1. Indice
- 1. Indice
- 2. Livello di Trasporto
2. Livello di Trasporto
Utilizzando il network layer siamo in grado di trasmettere un datagram tra due host.
Quello che però vogliamo fare noi non è far comunciare tra di loro due host, ma due processi uno su un host e uno su un’altro.
Il transport layer si occupa proprio di permettere la comunicazione process-to-process, basandosi, e migliorando, i servizi di network layer.
Si basa su alcuni principi:
- multiplexing e demultiplexing
- Trasferimento affidabile dei dati
- Controllo di flusso
- Controllo delle congestioni
È implementato da due protocolli:
UDP: trasporto connectionlessTCPtrasporto affidabile orientato alla connessione. Può implementare il controllo di flusso e il controllo delle congestioni
2.1. Servizi di Trasporto
Al livello di trasporto di sviluppano comunicazioni logiche tra processi e non più tra host come nel livello network.
Il servizio di multiplexing/demultiplexing serve proprio per riuscire a gestire le diverse comunicazioni dei vari processi all’interno dello stesso host.
Fornisce il concetto di pipe, ovvero il canale logico di connessione tra:
- Processo Sorgente: riceve un messaggio dall’application layer. Lo divide in diversi segmenti aggiungendovi un header. Inoltra i segmenti al network layer
- Processo Destinatario.: Riceve diversi segmenti dal network layer, e ne controlla i valori nell’header. Estrae i vari spezzoni del messaggio riassemblandolo, e lo demultiplexa inoltrandolo all’application layer attraverso un socket.
Vi sono due protocolli con i quali è possibile implementare il livello di trasporto:
TCP(Transmission Control Protocol): è un protocollo affidabile che si basa sul setup della comunicazione. Implementa il controllo della congestione della rete, il controlllo di flusso.UDP(User Datagram Protocol): è un protocollo inaffidabile che permette la trasmissione di messaggi non ordinati. È l’implementnazione più vicina al concetto di best-effort del protocolloIP
In entrambi i casi non vi è alcuna garanzia sulla gestione del delay né garanzie sulla banda.
2.2. Multiplexing e Demultiplexing
Il multiplexing è un servizio dei trasmettitori che permette di gestire i segmenti diretti verso diversi socket, aggiungendo informaizoni agli header di trasporto.
Il demultiplexing è invece un servizio dei ricevitori, che utilizza le informazioni contenute negli header di trasporto dei segmenti per indirizzarli ai socket corretti.
Nel caso di demultiplexing senza connessione, questo viene effettuato esclusivamente a partire dagli indirizzi IP e dal numero di porta.
All’interno dell’header sono contenute, oltre a diverse informazioni per il momento non rilevanti, il numero di porta sorgente e numero di porta destinatario.
Questo è tipico del protocollo UDP.
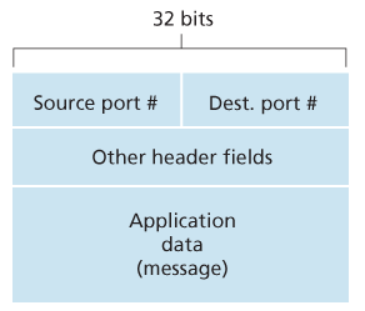
Nel caso di demultimplexing con connessione, un socket TCP è identificato da 4 tuple:
- Indirizzo IP sorgente
- Numero di Porta sorgente
- Indirizzo IP destinatario
- Numero di Porta destinatario
Un server potrebbe infatti supportare diversi socket TCP che operano in simultanea. Ogniuno sarà quindi identificato da queste quattro tuple, e sarà associato ad un processo client diverso.
Il demultiplexer utilizzerà quindi tutte e quattro le informazioni per direzionare opportunamente il segmento al socket corretto.
Questo è tipico del protocollo TCP.
2.3. Protocollo UDP
L’User Datagram Protocol, definito nel [RFC 768], è detto il protocollo di trasporto internet nudo e crudo.
È il protocollo che incarna al meglio la politica “best effort”, in quanto i segmenti UDP potrebbero perdersi o arrivare in ordine causale, in quanto ogni segmento viene trattato indipendentemente dagli altri.
È un protocollo che si dice connectionless, in quanto non presuppone alcun handshake tra il trasmettitore e il ricevitore. Questa scelta permette di mantenere un alto livello di semplicità nelle connessioni, oltre a evitare di aggiungere ritardi dovuti al setup della connessione.
Un altro vantaggio è possibile mantenere limitata la dimensione dell’header.
Questa scelta però comporta l’assenza di controlli sia di flusso che di congestione.
Il protocollo UDP è utilizzato in diversi servizi che non necessitano di affidabilità ma preferiscono puntare sulla velocità e non hanno problemi nel perdere informaizoni:
- Applicazioni multimediali e di streaming
DNSSNMPHTTP/3: implementa il trasferimento affifabile nell’application layer
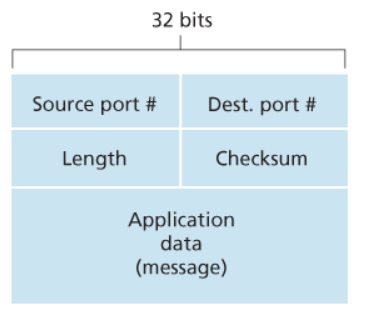
L’header UDP è relativamente semplice e contenuto (64bit):
- Porta sorgente (
16bit) - Porta destinataria (
16bit) - Lunghezza (
16bit): indica la lunghezza complessiva del pacchetto - Checksum (
16bit): controlla eventuali errori - Payload: è il messaggio che arriva dall’applicazione
2.4. Protocollo TCP
È stato definito
È un protocollo point-to-point che implementa il concetto di pipe.
È un servizio che garantisce l’affidabilità della connessione, sia per quanto riguarda l’ordinamento che per quanto riguarda la correttezza.
La pipe è full-duplex, ovvero permette la trasmissione in entrambe le direzione dei segmenti, oltre a fornire i servizi di controllo delle congestioni e del flusso permette anche di impostare l’ampiezza della finestra.
Ogni segmento può avere dimensione variabile, limitata dal MSS (Maximum Segment Size).
Il MSS è calcolato come
\(\text{max-size}_{\text{frame-payload}} - \text{size}_{\text{datagram-header}} - \text{size}_{\text{segment-header}}\)
Il protocollo TCP prevede l’invio cumulativo degli ACK.
È un protocollo orientato alla connessione, che implementa un handshake tra trasmettitore e ricevitore prima che i dati inizino ad essere inviati.
Il protocollo TCP, quando crea i segmenti, lo fa tendno conto della posizione dei Byte de messaggio
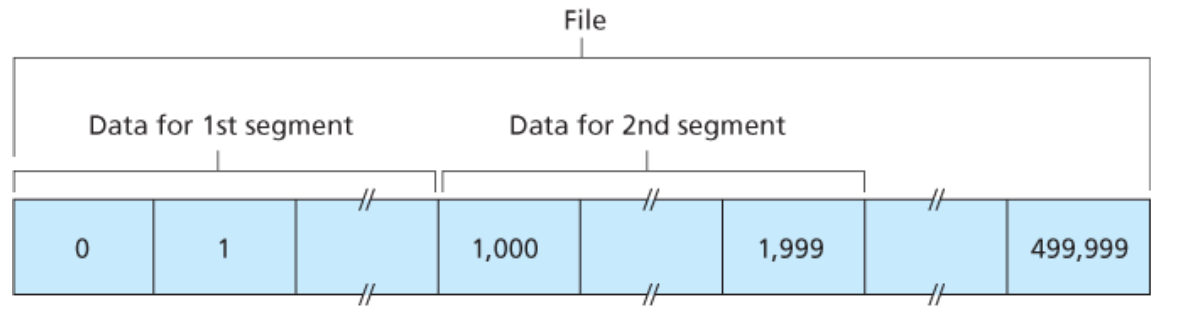
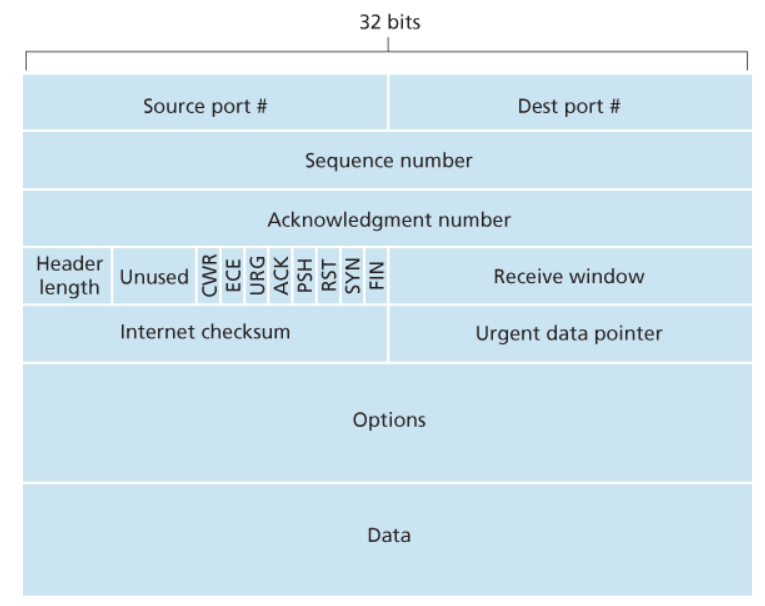
Sulla desra possiamo vedere come è formato un header TCP:
- Numero di Porta Sorgente (
16bit) - Numero di Porta Destinataria (
16bit) - Numero di Sequenza (
32bit): indica il numero di sequenza del primo byte contenuto all’interno del segmento rispetto al messaggio complessivo. Questo permette l’inoltro ordinato dei messaggi. Questo valore viene casualmente generato dai due host per minimizzare la probabilità di ricevere un segmento di una vecchia comunicazione che era ancora in viaggio e considerato valido. - Acknowedgment number (
32bit): durante l’invio del messaggio contiene il numero di sequenza del prossimo segmento che il trasmettitore si aspetta di ricevere dal ricevitore. È significativo solamente se il l’ACK bitè settato - Header Length (
4bit): indica la lunghezza complessiva dell’header. Questa infatti è variabile da un minimo di160bita un massimo di `` dovuto alle varie options - Bit inutilizzati (
4bit) - Flags (
6bit): sono diversi bit che hanno ruoli diversi:- ACK bit: utilizzato per indicare che il valore nel campo acknowledgment number è significativo
- RST, SYN, FIN: sono bit utilizzati per il setup e il teardown della connessione. Il primo serve a resettare la connessione in casi particolari, il secondo per inizializzare una connessione e l’ultlimo per terminarla.
- CWR, ECE: sono utilizzati nelle notifiche esplicite di congestione (non utilizzati)
- PSH: indica se il payload deve essere inviato immediatamente al livello superiore (non utilizzato)
- URG: indica se al’interno del payload sono presenti dati che il livello superiore ha segnato come urgenti. (non utilizzato)
- Receive Window (
16bit): è utilizzato per il controllo di flusso. Indica il numero di _byte_m assimi che il ricevitore può accettare e gestire - Internet checksum (
16bit) - Urgent Data Pointer (
16bit): se il bitURGè settato, indica la posizione dell’ultimo byte della sezione segnata come urgente. (non utilizzato) - Options: campo variabile opzionale che specifica alcune informaizoni sul segmento
- Payload: messaggio passato dall’application layer
Di seguito possiamo vedere un esempio di come vengono utilizzati i campi di sequenza e di ack.
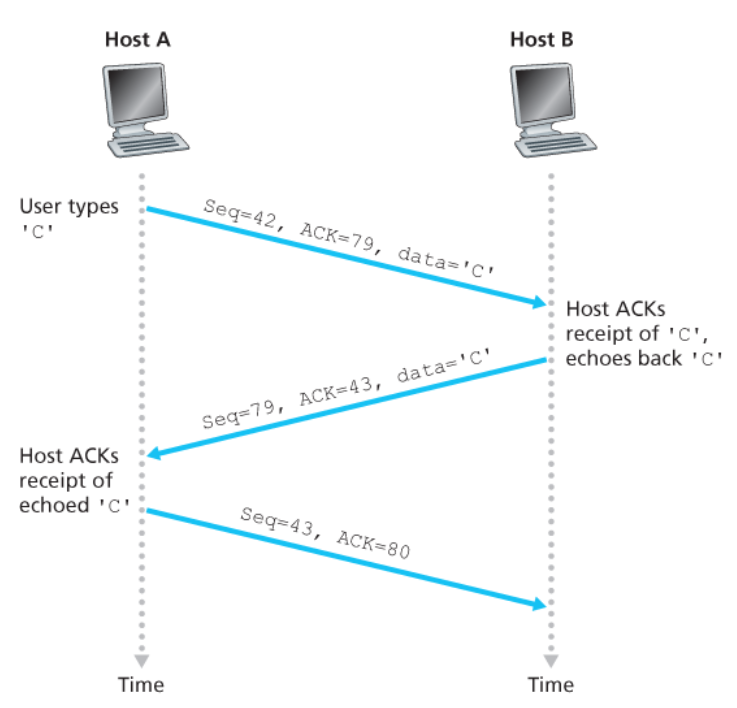
Questo esempio mostra un semplice scambio di una semplice applicazione Telnet tramite TCP
Come un host deve gestire dei segmenti out-of-order non è esplicitato dal protocollo. Questo infatti lascia libera scelta ai programmatori che creano le connessioni nel scegliere come comportarsi. In pratica vi sono due opzioni:
- Droppare i segmenti out-of-order e richiedere il segmento corretto: opzione più semplice da implementare
- Salvare i segmenti out-of-order in un buffer così da non doverli richiedere: più complesso da implementare ma permette di ottimizzare la banda della connessione.
Statisticamente la seconda opzione è quella più utilizzata.
2.4.1. TCP handshake
Client Side
Per creare un oggetto socket:
int sockD = socket(AF_INET, SOCK_STREAM, 0);
Per connettersi ad un socket:
int connectStatus = connect(sockD,
(struct sockaddr*)&servAddr,
sizeof(servAddr));
Questa connessione rappresenta la SYNSENT, ovvero l’invio di un segmento con:
SYN = 1Seq = x, dovexè un numero casuale scelto per evitare di recuperare segmenti di vecchie connessioni chiuse e scambiarli come ancora validi.
Il client attende adesso l’ack dal server. Quando lo riceve farà la ESTAB della connessione con un ultimo invio:
ACK = 1ACKnum = y + 1, doveyè il numero di sequenza del messaggio diACKricevuto
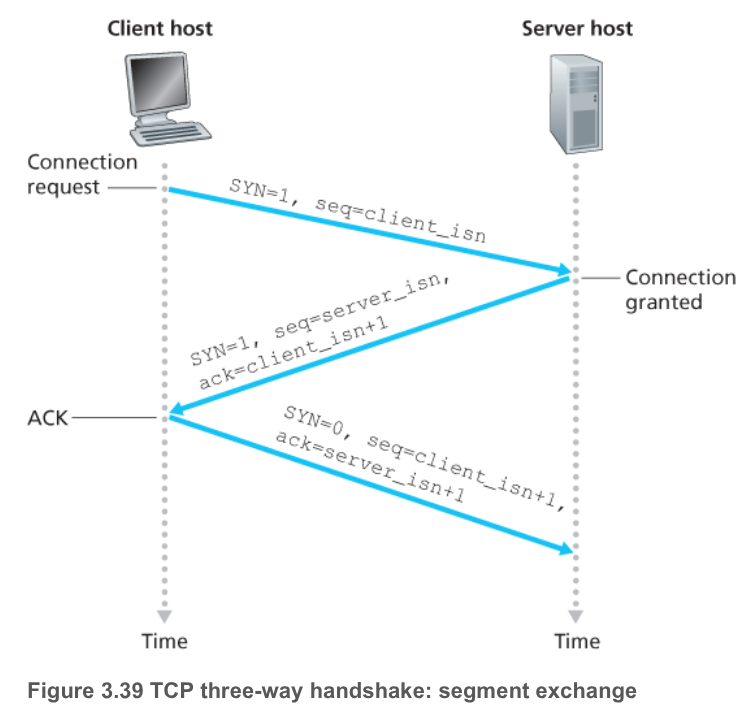
Server Side
Per creare un oggetto socket:
int servSockD = socket(AF_INET, SOCK_STREAM, 0);
// associo un indirizzo
bind(servSockD,
(struct sockaddr*)&serverAddr,
sizeof(serverAddr));
// metto in ascolto
listen(servSockD, 1)
Per accettare nuove connessioni:
int clientSocket = accept(servSockD, NULL, NULL);
La accept rappresenta la SYN RCVD, ovvero l’invio di un segmento con:
SYN = 1Seq = y, doveyè un numero casualeACK = 1ACKnum = x + 1
Da questo momento in poi i due host possono comunicare attraverso i socket.
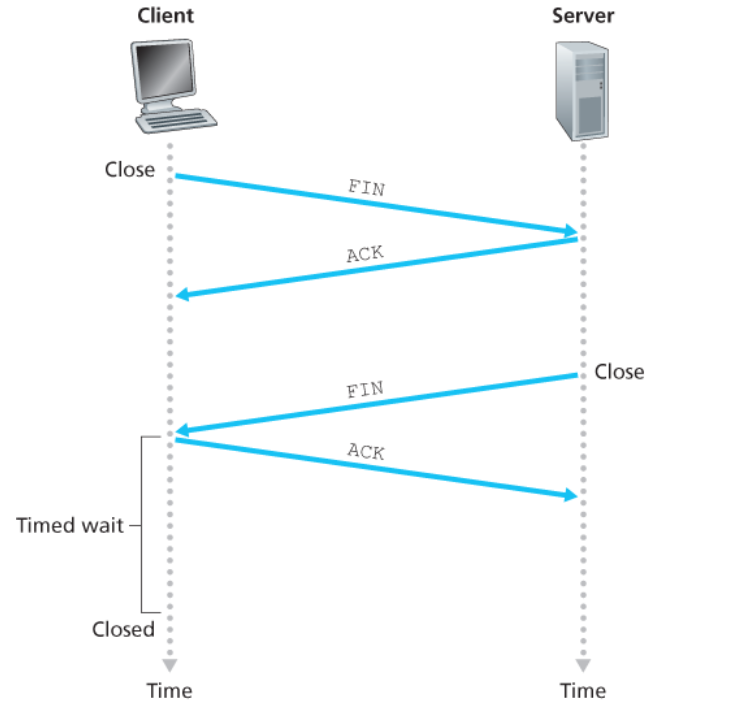
Quando vorremo chiudere la connessione i passaggi sono molto simili:
- Il client invia un segmento con
FIN = 1al server - Il server lo riceve e risponde con un
ACK. - Successivamente procede acnhe lui a chiudere la connessione inviando anche lui un segmento con
FIN = 1al client - Il client lo riceve il
FINe invia unACK, entrando in un timed wait - Il server riceve l’
ACK
Nella timed wait il client continua ad essere attivo. Questo è implementato per ovviare al problema che l’ACK finale potrebbe non arrivare al server.
Questi quindi reinvierebbe il FIN, rischiando però di trovare il client già spento ed entrando il un loop di invii che non vedrebbero mai risposta.
La timed wait quindi forza il client a stare ancora attivo così da poter ricevere eventuali nuove FIN dovute alla perdita dell’ACK.
Il TCP crea quindi un servizio di trasferimento dati affidabile basandosi sul servizio IP, che abbiamo detto essere inaffidabile.
Questo sistema, basato su finestre ACK e ritrasmissioni, e non differisce molto dall’rdt già visto precedentemente, se non per il problema del calcolo del timeout.
Mentre nel link layer ci basavamo sul RTT, adesso questo valore è variabile, a causa degli hop che un pacchetto deve fare.
Dobbiamo quindi riuscire a calcolare una stima del RTT del pacchetto che stiamo inviando partendo dai dati passati.
Il RTT misurato per un segmento, detto SampleRTT, è il tempo che passa dall’invio del segmento (il suo passaggio al network layer) fino alla ricezione del rispettivo ACK.
La maggior parte degli algoritmi TCP non misurano il SampleRTT per tutti i segmenti trasmessi ma ne misurano uno alla volta, ovvero non misuriamo il SampleRTT per i segmenti tra l’invio del misurato e il suo ACK.
Questo comporta che otteniamo un nuovo SampleRTT ogni SampleRTT.
Inoltre, il TCP non calcola mai il SampleRTT per un segmento ritrasmesso.
Ovviamente, il valore dei vari SampleRTT per segmenti diversi varierà, anche in maniera considerevole, a causa del routing e dei vari rallentamenti che comporta.
A causa di questa variazione, un dato SampleRTT può essere anche molto diverso dalla norma. Si rileva quindi necessario utilizzare un algoritmo che “filtri” questi valori per ottenere una specie di “media”, chiamata EstimatedRTT.
L’algoritmo della media campionaria non è molto funzionale, poiché le condizioni della rete variano molto nel tempo, e ciò comporterebbe che campioni troppo vecchi influenzerebbero in modo potenzialmente fatale la stima.
Utilizziamo quindi la media esponenziale mobile EWMA (Exponential Weighted Moving Average).
Definendo:
\(\text{SampleRTT} := RTT \\[0.25em]
\text{EstimatedRTT}:=ERTT\)
Otteniamo che: \(\begin{align*} {ERTT}_{1} &= {RTT}_{0} \\ {ERTT}_{2} &= \alpha \cdot {RTT}_{1} + (1-\alpha) \cdot {RTT}_{0} \\ {ERTT}_{3} &= \alpha \cdot {RTT}_{2} + \alpha(1-\alpha) \cdot {RTT}_{1} + (1-\alpha)^2 \cdot {RTT}_{0} = \alpha \cdot {RTT}_{2} + (1-\alpha) \cdot {ERTT}_{2}\\ &\vdots \\ \end{align*}\)
La formula finale sarà quindi una media pesata ricorsiva: \(\boxed{\text{EstimatedRTT} := (1-\alpha) \cdot \text{EstimatedRTT} + \alpha \cdot \text{SampleRTT}}\)
Il valore consigliato per $\alpha = \frac{1}{8} = 0.125$ [RFC 6298], rendendo la formula:
\(\boxed{\text{EstimatedRTT} := 0.825 \cdot \text{EstimatedRTT} + 0.125 \cdot \text{SampleRTT}}\)
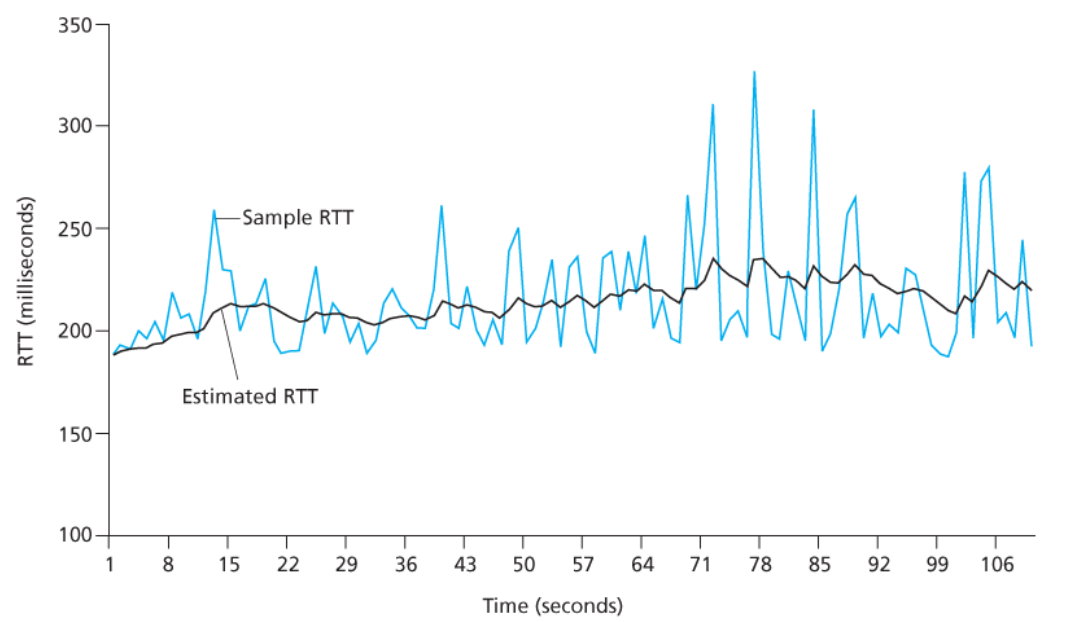
Esempio di valori di una connessione tra gaia.cs.umass.edu e fantasia.eurecom.fr
La stima è per sua natura imprecisa. Per riuscire a calcolare il timeout effettivo dobbiamo quindi inserire una sorta di margine di errore.
Poiché variazioni elevate di ERTT necessitano di un margine più elevato, una prima idea era quella di mettere come margine un altro ERTT.
Anche se questo approccio funziona, si possono fare scelte migliori, come ad esempio il quadruplo della variabilità.
La variabilità DevRTT è una stima di quanto SampleRTT varia da EstimatedRTT:
\(\text{DevRTT} = (1-\beta) \cdot \text{DevRTT} + \beta \cdot | \text{SampleRTT} - \text{EstimatedRTT}|\)
Il valore consigliato di $\beta$ in questo caso è di $\beta = \frac{1}{4} = 0.25$.
Il timeout viene quindi calcolato come $1$ secondo inizialmente [RFC 6298], e successivamente come:
\(\boxed{\text{TimeoutInterval} = \text{EstimatedRTT} + 4 \cdot \text{DevRTT}}\)
2.4.1.1. TCP Sender
Vediamo adesso una versione semplificata di TCP sender.
Il TCP sender deve gestire 3 eventi:
- Ricezione dati dall’applicazione: deve fare i seguenti passaggi:
- Creare un segmento con
seq #, dove#è calcolato rispetto ai byte inviati nel segmento inviato precedentemente. Ovvero la posizione del primo byte nel segmento in riferimento allo stream - Inizializzare il timer se non è stato già fatto, infatti potrebbe essere presente un timer riferito ad un segmento precedente che non ha ancora ricevuto l’
ACK.Il timer è infatti preso in riferimento al più vecchio segmento che non ha ancora ricevutoACK.
- Creare un segmento con
- Timeout: deve fare i seguenti passaggi:
- Ritrasmette il segmento che ha causato il timeout
- Riavvia il timer
- Ricezione dell’ACK: deve fare i seguenti passaggi:
- Se si riferisce a un segmento
unACKed, aggiorno quello che ora èACKede aggiusto il timer in modo adeguato
- Se si riferisce a un segmento
Di seguito possiamo vedere dello pseudocodice che più implementare un TCP sender:
/*
* Assumiamo che:
* - il sender non sia legato al TCP flow né al congestion control
* - che tutti i messaggi siano più piccoli di MSS
* - che i dati vengano trasferiti in un unico verso
*/
NextSeqNum = InitialSeqNumber;
SendBase = InitialSeqNumber;
while(1){
switch(event){
case 'data received from above':
newSegment = create_TCP_segment(NextSeqNum, data);
segments[NextSeqNum] = newSegment;
if(!timer){
start(timer);
}
passToIP(newSegment);
addToNotACK(newSegment);
NextSeqNum += length(data);
break;
case 'timer timeout':
passToIP(getOldestNotACK());
reset(timer);
break;
case 'ACK received':
if(y > SendBase){
SendBase = y;
// rimuovo i segmenti con seq <= SendBase
removeFromNotACK(SendBase);
if(getOldestNotACK() != NULL)
reset(timer);
}
break;
}
}
Uno dei problemi con la ritrasmissione dovuta a timeout, è prorpio il fatto che questo timeout può essere relativamente lungo. Quand oun segmento viene prso, questo lungo periodo di timeout costringe il trasmettitore ad attendere prima di ritrasmettere il segmento, aumentando di conseguenza il delay end-to-end.
Fortunatamente, il trasmettitore può rilevare la perdita di un pacchetto prima che l’evento di timeout avvenga, attraverso gli ACK duplicati.
Un ACK duplicato è un ACK che effettua un acknowledge per un segmento già ACKed.
Per capire meglio come il trasmettitore deve reagire ad un ACK duplicato capiamo prima perché il ricevitore dovrebbe inviarlo:
| Event | Azione ricevitore TCP |
|---|---|
Arrivo di un segmento con il seq atteso.Tutti i dati fino al numero di sequenza atteso sono già stati ACKed |
Invio del delayed ACK: Si attendono funo a 500 ms per l’arrivo di un altro segmento in ordine. Se questo non arriva nell’intervallo, allora si invia un ACK |
Arrivo di un segmento con il seq atteso. Vi è anche un altro segmento con numero di sequenza corretto in attesa della trasmissione dell’ ACK |
Viene immediatamente inviato un singolo ACK cumulativo, che effettua l’ACK di entrambi i segmenti. |
Arrivo fuori ordine di un segmento con seq più elevato di quello atteso.Rilevato un gap |
Invio immediato di un duplicate ACK, indicando il seq del prossimo byte atteso.Sarà l’estremo inferiore del gap. |
| Arrivo del segmento che riempie (parzialmente o completamente) il gap | Invio immediato dell’ACK qualora il segmento sia quello nell’estremo inferiore del gap |
In generale il case di invio degli ACK si complica:
initAllEntries(duplicatesACKsReceived, 0);
// ...
switch(event){
// ...
case 'ACK received':
if(y > SendBase){
SendBase = y;
// rimuovo i segmenti con seq <= SendBase
removeFromNotACK(SendBase);
if(getOldestNotACK() != NULL)
reset(timer);
}
else{
// Invio un ACK duplicato per un segmento già ACKed
duplicatesACKsReceived[y]++;
if(duplicatesACKsReceived[y] == 3){
/* TCP fast retransmit */
passToIP(segments[y]);
}
}
break;
}
2.4.2. TCP Flow Control
Gli host su ambo i lati di una connessione TCP hanno un buffer di ricezione dedicato alla connessione.
Quando vengono ricevuti dei byte corretti e in equenza, questi vengono inseriti nel receive buffer.
Il processo associato dell’application layer leggerà i dati proprio da questo buffer, anche se non è detto che lo faccia nel momento esatto in cui questi dati arrivano.
Infatti l’applicazione stessa potrebbe essere impegnata con altre task, oppure potrebbe non provare nemmeno a leggere i dati finché non è sicura che sono arrivati tutti. Se l’applicazione fosse relativamente troppo lenta a leggere i dati, il trasmettitore può facilmente riempire il buffer del ricevitore inviando troppi dati troppo velocemente.
Il protocollo TCP fornisce un servizio di flow-control alle proprie applicazioni per eliminare la possibilità che un trasmettitore possa sovraccaricare il ricevitore.
Il servizio di flow-control è quindi un servizio di sincronizzazione di velocità, cercando di far combaciare la velocità di lettura dei dati arrivati con quella di invio dei nuovi.
Il flow-control è implementato attraverso la receive window. Poiché il protocollo è full-duplex, entrambi gli host mantengono una receive window distinta.
Ipotiziamo che l’host A stia inviando un grosso file all’host B attraverso una connessione TCP.
B alloca un receive buffer per questa connessione, di dimensione RcvBuffer (di default 4KB).
Ogni tanto il processo applicazione dell’host B procederà a leggere dal buffer.
Definiamo quindi le seguenti variabili:
LastByteRead: è il numero dell’ultimo byte dello stream che il processo applicazione diBha letto dal bufferLastByteRcvd: è il numero dell’ultimo byte dello stream che è arrivato dal network ed è stato inserito daBnel buffer.
Poiché TCP non permette di fare overflow nel buffer, è necessario che:
\(\text{LastByteRcvd}-\text{LastByteRead} \le \text{RcvBuffer}\)
La receive window rwnd sarà quindi la dimensione rimanente nel buffer:
\(\text{rwnd} = \text{RcvBuffer} - \bigl[\text{LastByteRcvd}-\text{LastByteRead}\bigr]\)
Poiché lo spazio rimanente può campiare nel tempo, rwnd è calcolata dinamicamente.
Inizialmente B imposta rwnd = RcvBuffer e invia il primo segmento.
L’host A terrà invece traccia di due variabili LastByteSent e LastByteAcked. Per avere la la certezza di non sovraccaricare il buffer di B deve premurarsi che:
\(\text{LastByteSent} - \text{LastByteAcked} \le \text{rwnd}\)
Questo calcolo però ha un problema intrinseco.
Immaginiamo che A cominici ad inviare messaggi finché rwnd = 0. A riceve questa informazione dall’ultimo ACK che riceve.
A questo punto A non invierà più messaggi attendnedo che B legga i messaggi nel buffer così da liberare spazio.
Tuttavia, smettendo di inviare messaggi B non invierà più ACK, quindi A non riceverà mai la notifica della liberazione del nuovo spazio.
Per risolvere questo problema, le specifiche del TCP sanciscono che A continui a inviare segmenti di dimensione 1 Byte quando la finestra di B è zero.
Poiché il buffer è destinato a svuotarsi prima o poi, i segmenti di acknowledged conterranno valori rwnd non nulli, permettendo ad A di ripendere con l’invio di messaggi più grandi.
Il flow-control non è implementato dal protocollo UDP, che quindi può soffrire di perdita pacchetti dovute al buffer overflow.
2.4.3. TCP Congestion Control
Le ritrasmissioni, utilizzate dal TCP per avere un flusso dei dati affidabile.
Questo però ha una conseguenza molto rilevante, infatti la trasmissione multipla di molti pacchetti può portare a congestionare la rete.
La ritrasmissione infatti cura uno dei sintomi della congestione (la perdita dei pacchetti), ma non la causa stessa di essa.
Vi possono essere diversi motivi per i quali si genera una congestione di rete vediamo il più semplice:
Immaginiamo due host A e B che comunicano attraverso un singolo router con degli altri host (C e D).
Immaginiamo che A trassmetta dati ad uno dei due host ad un rateo medio di $\lambda_{in}$ byte/s. Ignorando gli overhead aggiuntivi, e i controlli di flusso e congestione, l’host offre un traffico al router proprio di $\lambda_{in}$ byte/s.
Anche l’host B si comporta nel medesimo modo, trasferendo anche lui con la medesima velocità.
I pacchetti provenienti dai due host arriveranno al router attraverso il medesimo mezzo di capacità $R$. Immaginiamo per semplicità che il router abbia a disposizioni sufficienti buffer a contenere tutti i pacchetti anche quando il rateo di entrata dei paccheti eccede quello di uscita.
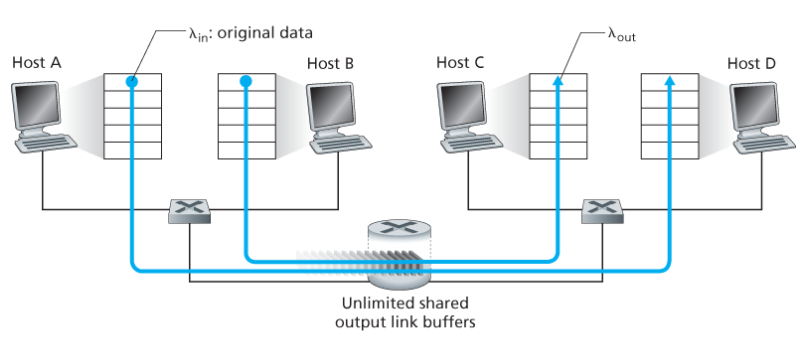
Se si ha un rateo di invio $\lambda_{in} \in [0, \frac{R}{2}]$ il rateo di arrivo medio $\lambda_{out}$ è uguale al rateo di invio medio del trasmettitore $\lambda_{in}$.
Se però $\lambda_{in} > \frac{R}{2}$ il throughput continua ad essere limitato a $\frac{R}{2}$. Questo limite superiore è la naturale conseguenza del condividere la capacità del link tra le due connessioni.
Seppur l’utilizzo completo del link possa sembrare una buona cosa, il realtà l’utilizzo a piena capacità del link aumenta esponenzialmente il delay tra pacchetti.
Esistono quindi diversi approcci per implementare il congestion control:
- Network Assisted congestion control: il router fornisce un feedback esplicito al trasmettitore e/o al ricevitore riguardanti lo stato di congestione della rete. Questo può avvenire attraverso un bit che indica proprio la congestione del link. Questo approccio non è però molto utilizzato oggi
- End-to-end congestion control: il network-layer non fornisce nessun supporto specifico al transport-layer per effettuare il congestion control. La presenza di congestioni viene dedotta dai sintomi che questa comporta come: aumento del
TTR, tripliciACKduplicati, timeout. Questi eventi non sono necessariamente correlati alla congestione, tuttavia ilTCPnon ha modo di capirne la vera motivazione, e quindi esegue una mossa conservativa, trattando questi eventi come indice di congestione.
2.4.3.1. Explicit Congestion Notification - ECN
L’approccio network assisted opera delegando al router di settare due bit nell’header IP (campi ToS) per indicare la congestione, e procede a inoltrare il essaggio al destinatario.
Sucessivamente, il destinatario, setterà il bit ECE nel segmento di ACK di ricezione del segmento e lo inoltrerà al trasmettitore.
QUando il trasmettitore lo riceverà procederà a dimezzare cwnd, e setterà CWR nell’header del successivo segmento da inoltrare.
Questo metodo coinvolge sia il protocollo IP che quello TCP
2.4.4. TCP End-to-End Congestion Control
Il TCP utilizza l’approccio end-to-end.
Dobbiamo però adesso cpaire come reagire al rilevamento della congestione. Se tutti i trasmettitori azzerassero il rateo di invio, per quanto è vero che la congestione scomparirebbe, è vero anche che i ricevitori continuerebbero a non veder arrivare alcun pacchetto.
Per decidere come agire dobbiamo rispondere a tre domande fondamentali:
- Come fa il trasmettitore a limitare il proprio rate dopo aver rilevato congestione?
- Come fa il trasmettitore a rilevare la congestione?
- Come fa il trasmettitore a aggiustare il proprio rateo dopo aver rilevato la congestione?
Il parametro sul quale agiamo si chiama congestion window cwnd.
Il cwnd impone nu limite sul rateo al quale un trasmettitore TCP può instradare traffico nella rete.
In generale è di nuovo vero che: \(\text{LastByteSent} - \text{LastByteAcked} \le \text{cwnd}\)
In generale quindi un trasmettitore limiterà il suo invio secondo la legge: \(\boxed{\text{LastByteSent} - \text{LastByteAcked} \le \min\{\text{rwnd}, \text{cwnd}\}}\)
In generale il rateo di invio del trasmettitore è di circa: \(\text{rate} = \frac{\text{cwnd}}{\text{RRT}} \;\;\text{bytes/s}\)
Una semplificazione dell’approccio che il trasmettitore segue si chiama Additive Increase, Multiplicative Decrease (AIMD):
Il trasmettitore prova costantemente ad aumentare di 1 il rateo di invio del
MSS. Quando si verifica un sintomo della congestione (perdita di un pacchetto, timeout, triplo ACK).dimezza il rateo di invio.
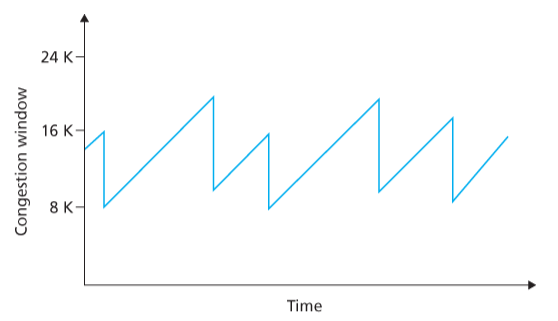
Il vero algoritmo che il TCP utilizza è più complesso.
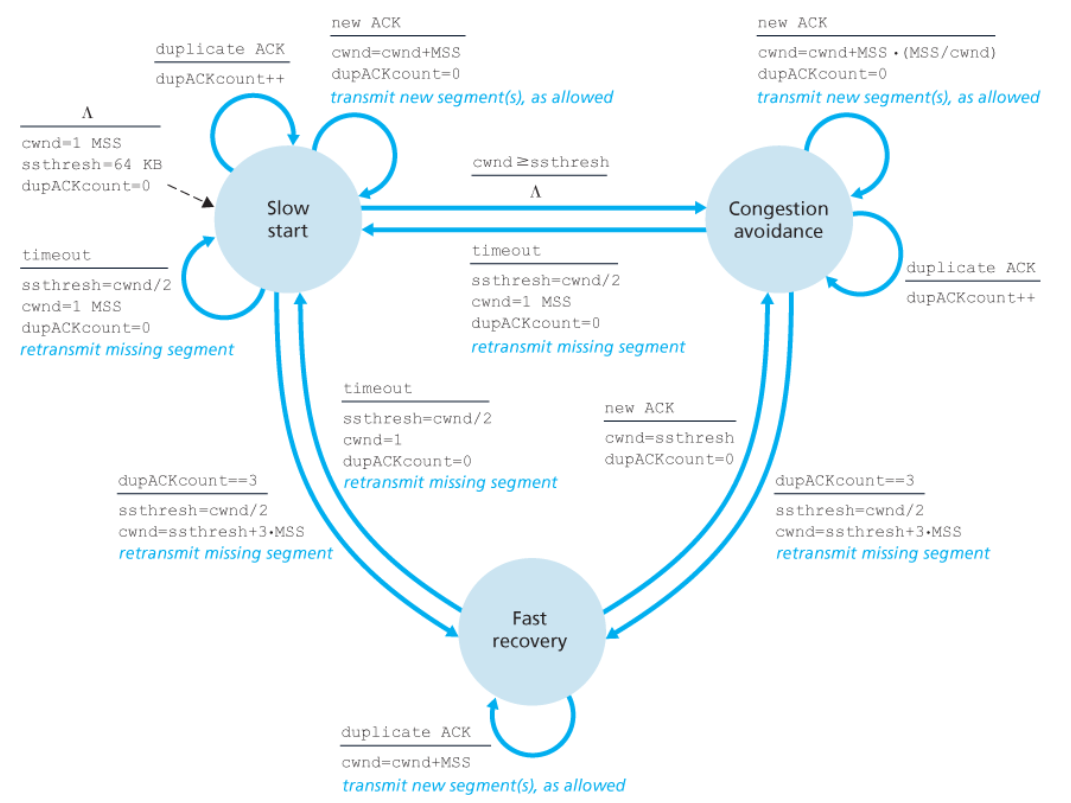
Si divide in tre fasi:
- Slow start: si parte con una finestra piccola per poi ampliarla in modo esponenziale
- Congestion Avoidance: si aumenta il più possibile la finestra finché non si verifica la congestione
- Reaction to Loss Events:
Quando una connessione viene avviata, lo slow start impone di partire con finestre cwnd = 1 MSS.
Successivamente, ad ogni ACK si raddoppia la finestra.
Nel caso tutto vada bene si invieranno $1, 2, 4, 8, 16, …$ pacchetti a volta.
Ad un certo punto si raggiungerà una soglia ssthresh, che inizialmente è di 64 KB.
Quando si supera la soglia si passa nella seconda fase (congestion avoidance), dove adesso si aumenterà la finestra di 1 MSS alla volta.
Quando si verifica un sintomo di congestione l’algoritmo agisce in modo differente in base al sintomo:
- 3 ACK duplicati: rimango nella fase di congestion avoidance, mantenendo un approccio di fast recovery
ssthresh = cwnd / 2cwnd = cwnd / 2 + 3
- Timeout: rientro nella fase di slow start
ssthresh = cwnd / 2cwnd = 1 MSS
L’aggiornamento del valore della soglia è indipendente dal proprio valore precedente, ma dipende esclusivamente dal valore della finestra prima che si verifichi un sintomo.
Di seguito possiamo trovare sulla sinitra la macchina a stati finiti dellì’algoritmo del TCP congestion control.
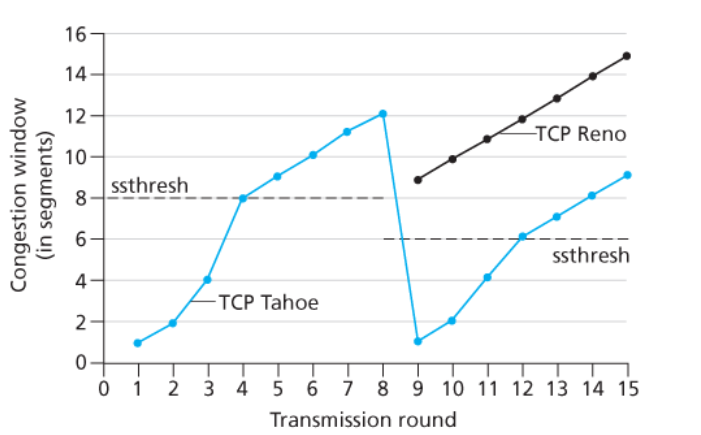
Sulla destra nivece è proposto un esempio di come possono variare nel tempo i valori della inestra e della soglia.
Nella fase di slow start, quando arriva un nuovo ACK è segnato che si aumenta “solo di 1” la finestra.
Sottolineiamo che questo avviene per ogni ACK ricevuto.
Quindi se arrivano $n$ ACK avremo incrementato di $n$ MSS, ottenendo una finestra totale di $2\cdot n$ MSS.
Oltre all’approccio AIMD, esiste un altro approccio, detto TCP CUBIC, che utilizza una funzione cubica per effettuare il controllo della congestione.
Questo approccio è quello di default in sistemi Linux ed è l’approccio più popolare nei web server.
2.4.5. TCP fairness
L’obiettivo della fairness nel caso delle connessioni TCP è che, se $K$ sessioni condividono il medesimo bottleneck di banda $R$, entrambi dovrebbero inviare con un rateo medio di $\frac{R}{K}$
Se ipotizziamo di avere due sessioni TCP in “competizione”, dove all’inizio il rateo è quello mostrato dal pallino rosso.
Entrambi sono nella fase di congestion avoidance, quindi spostano il pallino lungo la diagonale parallela alla bisettrice del semipiano.
Succederà prima o poi al punto in cui la trasmissione supera il limite, provocando un dimezzamento in entrambe le finestre.
Questo continua ad accadere di nuovo e di nuovo e di nuovo…..
È possibile dimostrare matematicamente (non lo faremo) che il pallino tenderà sempre di più a oscillare verso il punto ideale (il punto verde).
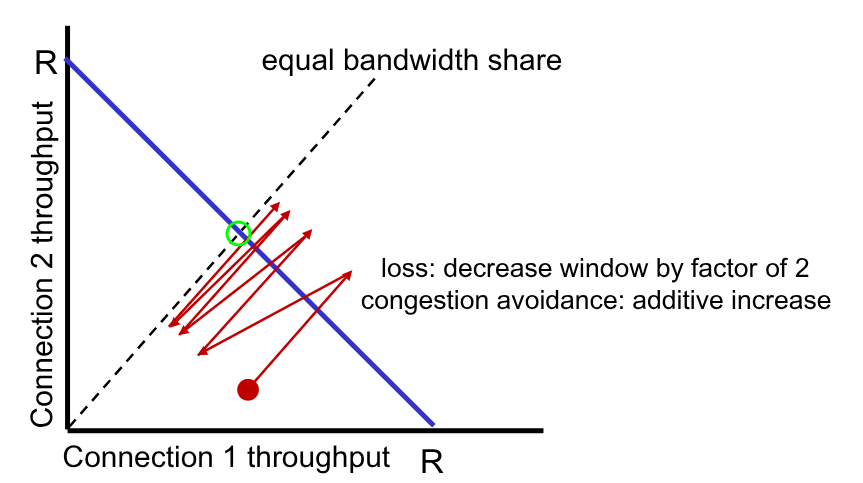
Consideriamo quindi l’algoritmo come fair.
La fairness però può non sempre essere desiderata in casi di applicazioni particolari.
In quei casi può essere un opzione utilizzare connessioni UDP.
Le applicazioni multimediali spesso desiderano di avere un rateo di invio costante, e non vogliono essere limitate dal congestion control.
Attraverso UDP non si è limitati nessun servizio
Se volessimo invece continuare a a utilizzare la connessione TCP, è possibile aprire connessioni parallele multiple tra due host.
Questo approccio non è molto fair, e molti amministratori di rete limitano il numero di connessioni TCP che si possono aprire verso uno stesso destinatario.
2.5. Evoluzione del layer di trasporto
I protocolli TCP e UDP sono i protocolli di trasporto principali degli utlimi 40 anni, e ne esistono di diversi tipi.
Tuttavia nessuno di questi supporta funzioni di sicurezza, ed è quindi necessario aggiungere un ulteriore layer, detto transport security layer, che ha altri handshake e aggiunge overhead.
Le tecniche moderne utilizzano un nuovo protocollo, detto QUIC.
È un protocollo di application layer, che si appoggia sul protocollo UDP come protocollo di trasporto, ma implementa tutte e sole le proprietà del livello TCP.
L’insieme tra HTTP/2 e QUIC è quello che oggi chiamiamo HTTP/3