1. Indice
- 1. Indice
- 2. Che cos’è internet
- 3. Protocolli
- 4. Network Edge
- 5. Network Core
- 6. Performance
- 7. Sicurezza
- 8. Protocolli e Servizi
2. Che cos’è internet
Non esiste una risposta univoca alla domanda “Che cos’è internet?”, ma dipende dal punto di vista.
Dall’interno
Se si guarda dall’interno, possiamo definirlo come:
Un sistema che connette milardi di dispositivi attraverso link di comunicazione che si dividono in:
- Host: si trovano alla “periferia” della rete
- Packet Switches: inviano pacchetti di reti
Possiamo quindi dire che Internet è una rete di reti che connette miliardi di host sui quali girano le applicazioni.
Quando parliamo di host non intendiamo solamente dei calcolatori, ma tutte le tipologie di dispositivi connessi (smartwatch, telecamenre, pacemaker, tostapane, lavatrici, occhiali AR). Questa nuova modulaizone del mondo è chiamata Internet of Things, dove ogni oggetto può essere collegato e interrogato tramite internet.
Internet segue una serie di protocolli di standardizzazione che permettono la corretta comunicazione tra più host.
Gli istituti di standardizzazione sono diversi, uno ad esempio è IETF (Internet Engineering Task Force) che pubblica documenti chiamati RFC (Request For Comments). Questi documenti sono analizzati e approvati, andando a generare i protocolli.
Servizio
Possiamo vedere Internet come un Servizio, ovvero un’infrastruttura che fornisce servizi per le applicazioni. Fornisce interfaccie per il corretto utilizzo di applicazioni distribuite.
3. Protocolli
Un protocollo è un insieme di regole che definiscono il formato e l’ordine dei messaggi che devono essere inviati e ricevuti tra più entità, stabilendo le azioni che devono essere effettuate.
Questi protocolli sono adoperati anche dalle persone durante la vita di tutti i giorni:
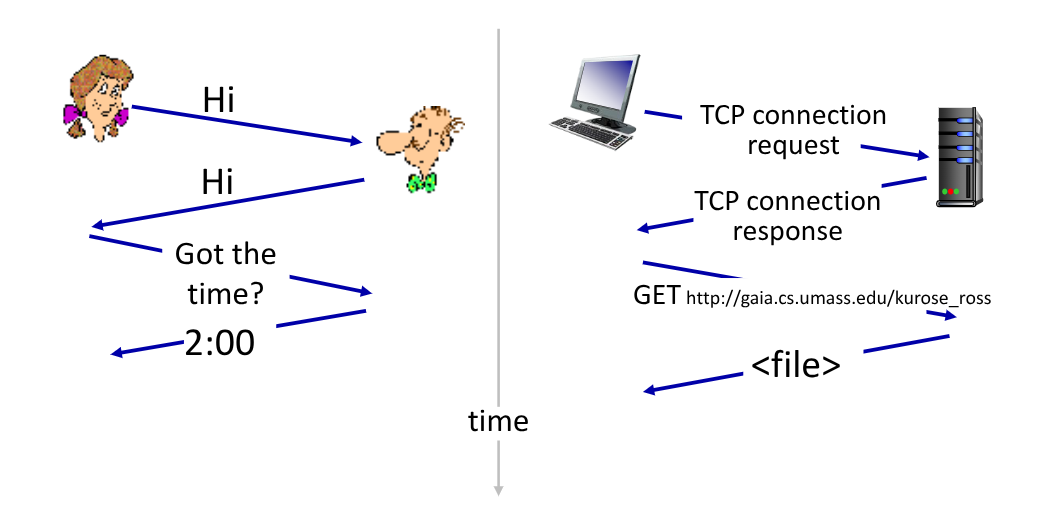
I protocolli utilizzati nel web sono del tutto analoghi con quelli umani
4. Network Edge
Il Network Edge (Periferia di Internet) rappresenta quella porzione di Internet dove si trovano gli host, ovvero i device che eseguono le applicazioni che si connettono ad Internet.
In un modello client-server gli host si dividono in:
- Client: l’host che chiede e utilizza un servizio
- Server: l’host che produce e distribuisce un servizio
Per client/server si intendono dei processi, e non la macchina client/server, che è il device sul quale si trova il processo.
I server si trovano tipicamente in dei Data Center, grossi centri che contengono molte macchine server.
Gli host si connettono ad internet tramite le reti di accesso, che si trovano proprio nella parte più esterna di internet. Il resto è chiamato Network Core, un’infrastuttura di distribuzione delle informazioni che si occupa di direzionarla alla rete di accesso corretta.
Per connettersi alle reti di accesso si possono utilizzare diversi metodi:
- Rete di accesso residenziale: permette l’accesso alla rete in un’appartamento
- Rete di accesso istituzionale: permette l’accesso alla rete in un contesto istituzionale (aziende, scuole, …)
- Mobile: permette l’accesso da remoto
Non siamo interessati tanto alla tecnologia di accesso, ma piuttosto il trasmission rate (che è necessariamente minore o uguale a quello e della rete di accesso) e se il tipo di connessione è dedicato (Ethernet) o condiviso (Wi-Fi).
4.1. Rete di Accesso: DSL
È un vecchio standard ormai quasi in disuso. Era possibile ottenerne accesso tramite la stessa compagnia telefonica che gestiva l’accesso telefonico, che diventava quindi anche ISP.
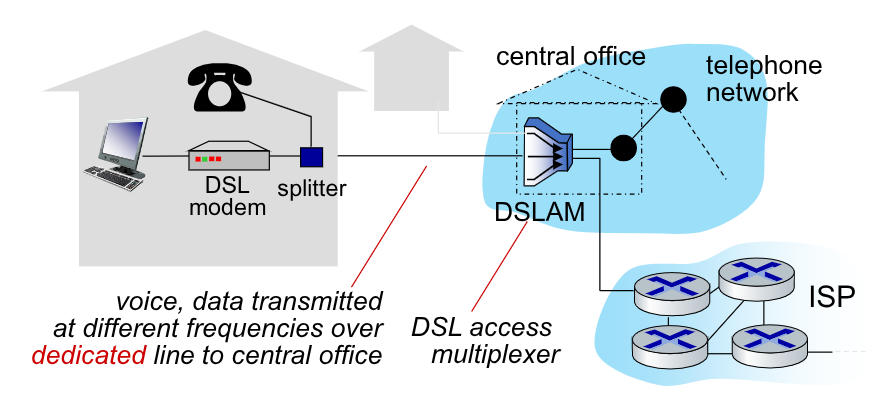
Venivano utilizzate le esistenti rete telefoniche per comunicare sulla rete, tramite uno splitter. Infatti le linee telefoniche trasferivano sia i dati che la voce in simultanea, codificandoli su frequenze diverse:
- Canale in dowstream ad alta velocità, banda 50 kHz - 1 MHz
- Canale in upstream a media velocità, banda 4 kHz - 50 kHz
- Normale canale telefonico a due vie, banda 0 kHz - 4 kHz
Le comunicazioni erano poi gestite dal DSLAM che smistava:
- La voce nella rete telefonica
- I dati nella rete internet
4.2. Fibra Ottica
Ne esistono diversi tipologie, in europa le più comuni sono le seguenti:
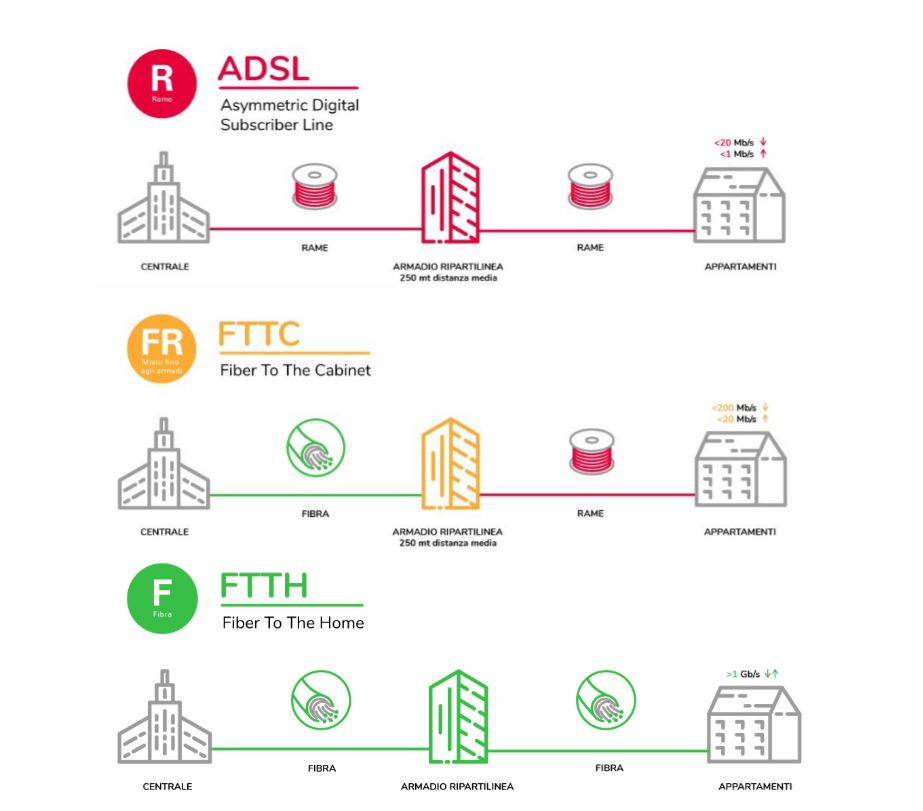
4.3. Wireless Access Networks
Si dividono in diverse categorie in base alle loro dimensioni:
- Wireless local area networks: tipicamente delle dimensioni di un edificio
- Wide-area cellular access networks: distribuiti dagli operatori di rete, ampiezze nell’ordine delle decine di kilometri.
Nelle reti istituzionali, ovvero quelle utilizzare dalle aziende, università, etc. si ha un mix di diverse tecnologie, che connettono switch e router.
4.4. Trasmissione dei pacchetti
L’host possiede due funzioni, quella di invio dati e quella di ricezione dati.
Quando un host deve inviare un messaggio ad un altro host, lo divide in tante sezioni, chiamati pacchetti, ognuno di lunghezza $L \text{ bits}$.
Le informazioni digitali salvate nei bit di informazione, vengono trasformati in segnali fisici che vengono trasmessi attraverso delle connessioni fisiche.
Ogni segnale fisico, per essere generato e trasmesso, necessita del tempo, chiamato bit-rate $R \text{ bits/s}$.
Questo valore è messo in rapporto con la lunghezza dei pacchetti per ottenere il ritardo di trasmissione, ovvero il tempo necessario per trasferire $L$ bit attraverso la connessione:
\(\quad {L \over R}\text{ s} \quad\)
Questo valore è diverso dal ritardo di propagazione, che invece è il tempo necessario per un segnale per percorrere lo spazio tra i due comunicanti.
I pacchetti viaggiano sui link di comunicazione, che si possono dividere in due categorie:
- Mezzi Guidati: il segnale è guidato ed è trasmesso in mezzi solidi (rame, fibra ottica, …)
- Mezzi Liberi: il segnale si propaga liberamente (radio, …)
Alcuni esempi di mezzi guidati sono:
- Doppino telefonico (Twisted Pair): consiste in due fili di rame all’interno di un isolante schermante. A seconda della schermatura e della qualità di rame utilizzato si possono avere più categorie:
- Categoria 5: trasmette da
100Mbpsfino a1Gbps - Categoria 6: trasmette fino a
10Gbps
- Categoria 5: trasmette da
- Cavo coassiale: è formato da due conduttori di rame concentrici. Permette più comunicazioni bidirezionali in parallelo, permettendo una comunicazione in banda comune. Veniva ad esempio utilizzato per la televisione, dove ogni canale riusciva a trasmettere nell’ordine delle
100s Mbps - Fibre Ottiche: i bit sono qui codificati in impulsi di luce, che si propaga molto più velocemente rispetto ai segnali elettrici. Questi mezzi hanno due grossi vantaggi rispetto agli altri:
- Non vengono influenzati da segnali elettromagnetici, mantenendo quindi un basso error rate anche tra ripetitori molto lontani. Nei conduttori di rame questo valore è $O(10^{-6})$ mentre nelle fibre ottiche è $O(10^{-11})$.
- Permette comunicazioni point-to-point fino alle
100s Gbps
I mezzi liberi invece sono generalmente segnali Radio. Questi mezzi trasportano il segnale attraverso lo spettro elettromagnetico, e non necessitano di “fili” o “cavi”.
Sono susciettibili ad effetti ambientali, quali riflessioni, interferenze e ostruzioni fisiche da oggetti schermanti. L’error rate è infatti nell’ordine di $O(10^{-3})$.
Ne esistono di diversi tipi:
- Microonde: canali che trasmettono fino a
45Mbps - Wireless LAN (Wi-Fi): velocità che variano da
300 Mbpsfino a oltre10 Gbps - Wide Area:
- 4G: nell’ordine delle
decine di Mbps - 5G: nell’ordine dei
Gbps, con latenza ridotta sotto i10ms
- 4G: nell’ordine delle
- Satellite: anch’essi fino a
45Mbpsma con tempi di delay nell’ordine dei270ms
5. Network Core
5.1. Packet Switching
In questa area non sono presenti host, ma solamente degli switch che si occupano esclusivamente di distribuire i pacchetti in entrata verso la loro destinazione. Questa azione di smistamento è chiamata packet-switching.
Il comportamento dei vari router è un comportamento store and forward: un router prima memorizza l’intero pacchetto, ne legge la destinazione, e successivamente lo trasmette al prossimo step della connessione che lo avvicinerà alla destinazione.
Se immaginiamo che $L = 10$ Kb e $R = 100$ Mbps, il tempo necessario per fare un salto è di $0.1$ ms.
Con $n$ salti (hop), immaginando che
- $L$ e $R$ siano costanti per ogni salto
- Sulla rete ci siano solamente 2 host che comunicano uno alla volta
- Il tempo di propagazione sia nullo
Il tempo totale è quindi di $n \cdot \frac{L}{R}$.
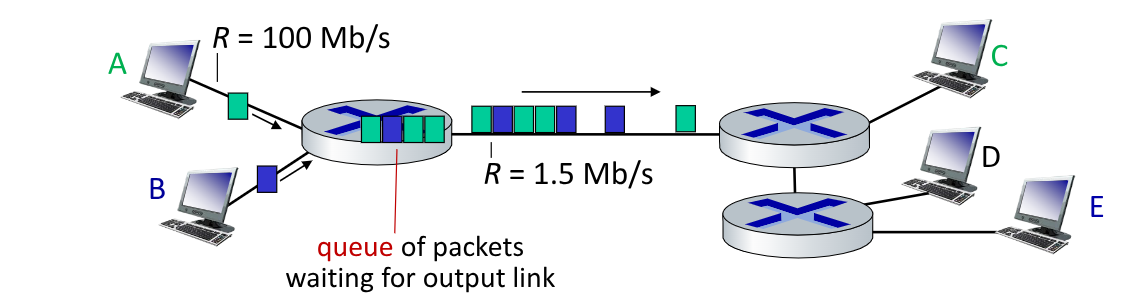
5.2. Circuit Switching
Immaginiamo ora un esempio più complesso. Immaginiamo 2 host che comunicano in uscita su reti con $R = 100$ Mbps verso lo stesso router. Sull’altro lato del router, lui comunica con un $R = 1.5$ Mbps verso un’altro router collegato a 3 host.
Il primo router quindi riceve in ingresso dati a 200 Mbps e li comunica con 1.5Mbps.
I pacchetti vengono quindi salvati in una coda interna al router in attesa di poter essere trasmessi.
Possono quindi verificarsi due casi:
- Il pacchetto subisce un ritardo chiamato proprio queue delay
- La coda si satura: avviene quindi una perdita dei pacchetti più recenti che non possono più essere salvati, generando una congestione del router
Un modo per evitare le congestioni è quello di fornire ai router più link in uscita, ognuno dedicato ad una comunicazione possibile. Questa configurazione si chiama circuit switching. In questo modo sono presenti connessioni end-to-end per ogni possibile connesione, che rimane idle quando i due host non stanno comunicando
Questa architettura era utilizzata comunemente nelle reti telefoniche tradizionali.
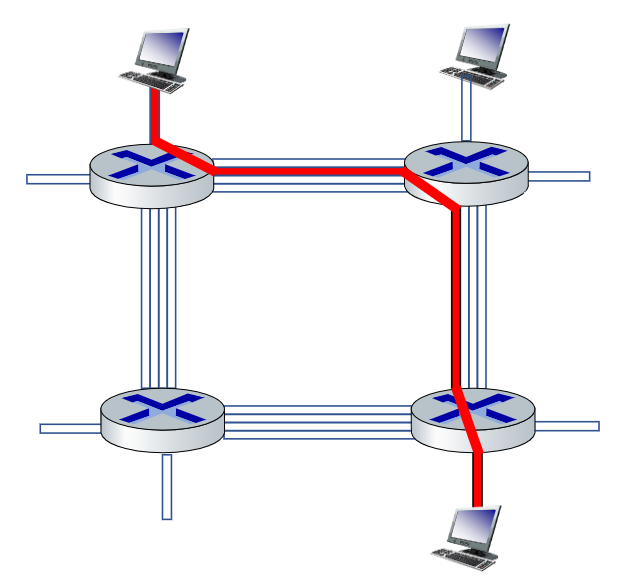
5.3. Packet Vs. Circuit
Il packet switching permette a più utenti di utilizzare un unica rete, e se ben configurata può ridurre le congestioni a un numero basso.
Se immaginiamo il seguente esempio:
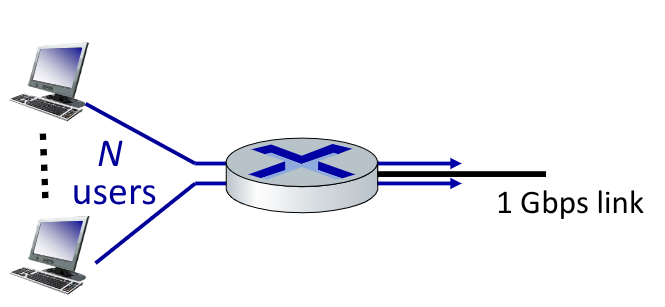
Ogni utente è attivo il 10% del tempo ad un rate di 100Mbps
Se immaginiamo il circuit-switching, per quanto sia vero che non abbiamo congestioni con 10 utenti, nel momento in cui gli utenti aumentano la congestione è garantita.
Se immaginiamo il packet-switching invece la probabilità che più di 10 persone siano attive allo stesso momento, necessario per saturare la connessione in uscita dal router, è di $\frac{1}{2500} = 0.0004$.
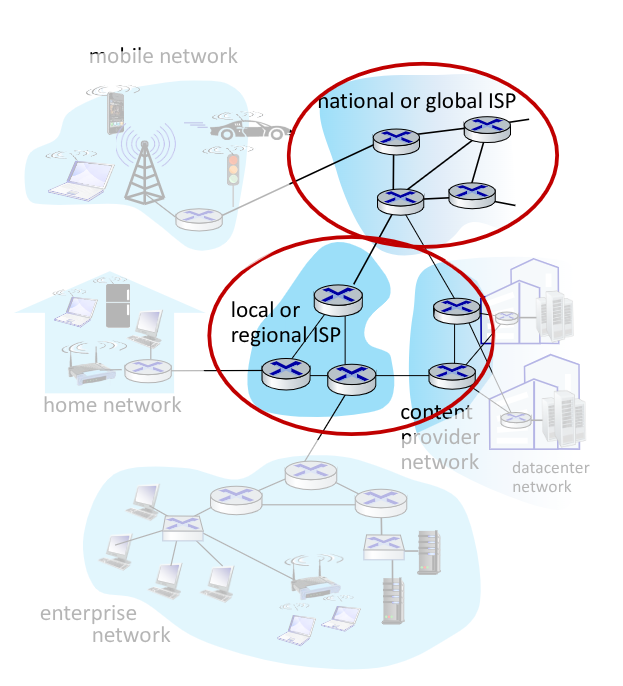
5.4. Struttura del Network di Network
Gli host si connettono ad internet tramite l’accesso fornito da un Internet Service Provider (ISP), che può fornire il servizio sia a livello residenziale che a livello aziendale.
I vari ISP devono essere però interconnessi, affinché le comunicazioni possano avvenire in maniera trasversale. CIò crea una rete di reti molto complessa, influenzata anche da motivi economici e politiche nazionali.
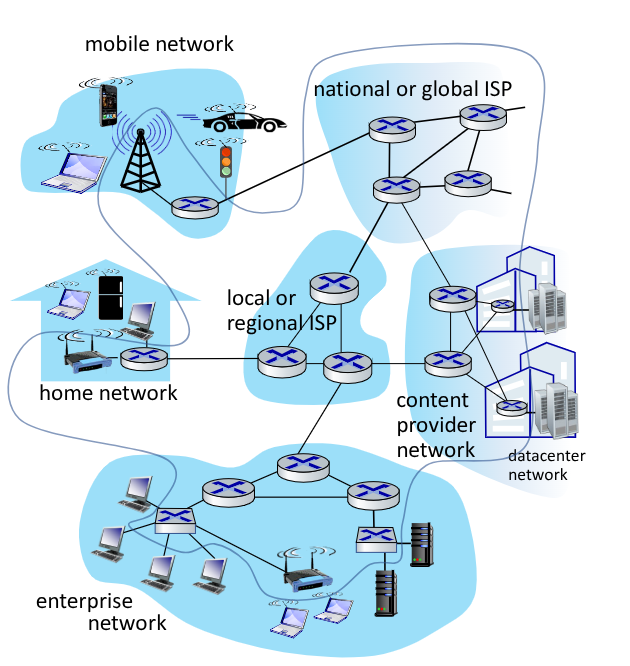
La struttura finale di internet di oggi assomiglia a qualcosa del genere:
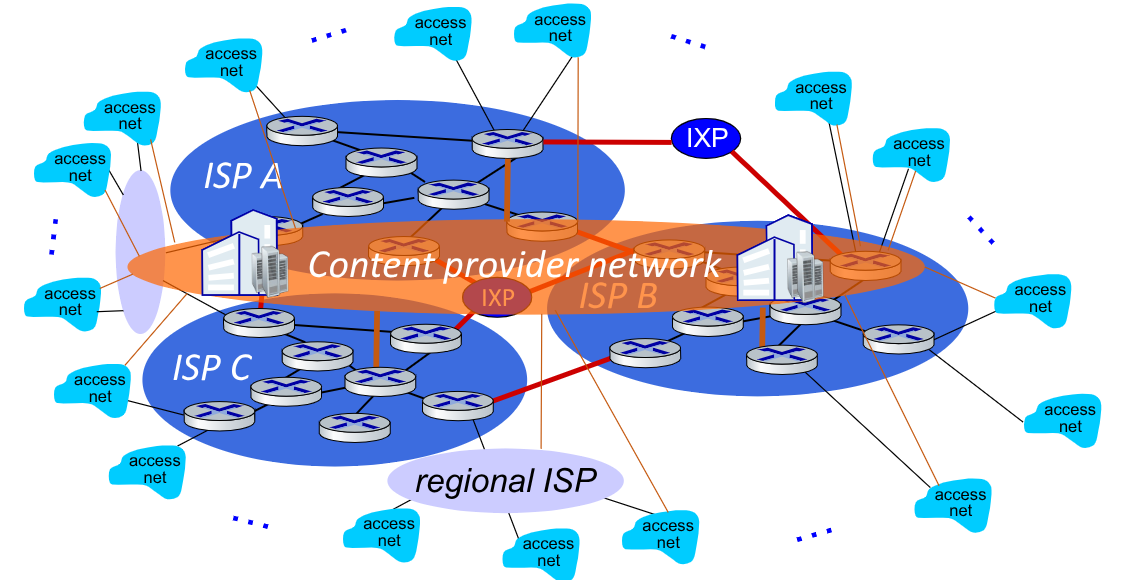
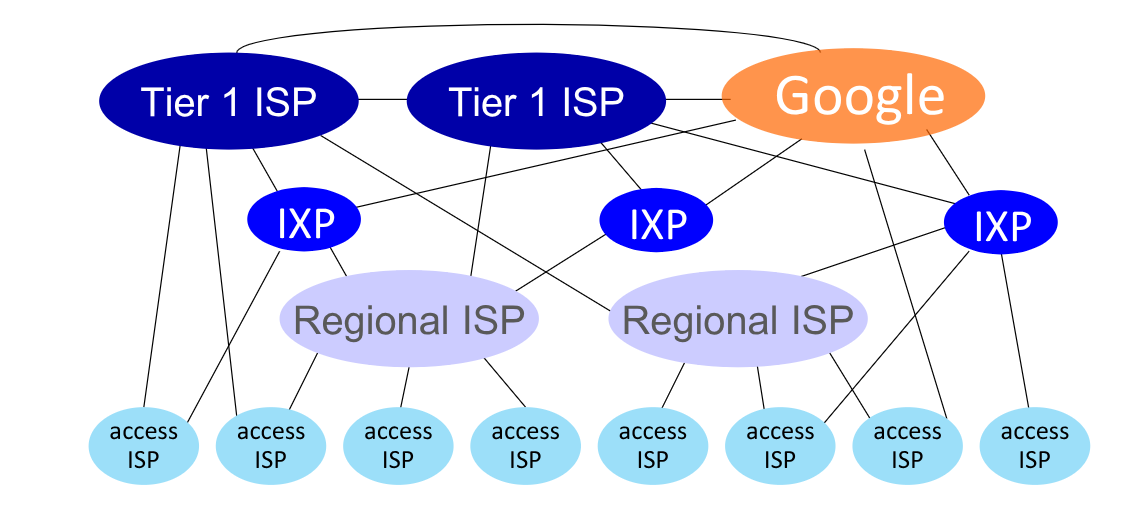
Possiamo quindi rappresentarla come una gerarchia:
6. Performance
Abbiamo già iniziato a vedere come possono avvenire le perdite di packetti e i vari delay.
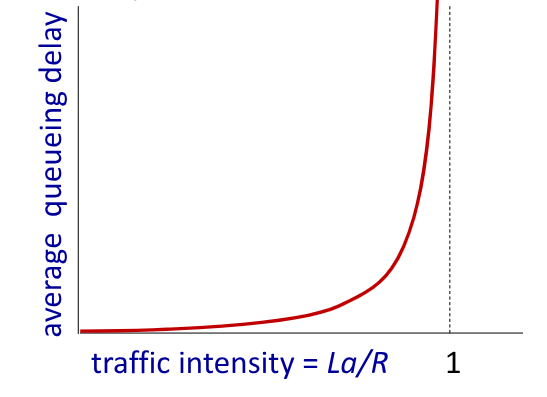
Il ritardo complessivo di un pacchetto è influenzato da 4 fattori:
- $d_{\text{proc}}$: ritardo di processing nel nodo, tempo impiegato dal router per analizzare il pacchetto e decidere come instradarlo. Tendenzialmente è nell’ordine di millisecondi e spesso trascurabile
- $d_{\text{queue}}$: ritardo di queueing, non è prevedibile e dipende dal livello di congestione del router
- $d_{\text{trans}}$: ritardo di trasmissione, calcolato come $\frac{L}{R}$
- $d_{\text{prop}}$: ritardo di propagazione, se la lunghezza del link è $l$ e la velocità di propagazione è $s$ si calcola come $\frac{l}{s}$
Avendo noti:
- $R$: larghezza di banda in
bps - $L$: lunghezza del pacchetto in
b
E variando $a$, ovvero il numero di pacchetti medi inviati
Il rate totale sarà quindi $a \cdot \frac{L}{R}$ e può valere:
- $\approx 0$: se il ritardo di queueing è piccolo
- $\approx 1$: se il ritardo di queueing è grosso
- $\gg 1$: abbiamo più pacchetti in entrata che in uscita, generando un ritardo infinito!
6.1. Ritardi e Instradamento
Nella vita reale sono presenti numerosi router tra sorgente e destinazione.
Per poter capire ad esempio in quali router un pacchetto arriva prima della destinazione si può usare il comando:
tracepath indirizzoDestinatario
Questo comando invia iterativamente 3 pacchetti con time-to-live uguale al numero dell’iterazione. Ogni volta che i pacchetti termineranno il loto ttl il router invierà un messaggio all’host sorgente con l’informazione del proprio IP. Il sorgente cronometra il tempo dall’invio e la ricezione e ripete finché i pacchetti non raggiungono ttl sufficiente per arrivare a destinazione.
6.2. Throughput
Il throughput è definito come il numero di pacchetti (o bit) che riescono a passare attraverso un certo link nell’unità di tempo. È una misura media, calcolato ad esempio come la portata di un fluido.
Se facciamo tendere $\Delta t \to 0$ allora otteniamo il throughput istantaneo.
In configurazioni del genere:
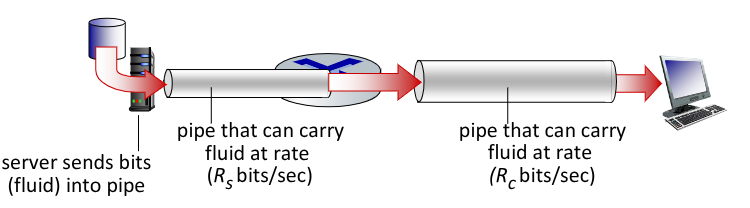
La connessione avrà un throughput medio uguale al minore tra i due. Questo effetto è chiamato bottolneck link.
In generale se ci sono $n$ link ognuno con throughput medio $R_i$, il throughput medio della connessione sarà: \(R_{\text{avg}} = \min_{i \in [1, n]}{\frac{R_i}{n}}\)
7. Sicurezza
Il mondo andava molto bene quando non c’erano gli hacker:
Persone che non hanno niente da fare che si divertono a danneggiare gli altri. […] cattivi ragazzi
cit. professore Anastasi
Tuttavia oggi ci sono, ed è quindi importante capire a quali possibili attacchi potremmo essere susciettibili:
- Malware, si dividono in:
- Virus: infezione che si auto-replica ricevendo/eseguendo degli oggetti
- Worm: infezione che si auto-replica passivamente ricevendo oggetti che si eseguono da soli
- Spyware Malware: può registrare alcune informazioni del dispositivo, come i tasti della tastiera cliccati o i siti web visitati, e salvare questi dati in quelli detti collection site
Alcuni tipi di attacchi sono:
- Denial of Service (DoS): gli attaccanti rendono le risorse di connessione dell’obiettivo inutilizzabili, sovraccaricandole con traffico inutile, sfruttando degli host compromessi precedentemente da botnet
- Packet Sniffing: principalmente su mezzi broadcast (wireless, ethernet condiviso, …) permette di leggere tutto il traffico sulla rete copiandoli e analizzandoli.
- IP Snooping: è possibile inviare pacchetti ad un destinatario modificando il sorgente, così da far credere al destinatario che il sorgente sia diverso da quello reale.
8. Protocolli e Servizi
Vediamo adesso com’è organizzato il protocollo che gestisce la comunicazione tra due host. Le comunicazioni sono infatti sono intrinsecamente complesse. Ciò è dovuto anche dlla struttura dei network, che comprendono molte componenti diverse tra loro, ad esempio:
- host
- router
- link diversi
- app
- protocolli
- hardware e software
Si cerca quindi un modo di organizzare la struttura del network, o perlomeno di cercare di organizzare le comunicazioni su network.
Prima di cercare di astrarre ciò che succede sul web, facciamo un esempio di quello che accade quando qualcuno prova a mandare una lettera.
Se un operatore $O_1$ vuole mandarla all’operatore $O_2$ questi sono i passaggi che avvengono:
- $O_1$ fornisce il messaggio ad un operatore alle Poste
- Le Poste lo trasferiscono al servizio di logistica
- Un corriere prenderà la lettere e la porterà fino ad un centro di sistamente
- Il centro di smistamento lo indirizzerà al centro di smistamento più vicino ad $O_2$
- Dal nuovo centro di smistamento un nuovo corriere lo porta al centro di logistica delle poste vicine ad $O_2$
- Un operatore lo recupererà e lo porterà a $O_2$
Per $O_1$ tutte queste operazioni sono sconosciute, e quello che vede è semplicemente che ha portato la lettera alle poste e questa è arrivata a $O_2$. Possiamo notare come il percorso di questa lettera sia simmetrica: I primi 4 step sono gli stessi degli ultimi 4, ma percorsi in due versi diversi
Possiamo quindi classificarli in due momenti diversi:
- I primi 4 sono la procedura di invio
- Le ultime 4 sono la procedura di ricevimento
Ognuno di questi step è chiamato layer, e fornisce un servizio attarverso le proprie azioni facendo affidamento ai layer sottostanti.
Questo approccio stratificato è un ottimo modo per affrontare task complesse, poiché divide il problema in problemi più piccoli e semplici, rendendo anche più semplice la manutanzione.
8.1. Internet Protocol Stack
Anche internet è gestito a strati.
I livelli di internet sono:
-
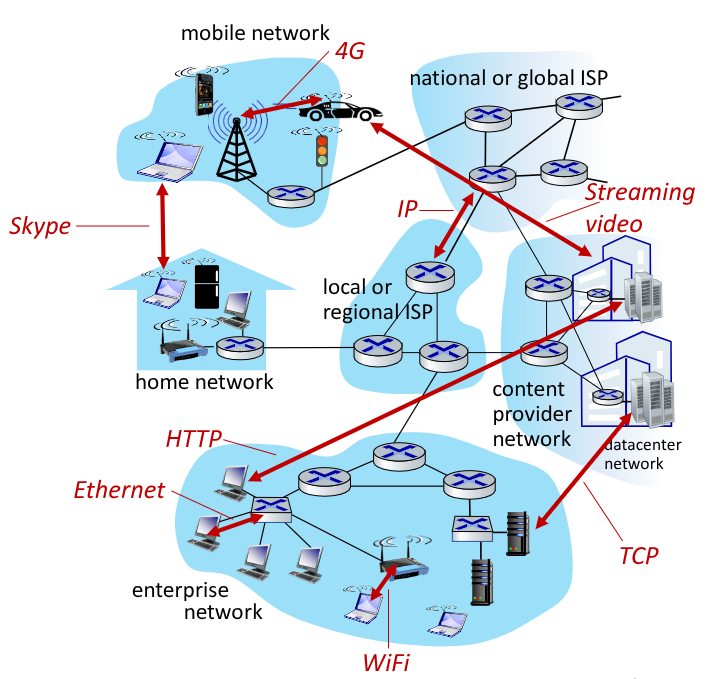
Applicazione: supportano le applicazioni di rete. Su questo livello si trovano client e server. Su questo livello si performano gli scambi tra client e server, infatti proprio in questo layer si possono generare richieste
HTTP,IMAP,SMTP, … -
Trasporto: trasforma i messaggi dei processi applicativi in datagrammi, per permetterne il trasferirento. Può farlo con più protocolli:
TCP,UDP, … -
Rete: direziona i messaggi (datagrammi) dal sorgente alla desinazione. A questo livello sono contenute le informazioni relative ai protocolli di routing e i vari indirizzi
IP -
Connessione: conserva le informazioni che permettono il trasferimento dei dati tra elementi vicini tra loro. Alcune tecnologie che si affidano alle informazioni contenute in questo livello sono l’
ethernet, le comunicazioni802.11 (Wi-Fi),P2P -
Fisico: È la comunicazione fisica dei
bitnei cavi
In realtà Internet oggi non segue esattamente questo modello, ma diverse azioni che nel modello appartengono a livelli diversi sono spesso gestite da altri.
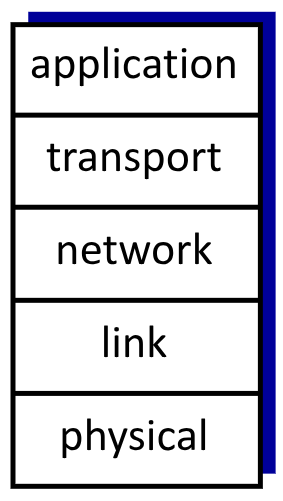
Il modello di internet si basa sul modello ISO/OSI, rimuovendone però due strati:
- Presentazione: permette le interpretazioni del significato dei dati (encryption, compressione, convenzioni macchina specifiche, …)
- Sessione: Gestiva la sincronizzazione, i checkpoint e il recovery dello scambio di dati
Internet non supporta nativamente questi step, che se fossero necessari devono essere manunalmente implementati nel livello applicazione.

Quello che succede quando si invia una richiesta è qualcosa del genere:
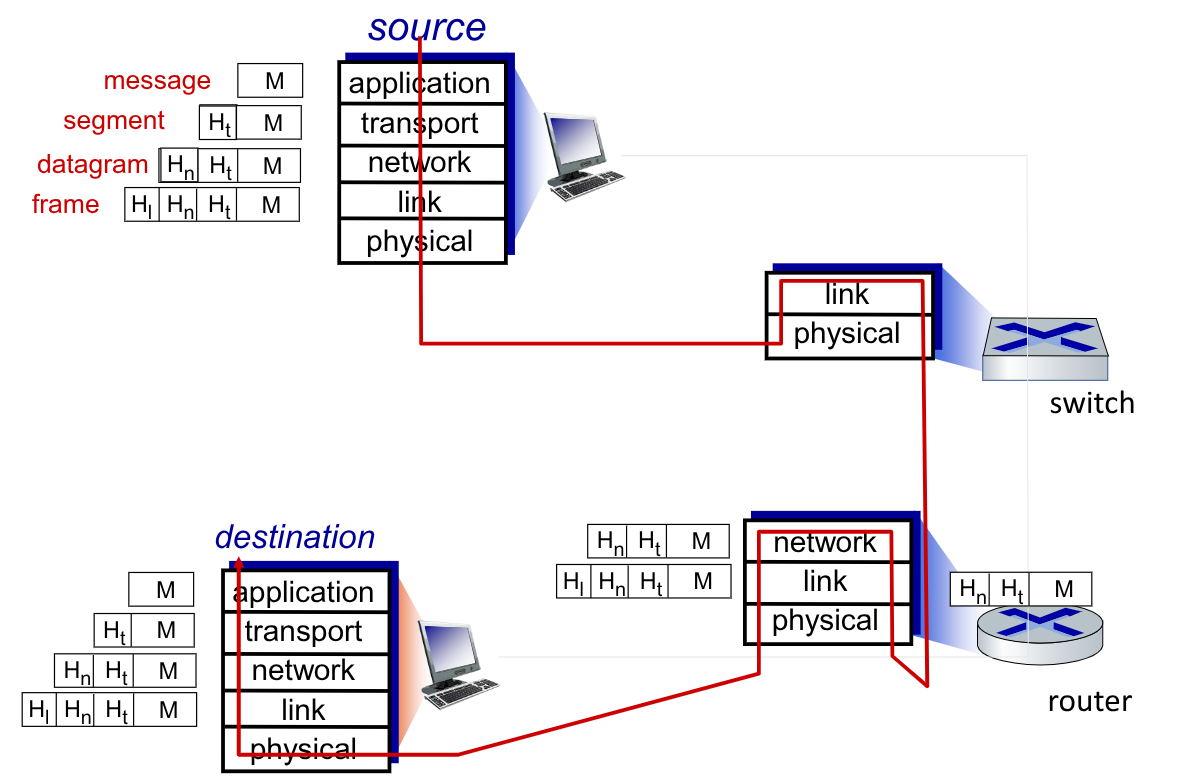
Il messaggio M viene incapsulato, aggiungendo tanti header quanti sono i livelli del modello, appesi sempre in testa, generando il frame.
Gli switch andranno a leggere solo i primi due header per deciderne l’istradamento.
Quando il frame arriva ad un router, questo andrà a leggere anche il 3° header per capire a quale dispositivo interno alla rete va trasmesso il frame, intradandolo internamente alla rete verso la destinazione.
La destinazione decodificherà il frame (diverso nel livello datalink modificato dal router), leggendone ad uno ad uno gli header, fino a capire qual’è il processo destinatario.
Il processo destinatario riceve quindi il messaggio M.