un timer. Se alla scadenza di questo timer non è arrivato alcun ACK, il trasmettitore procede a ritrasmettere tutti i pacchetti nell’intervallo [base, nexseqnum - 1].
All’arrivo dell’ACK(n), il trasmettitore resetterà il timer.
Il ricevitore si occupa quindi di inviare gli ACK per i gruppi di pacchetti corretti arrivati.
Questo può comportare l’invio di ACK(n) duplicati, infatti ACK(1) è un sottoinsieme di ACK(4), che però viene generato dopo.
Un vantaggio è la necessità di ricordare solamente expectedseqnum, ovvero il numero di sequenza del prossimo pacchetto non ancora ricevuto in maniera corretta.
In caso di ricezione fuori ordine è possibile effettuare una scelta di implementazione, decidendo di mantenere o scartare i vari pacchetti.
Possiamo vedere le macchine a stati finiti e un esempio:
Trasmettitore
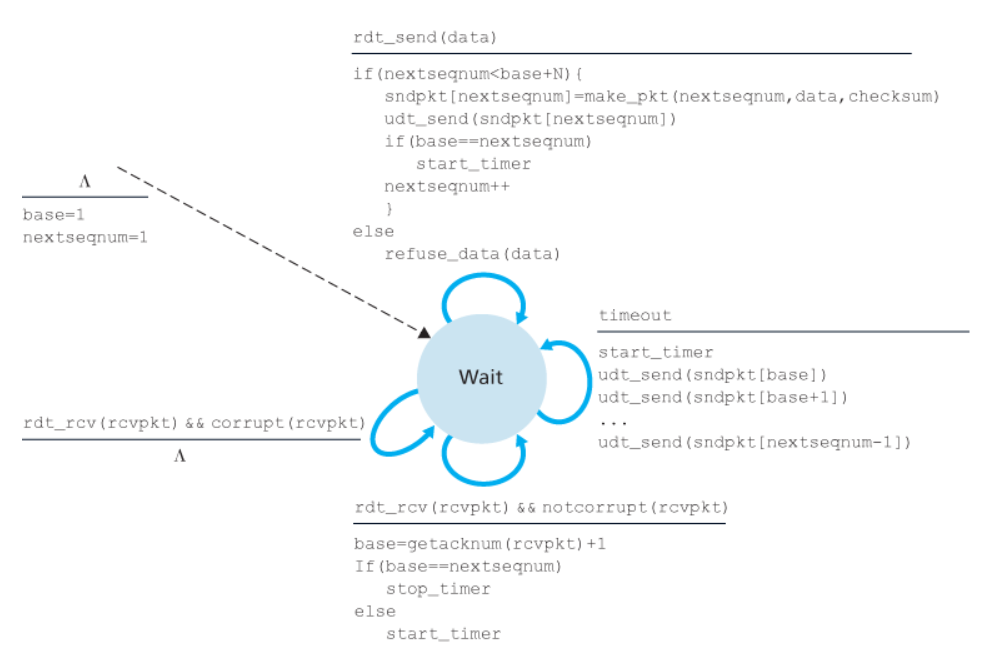
Ricevitore
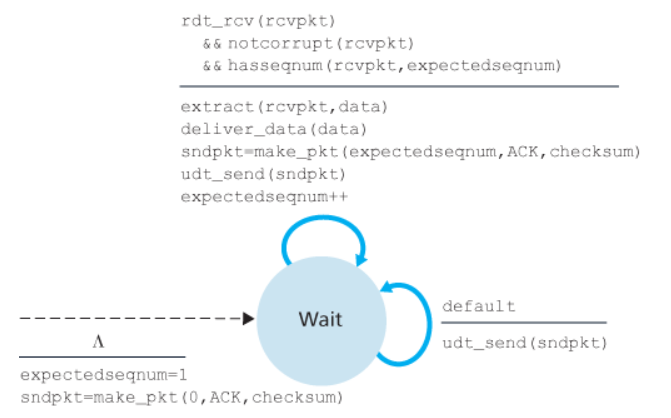
Esempio
3.3.5.2. Selective Repeat
È l’altro protocollo per la gestione delle pipeline.
In questo protocollo il ricevitore invia gli ACK individualmente per ogni pacchetto ricevuto, implementando sistemi di buffering per eventuali pacchetti fuori ordine e evitando ritrasmissioni non necessarie.
Anche in questo caso abbiamo una Window Size $N$, con la gestione interna molto simila al protocollo GBN. A differenza di questo però, il ricevitore avrà già ricevuto ACK anche per pacchetti all’interno della finestra, come possiamo vedere nell’immagine di seguito:

I pacchetti verificati nella finestra sono bufferizzati dal ricevitore qual’ora fosse necessario una comunicazione in ordine.
In questo caso, qual’ora dovesse scadere il timer, il trasmettitore reinvierà tutti i pacchetti non verificati all’interno di [base, nextseqnum - 1].
Possiamo vedere un esempio di SR in azione:
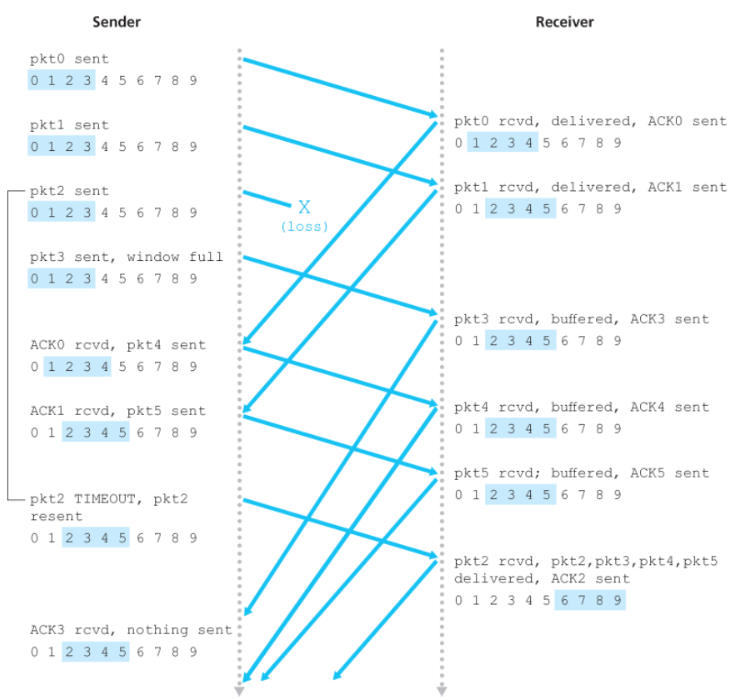
Con un po’ di sforzo mentale è possibile notare però un problema. Se ipotizziamo che ACK(3) e ACK(4) siano andati persi, il trasmettitore riceverà ACK(2) e rimarrà in attesa. Allo scadere del timer, il trasmettitore, non avendo ottenuto i due ACK successivi, invierà nuovamente i pacchetti 3 e 4.
Il ricevitore, che invece ha ricevuto pkt3 e pkt4 e segnato come inviati i rispettivi ACK, si vedrà arrivare due nuovi pacchetti con numero di sequenza 3 e 4, non consapevole del fatto che questi sono ritrasmissioni di pacchetti già ricevuti e salvati.
Questo potrebbe non sembrerebbe un grosso problema, ma immaginiamo di avere una finestra di 3 pkg identificati in modulo 3 come 0, 1, 2.
Immaginiamo quindi che vengano inviati i primi tre pacchetti senza problemi.
Il ricevitore avrà segnato come ricevuti questi pacchetti, inviando i loro ACK. Sarà pronto a ricevere il numero 3, 4, e 5, anch’essi identificati come 0, 1 e 2.
Ipotizziamo adesso che tutti gli ACK si perdano.
Il trasmettitore, non avendo ricevuto alcun ACK, attenderà quindi il timeout e procederà a reinviare gli stessi pacchetti.
Il ricevitore adesso accetterà i nuovi pacchetti, poiché i numeri di sequenza coincidono, portando ad una duplicazione dei primi sei pacchetti e al salvataggio di un messaggio complessivo errato.
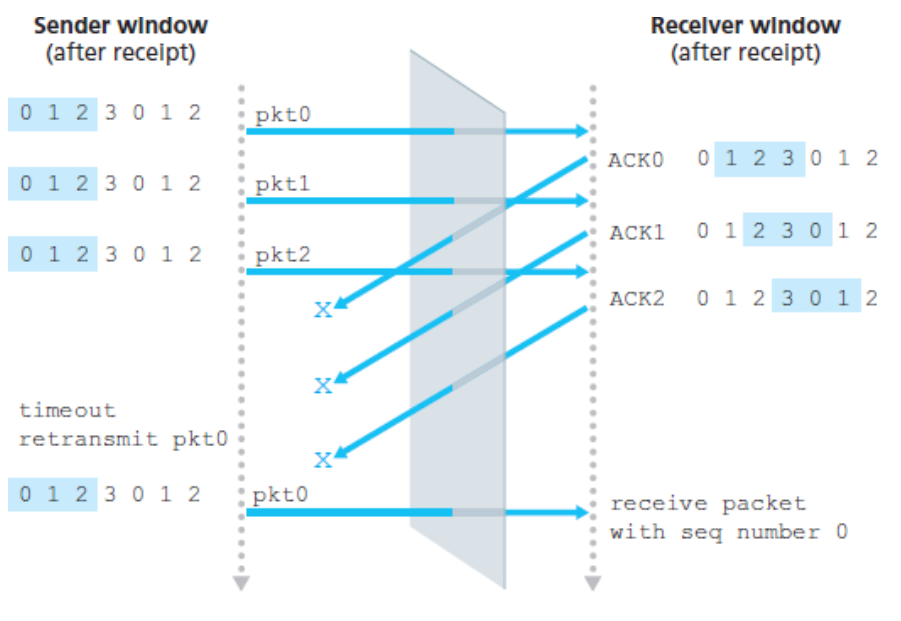
Questo dilemma sulla natura dei pacchetti è dovuto proprio al fatto che vengono utilizzate finestre troppo grandi. Infatti, se utilizziamo finestre grandi tanto quanto i numeri di frequenza abbiamo già visto che è impossibile distinguere le ritrasmissioni con l’invio di nuovi pacchetti. Per risolvere questo problema si diminuisce la dimensione della finestra $N$, senza variare l’intervallo dei numeri di sequenza. È possibile dimostrare che, se i numeri di sequenza $s \in [0, S]$, con una finestra $N = \frac{S}{2}$ e introducendo un lifetime ai pacchetti risolviamo questo problema.
All’interno di reti ad alta velocità, il lifetime massimo dato ai pacchetti in comunicazioni TCP è di circa tre minuti (RFC 1323).
4. Point to Point Protocol (PPP)
Le connessioni point to point consistono in un singolo trasmettitore e in un singolo ricevitore.
Il protocollo che disciplina questo tipo di connessioni permette:
- Packet Framing: l’incapsulamento del datagramma nel layer di rete in quello che abbiamo chiamato il Data Link Frame. Questo trasporterà informazioni di livello di rete per ogni protocollo.
- Bit Transparency: il pacchetto deve trasportare tutti i pattern nel campo dati
- Connection Liveness: permette di rilevare e segnalare fallimenti della connessione al layer di rete
- Network Layer Address Negotiation: permette agli endpoint di imparare e configurare gli uni gli indirizzi di rete degli altri
Questo protocollo invece non permette:
- Error Correction
- Error Recovery
- Flow Control
- Out for order deliveries
- Point-to-multipoint communication (supportato invece di altri protocolli come il
HDLC)
L’error recovery, il flow control e il data re-ordering sono delegati dal protocollo ai livelli superiori.
Il protocollo stabilisce che i messaggi siano così incapsulati:
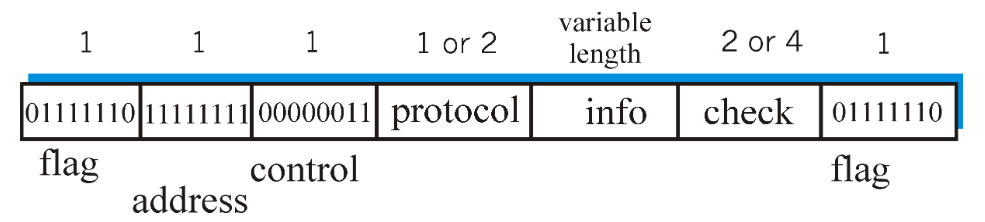
- Flag: sono delle sequenze di bit che fanno da delimitatore del frame
- Indirizzo: è un campo inutile, ma è sempre costante. Venne inserito perché in principio si pensava di supportare anche la point-to-multipoint.
- Controllo: non fa nulla. È stato inserito con l’ottica che in futuro possa contenere informazioni di controllo
- Protocollo: specifica il protocollo del livello superiore (ad esempio
IP) attraverso il quale il pacchetto è inviato - Info: rappresenta i dati provenienti dai livelli superiori. La lunghezza è un parametro negoziabile, che va da $0$ a $1024$ Byte.
- Check: rappresenta i bit che servono per il
CRCper la error detection
All’interno delle info potrebbe però essere presente proprio la sequenza del flag.
Per evitare che il ricevitore interpreti in maniera errata questi dati, trattandoli come flag di terminazione, si introduce una sequenza di escape. 01111101
Il processo attraverso il quale il trasmettitore crea questa sequenza si chiama byte stuffing, mentre l’inverso compito dal ricevitore si chiama byte unstaffing.
Le trasmissioni delle seguenti sequenze vengono quindi tradotte:
$$
\begin{CD}
\overbrace{01111110}^{\textbf{Dati uguali al flag}} @>{\text{Trasmettitore}}» 01111101|01111110 @>{\text{Ricevitore}}» 01111110
\underbrace{01111101}_{\textbf{Dati uguali alla sequenza di escape}} @>{\text{Trasmettitore}}» 01111101|01111101 @>{\text{Ricevitore}}» 01111101
\end{CD} \
$$
5. Multiple Access Protocol
Sono protocolli che permettono la trasmissione dei messaggi di tipo broadcast, ovvero point-to-multipoint.
Alcuni sistemi basati su broadcast sono: le reti cellulari, le reti wifi, il vecchio Ethernet, reti satellitari o, banalmente, le persone che si riuniscono e parlano.
Le connessioni broadcast hanno un problema intrinseco alla loro natura. Dato che tutti i nodi condividono lo stesso mezzo, se due nodi iniziassero a comunicare insieme senza attendersi l’un l’altro si verificherebbero delle collisioni che produrrebbero interferenze nella trasmissione.
Il Multiple Access Protocol:
Implementa un algoritmo distribuito che determina come i nodi condividono il canale, determinando quando un nodo può comunicare.
È importante sottolineare che le comuncazioni relative all’utilizzo del canale devono essere fatte sempre attraverso lo stesso canale.
Esistono diversi approcci attraverso il quale è possibile implementare le comunicazioni broadcast.
Un protocollo ideale, dato un canale multi-accesso (MAC) di banda $R$ bps, vorrebbe che:
- Se un nodo vuole trasmettere, lo può fare al rateo $R$
- Se $M$ nodi vogliono trasmettere, lo possono fare con una velocità media $\frac{R}{M}$
- Non esiste un nodo speciale che coordina le comunicazioni, né degli strumenti di sincronizzazione o di prenotazione
- Deve essere semplice
In generale esistono tre classi di protocollo:
- Channel Partitioning: permettono di dividere un canale in pezzi più piccoli (slot temporali, modulazione di frequenze, suddivisione di codice). Ad ogni nodo viene assegnato in maniera esclusiva uno di questi “pezzi”
- Random Access: non divide il canale, permettendo le collisioni. Tuttavia permette anche di “guarire” da esse
- Taking Turns: ogni nodo si prenota per un quanto di tempo, tendenzialmente proporzionale alla dimensione del messaggio che deve inviare.
5.1. Time Division Multiple Access - TDMA
È un protocollo che permette l’accesso al canale in “round”. Tutti i nodi ottengono uno slot di dimensione fissata ad ogni turno. Per dimensione si intende il tempo necessario per inviare un pacchetto di dimensione nota. Se un nodo non necessita del suo slot, questo va semplicemente idle.
Un esempio grafico di questo approccio è il seguente:

Esempio con una connessione a 6 stazioni, con tre nodi che devono trasmettere, mentre gli altri sono idle.
Questo metodo non soddisfa i desideri del MAC ideale.
- NO: Se un nodo deve trasmettere, la velocità con la quale lo può fare è vincolata al proprio slot, indipendentemente dal fatto che ci sia qualcun’altro.
- SÌ: Se l’allocazione del tempo è uguale per tutti, in media in fondo tutti trasferiscono alla stessa velocità
- NO: i clock devono essere sincronizzati affinché non si abbiano sforature. Inoltre potrebbe servire un nodo esterno che regola l’ordine
- SÌ: ognuno ha il suo slot senza dover fare troppi controlli.
5.2. Random Access Protocols
Questa politica sancisce che quando un nodo ha dei pacchetti da trasferire lo fa utilizzando tutto il canale. Il protocollo inoltre non regola alcuna coordinazione a priori tra i nodi.
Questo ultimo passaggio comporta che il protocollo è susciettibile a collisioni. Il protocollo a random access MAC specifica come rilevare gli errori e sistemarli.
Alcuni esempi di protocolli MAC sono:
ALOHAeslotted ALOHACSMA,CSMA/CD,CSMA/CA
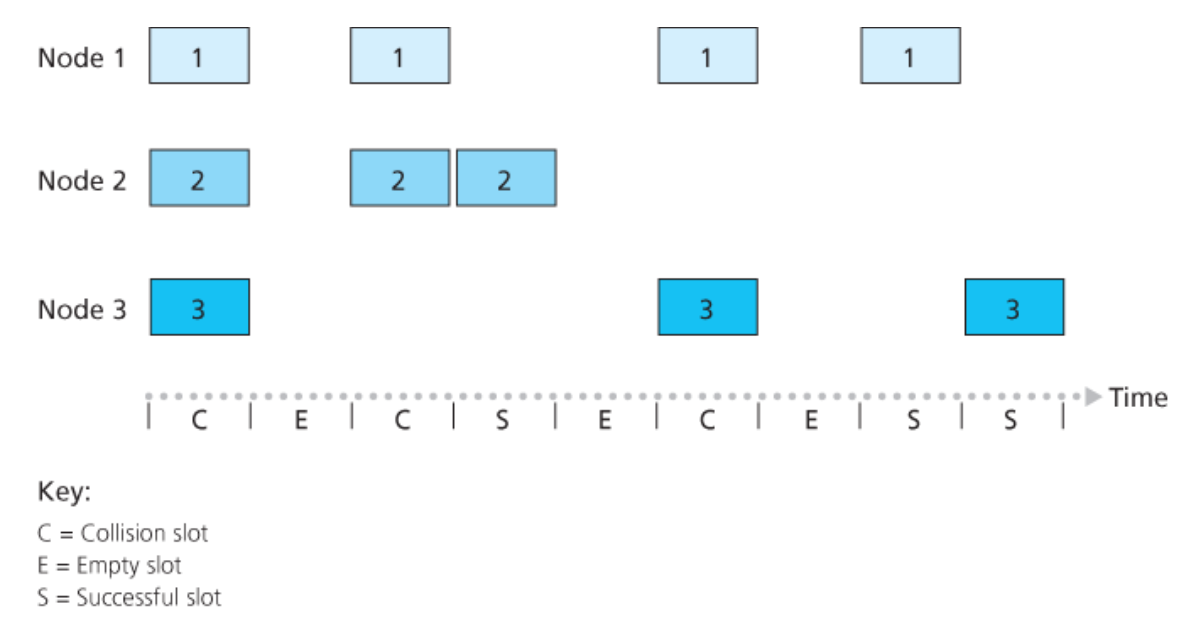
5.2.1. Slotted ALOHA
Questo protocollo opera sotto le seguenti assunzioni:
- Tutti i frame sono uguali $L$ bit
- La rete opera a $R$ bps
- Il tempo è diviso in unità di $\frac{L}{R}$ s
- I nodi iniziano a trasmettere i frame solo all’inizio degli slot
- I nodi sono sincronizzati così che ogniuno sa quando lo slot inizia
- Se due o più frame collidono in uno slot, tutti i nodi rilevano la collisione prima che lo slot termini.
Detta $p$ una probabilità $0 \le p \le 1$, le operazioni stabilite dal protocollo sono semplici:
- Se un nodo ha un nuovo frame da trasmettere aspetta l’inizio del prossimo slot e lo trasmette tutto nello slot
- Se non ci sono collisioni, il frame è stato correttamente trasferito e l’operazione di trasferimento è terminata
- Se ci sono state collisioni, il nodo le rileva prima della fine dello slot. Successivamente, per ogni slot successivo il nodo avrà una probabilità $p$ di ritrasmettere il frame.
La ritrasmissione ha probabilità $p$ che avvenga senza una nuova collisione. Quello che si intende con questa affermazione, è che ad ogni ritrasmissione è come se il nodo lanciasse una “biased coin”:
- Testa rappresenta la ritrasmissione, che accade con probabilità $p$
- Croce rappresenta saltare lo slot e ritentare al prossimo, che accade con probabilità $(1 - p)$
Tutti i nodi fanno la scelta di ritrasmettere o meno il frame indipendente. Una possibile evoluzione è quella sulla destra.
Questo protocollo ha sia pro che contro.
| Pro | Contro |
|---|---|
| Un singolo nodo attivo più trasmettere a $R$ bps | Ci possono essere collisioni che sprecano gli slot |
| È decentralizzato, poiché solo gli slot nei nodi devono essere sincronizzati | Ci sono degli slot idle non utilizzati |
| Semplice | I nodi potrebbero rendersi conto della collisione dopo che il pacchetto è stato completamente trasmesso |
| Necessità di sincronizzare il clock |
Andiamo a calcolarne l’efficienza, ovvero il raporto tra slot correttamente utilizzati sul totale.
Supponendo di avere $N$ nodi. Ogni nodo ha tanti frame da inviare, ogniuno con probabilità $p$ di essere trasmesso in un determinato slot:
- Probabilità che un nodo invii correttamente un messaggio in uno slot: $p(1-p)^{N-1}$
- Probabilità che un qualsiasi nodo invii correttamente un messaggio in uno slot: $N\cdot p(1-p)^{N-1}$
- Massima efficienza: troviamo $p^\ast$ che massimizza $N\cdot p(1-p)^{N-1} \to p^\ast = \frac{1}{N}$
- Calcoliamo il limite di $\lim_{N\to\infty}{N\cdot p^\ast(1-p^\ast)^{N-1}}$
Non specificando i calcoli, l’efficienza massima è di $\frac{1}{e} = 0.37 \Rightarrow 37\%$
Quindi, nel caso migliore, utilizzeremo il canale solamente per poco più di un terzo del tempo.
5.2.2. Pure ALOHA
È una versione più semplice dello slotted ALOHA, dove non è presente sincronizzazione tra i nodi. Quando un nodo ha un frame da comunicare lo trasmette immediatamente.
Questo non fa altro che aumentare la probabilità di collisioni, infatti se inviamo un frame al tempo $t_0$, questo potrebbe collidere con gli altri frame inviati nell’intervallo $[t_0-1, t_0 +1]$
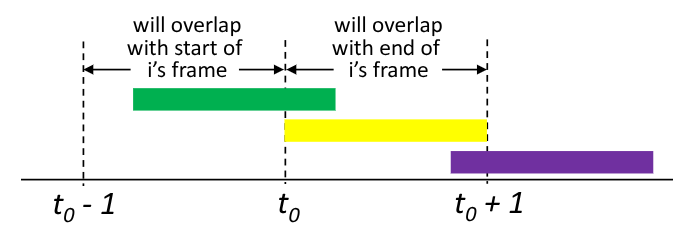
Calcoliamo l’efficienza: \(\quad \begin{align*} P(\text{successo di un dato nodo}) &= P(\text{trasmissione efficace}) \cdot P(\text{nessun altro nodo trasmette in } [t_0-1, t_0]) \cdot P(\text{nessun altro nodo trasmette in } [t_0, t_0+1]) \\ &= p \cdot (1-p)^{N-1} \cdot (1-p)^{N-1} \\ &= p \cdot (1-p)^{2(N-1)} \\ &\begin{CD} @VV{p^\ast \text{ massimizza}}V \end{CD} \\ P(\text{successo di un dato nodo}) &= \lim_{N\to\infty}{p^\ast \cdot (1-p^\ast)^{2(N-1)}} = \frac{1}{2e} = \boxed{0.18} \end{align*}\)
Otteniamo quindi un efficienza persino peggiore dello slotted ALOHA.
5.2.3. Carrier Sense Multiple Access - CSMA
Nei protocolli ALOHA abbiamo visto la decisione di un nodo di trasmettere è indipendente dall’attività degli altri nodi all’interno del canale. Il fatto che un altro nodo stia gia trasmettendo non ferma un altro nell’iniziare a trasmettere. Allo stesso modo, un nodo che sta già trasmettendo non si mette in pausa se un altro inizia a comunicare.
Per migliorare questo sistema si utilizzano due regole utilizzate anche nella comunicazione umana:
- Ascolta prima di parlare: se qualcun altro sta parlando si attende che questo finisca prima di parlare. Nel mondo delle reti si chiama carrier sensing, un nodo ascolta il canale prima di trasmettere, e attende che non vi siano comunicazioni per un intervallo di tempo stabilito prima di iniziare a trasmettere.
- Se qualcuno inizia a parlare nello stesso momento, smetti: Nel mondo delle reti si chiama collision detection, un nodo sta in ascolto anche mentre sta trasmettendo. Se rileva una collisione attende un tempo casuale prima di ripetere il ciclo di trasmissione
Queste due regole sono alla base dei protocolli CSMA e CSMA/CD (con collision detection), regolamentati in [Kleinrock 1975b; Metcalfe 1976; Lam 1980; Rom 1990].
Nonostante il carrier sensing le collisioni possono comunque avvenire. Infatti il delay di propagazione comporta che due nodi possano non sentirsi quando iniziano le trasmissioni.
Sulla destra possiamo vederre un esempio di ciò.
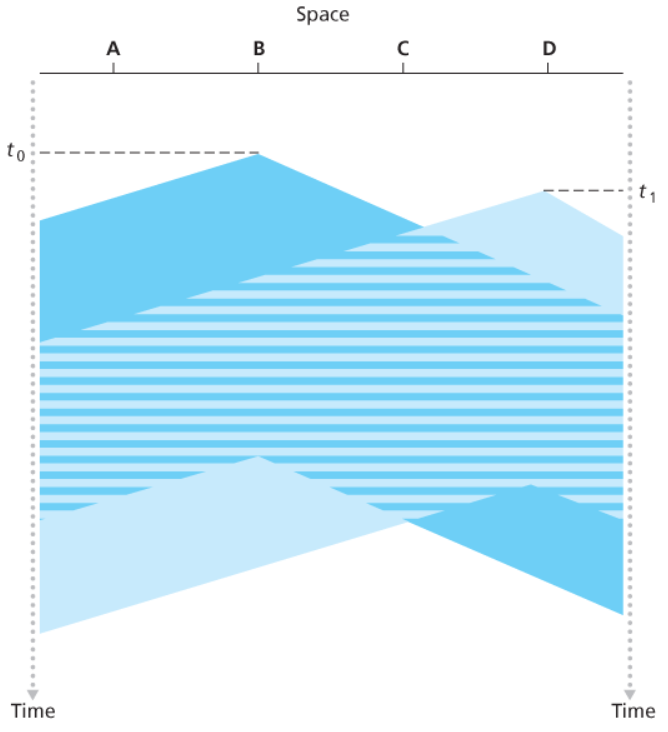
Questa versione però non performa collision detection, infatti sia $B$ che $D$ continuano a trasmettere i loro frame anche se sanno che c’è stata una collisione.
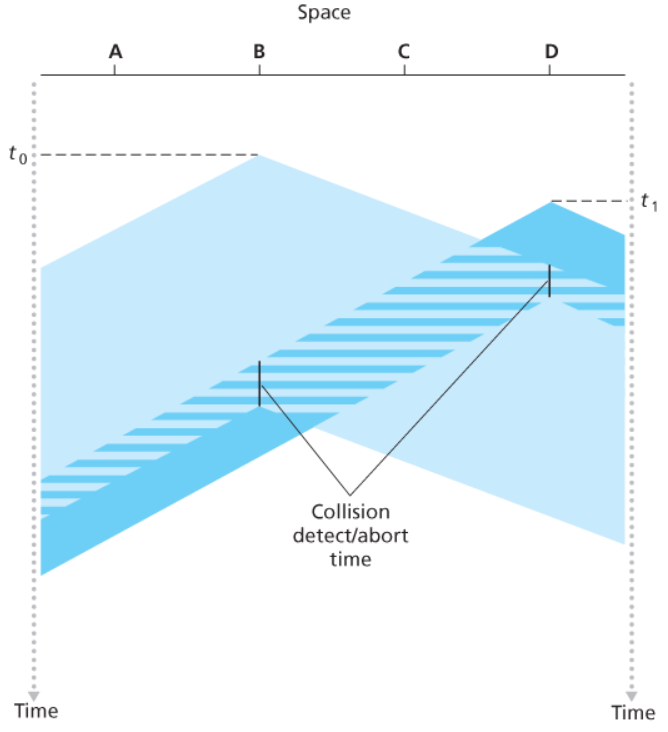
Il protocollo CSMA/CD sancisce che le comunicazioni siano terminate nel momento in cui si rileva una collisione.
Il grafico sopra diventa quindi quello sulla destra.
In questo modo riusciamo a diminuire il tempo perso per via delle collisioni.
Il segnale inviato durante le collisioni si chiama segnale di JAM. Questo server per rafforzare la collisione e renderne più semplice per gli altri nodi l’individuazione
Prima di analizzare il protocollo CSMA/CD riassiumiamo le operazioni che abbiamo appena descritto dal punto di vista del NIC:
- L’adattatore ottiene un datagramma dal network layer. Prepara quindi il frame del link layer e prepara il frame adapter buffer
- Il NIC si mette in ascolto sul canale:
- Se il canale è idle (non c’è energia sul canale) inizia a trasmettere il frame
- Se il canale invece è occupato attende finché non si libera e poi inizia a trasmettere il frame
- Mentre sta trasmettendo, il NIC monitora la potenza energetica in entrata . Se è significativamente diversa da quella da lui trasmessa, significa che ci sono segnali provenienti da altri adattatori che comunicano sul canale broadcast
- Se il NIC ha trasmesso l’intero frame senza interruzioni, termina. Altrimenti esegue un abort della trasmissione
- Dopo l’abort, il NIC attende un tempo casuale e riparte dal punto 2, entrando nel binary (exponential) backoff
- Dopo la $m$-esima collisione, il
NICgenera un valore $K \in {0, 1, 2, 3, …, 2^m-1}$ e attende $K \cdot 51,2$ $\mu s$
- Dopo la $m$-esima collisione, il
Questo metodo soddisfa i desideri del MAC ideale:
- SÌ: Se un nodo deve trasmettere e il canale è libero, comunica al massimo della banda
- SÌ: Nessun nodo ha una corsia preferenziale
- SÌ: Non ci sono elementi di sincronizzazione, ed è fully decentralized
- SÌ: possiamo dire che è semplice
Anche se questo protocollo sembra quindi ottimo, ha un problema nel throughput nel caso di un numero elevato di nodi, che aumenta la probabilità di collisioni, degradandolo.
5.3. Taking Turns MAC Protocols
Sono un unione tra le altre due classi di protocolli che abbiamo visto.
Ne esistono anche qui di diversi tipi
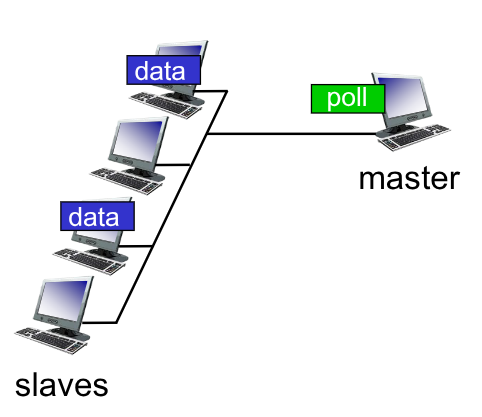
5.3.1. Polling
Nel sistema con polling, si ha una struttura centralizzata, dove è presente un dispositivo master/coordinatore che invita i nodi slave/normali a parlare.
Se non hanno messaggi da trasmettere questi inviano un messaggio null e il master procede con il prossimo
È tipicamente utilizzato con dispositivi “stupidi”, come ad esempio il protocollo Bluetooth.
Ha dei punti critici:
- Si genera del polling overhead
- È susciettibile ad un alta latenza
- Presenta un single-point-of-failure
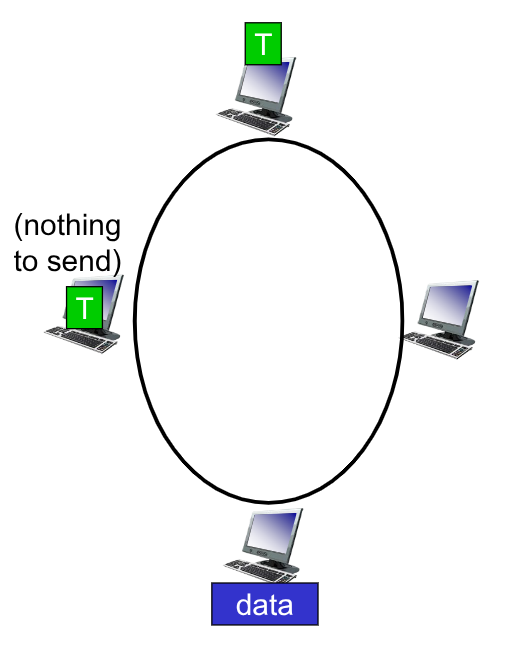
5.3.2. Token Passing
Nei sistemi con token, si ha un token (frame di bit) che viene passato da un nodo all’altro in maniera sequenziale.
Solo chi ha il token può trasmettere
Anche questo metodo ha dei punti critici:
- Si genera del token overhead
- È susciettibile ad un alta latenza
- Presenta un single-point-of-failure che è il token
6. Local Area Network - LAN
Le reti LAN sono leti a medio broadcast, che hanno un area di copertura limitata.
Permettono un alto bit rate ma ha il difetto di, per sua natura, effettuare comunicazioni di tipo broadcast.
È quindi necessario avere un Medium Access Control Protocol introducendo un sistema di indirizzamento MAC.
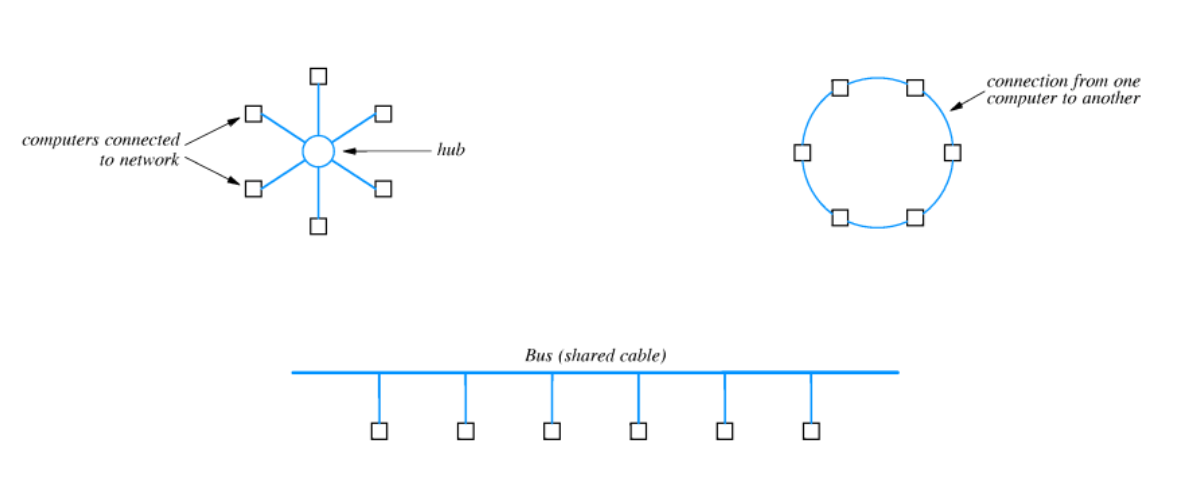
Alcune topologie di rete LAN. In ordine da in alto a sinistra a in basso a destra abbiamo la topologia a stella, ad anello e tramite bus
6.1. Indirizzi MAC
Per poter comunicare privatamente su reti naturalmente broadcast, dobbiamo trovare un modo per riuscire a individuare univocamente ogni nodo all’interno della rete locale nelal quale si trova.
Per fare ciò si introducono gli indirizzi MAC. Questi indirizzi sono assegnati in maniera univoca dal produttore della scheda di rete. Vengono utilizzati localmente per permettere la trasmissione di frame tra più interfacce sulla stessa rete locale.
Gli indirizzi MAC sono codificati su 48bit in esadecimale, d’accordo con lo standard IEEE. È salvato direttamente nella ROM del NIC, ma qualche volta è modificabile tramite software. Un esempio di indirizzo MAX è: 1A-2F-BB-76-09-AD.
I primi 24bit identificano la scheda vera e prorpia, gli ultimi 24bit invece identificano il costruttore.
Gli indirizzi MAC (o indirizzo fisico) sono diversi dagli indirizzi IP, che identificano il nodo nel livello di internet.
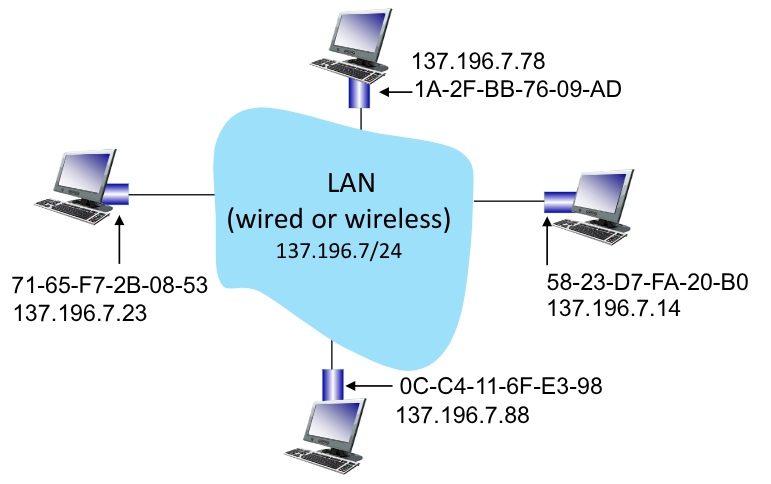
Esiste inolte un indirizzo di broadcast nel quale tutte le interfacce si identificano. L’indirizzo è il seguente FF-FF-FF-FF-FF-FF.
6.2. Ethernet
È la tecnologia più popolare che implementa le reti locali cablate.
La topologia tipica di questa tecnologia si è evoluta nel tempo. Negli anni ‘90 il collegamento più popolare era quello attraverso un cavo coassiale che si comportava da bus, generando un unico grande dominio per le collisioni.
Oggi la topologia più comune è quella a stella, dove l’hub viene identificato da uno switch. Questo switch opera a livello 2 e, oltre a rigenerare i segnali come un comune hub, gestisce i frame ridirezionandoli opportunamente solo ai nodi coinvolti. In questo modo è come se ogni connessione viaggiasse su un protocollo ethernet separato.
La tecnologia ethernet incapsula il datagramma IP in quello che chiamiamo Ethernet frame

Dove:
- Preambolo: è utilizzato per sincronizzare i clock del sender e del receiver. È composto da
7 Bytesdi10101010seguiti da1 bytedi10101011. - Indirizzo: sono
6 Byteutilizzati per conservare gli indirizziMAC:- Indirizzo Sorgnete: indica il
MACdel nodo che ha trasmesso il frame - Indirizzo Destinatario: può indicare il
MACdi un destinatario o un indirizzo speciale che indica la comunicazione broadcast. Se un pacchetto possiede un dest. addr. diverso dal proprio o dal broadcast, il nodo lo scarta e smette di stare in ascolto sul resto dei bit che stanno venendo trasmessi.
- Indirizzo Sorgnete: indica il
- Type: indica il protocollo di livello superiore utilizzato (
IP,Novell IPX,AppleTalk, …) su2Byte - Bit di controllo
CRC: permettono la error-detection su4Byte - Data(payload): ha una dimensione minima di
48Bytee una dimensione massima di1500Byte. Per sapere il perché della dimensione minima guardare il capitolo successivo
Le connessioni ethernet sono:
- Senza connessioni: non è infatti introdotto nessun handshake tra l’invio e il ricevimento di informazioni tra
NIC - Inaffidabili: chi riceve un pacchetto non invia alcun messaggio di
ACK. I dati che possono andare persi per via di errori di comunicazione vengono recuperati solo se un livello superiore li vuole utilizzare, altrimenti rimangono perduti.
Il protocollo MAC utilizzato dalle connessioni ethernet è un unslotted CSMA/CD con backoff binario.
I passaggi in una comunicazione sono questi:
- Il NIC riceve dati dal network layer e crea il frame
- Se il
NICsi mette in ascolto del canale e iniza la trasmissione solo dopo che sono passati96bitdi tempo idle - Se il
NICha trasmesso tutto il pacchetto senza errori, termina - Se il
NICrileva un altra trasmissione mentre sta inviando il pacchetto, fa abort dell’invio e procede a inviare un segnale di jam di48bit. - Dopo l’abort il
NICentra nel backoff esponenziale per un massimo di 17 tentativi, dopo i quali droppa il frame
Il segnale di jam fa in modo che tutti gli altri trasmettitori vengano a conoscenza dell’avvenuta collisione.
Assumendo connessioni Etehrnet a 10Mbps, la trasmissione di 48bit impiega un tempo di circa $4.8\mu$s
6.2.1. Perdita di Pacchetti e Distanze Massime
I cavi sono mezzi inaffidabili, che possono essere susciettibili a perdita di informazioni. I segnali fisici che passano in un mezzo fisico vanno infatti incontro a degradazione. Ad esempio, misurarono empiricamente che nei cavi coassiali la lunghezza massima era di $500m$ nel caso di cavi spessi, e di $250m$ nel caso di cavi fini.
Per poter migliorare queste distanze si introducono i repeater, che non sono altro che amplificatori e ripetitori di segnale. Tuttavia anche questi sono susciettibili ad errori, ed è stato calcolato che il numero massimo di repeater in cascata è di $4$, successivamente si avranno sicuramente delle perdite.
Immaginiamo di avere, come in figura sulla destra, due interfacce che comunicano su uno stesso mezzo di rame (con velocità di propagazione $v \approx 200.000 m/s$) che possiede 4 repeater, che producono un ritardo di trasmissione di $\frac{\Delta_R}{4}$. Ipotizzando una connessione $R = 10$ Mbps.
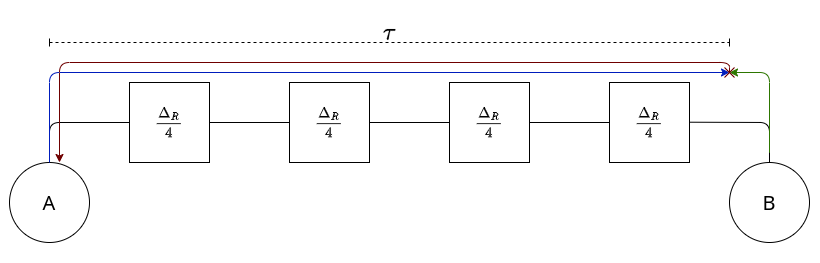
Ipotizzando che nell’istante $t_0 = 0$ l’interfaccia A inizi a trasmettere, e che nell’istante $t_1 = \tau$ lo faccia anche B si avrà una collisione che A intercetterà solo dopo un tempo di:
\(t_{coll} = 2(\tau + \Delta_R) = 2\Bigl(\frac{l_{max}}{v} + \Delta_R\Bigr)\)
Affinché A rilevi la collisione, è necessario che questa arrivi al nodo prima che finisca di trasmettere il suo pacchetto.
Immaginiamo che A stia inviando il più piccolo pacchetto possibile di lunghezza $L_{min}$. Per farlo impiegherà un tempo di $\frac{L_{min}}{R}$.
È quindi necessario che: \(2\Bigl(\frac{l_{max}}{v} + \Delta_R\Bigr) \le \frac{L_{min}}{R} \\ L_{min} \ge 2R\Bigl(\frac{l_{max}}{v} + \Delta_R\Bigr)\)
Empiricamente fu scoperto che la $l_{max} \approx 2500m$, dal quale deriviamo che $\boxed{L_{min} = 72 Byte}$.
Rimuovendo tutte le informazioni di corredo (preambolo, type, indirizzi, CRC), otteniamo perché il datagramma deve essere almeno $48 Byte$.
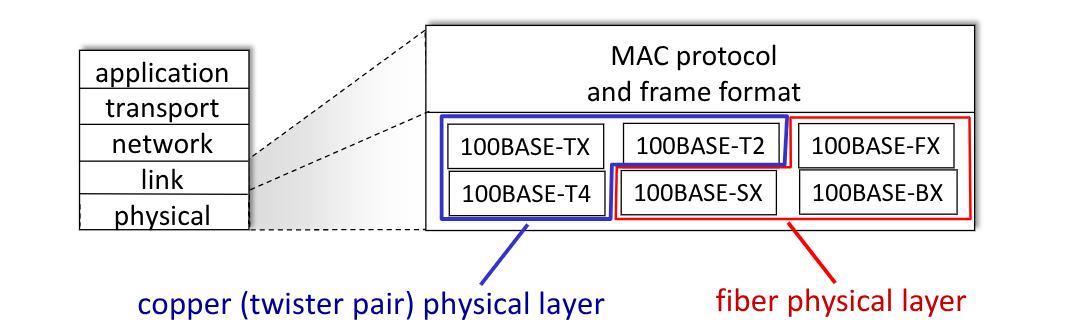
6.2.2. 802.3 Ethernet Standards
Esistono tanti diversi protocolli ethernet. Ognuno lavora su diversi mezzi fisici, a velocità diverse, ma tutti hanno un comune il MAC protocol e il formato dei frame.