1. Indice
- 1. Indice
- 2. Interconnessione di Reti
- 3. La clessidra di internet
2. Interconnessione di Reti
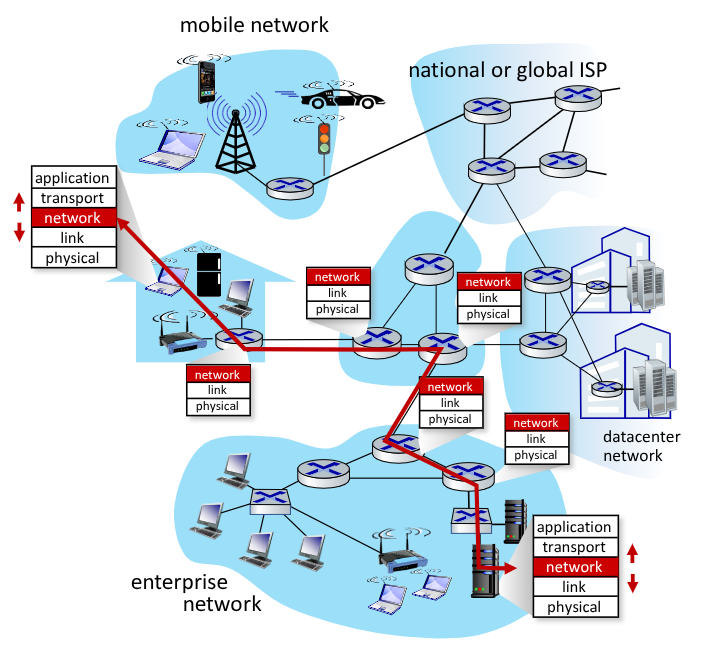
I servizi del network level permettono l’internetwork, ovvero tutti quei passaggi che permettono a più rete indipendenti, anche di tipo diverso, di comunicare tra loro in modo trasparente.
Al momento di una trasmissione:
- Il trasmettitore incapsula il segmento all’interno del datagramma passandolo al link layer
- Il ricevitore “spacchetta” in datagramma trasmettendo il segmento al transport layer
I protocolli di livello network si trovano in tutti i dispositivi internet.
Il router esamina i campi nell’header del datagramma IP e lo direziona eseguendo forwarding.
Il network layer ha due funzioni principali:
- Forwarding: ovvero spostare i pacchetti dal link di entrata di un router verso il corretto link di uscita
- Routing: determina come instradare un pacchetto per farlo arrivare alla destinazione. Vedremo come questo percorso viene calcolato attraverso algoritmi di routing.
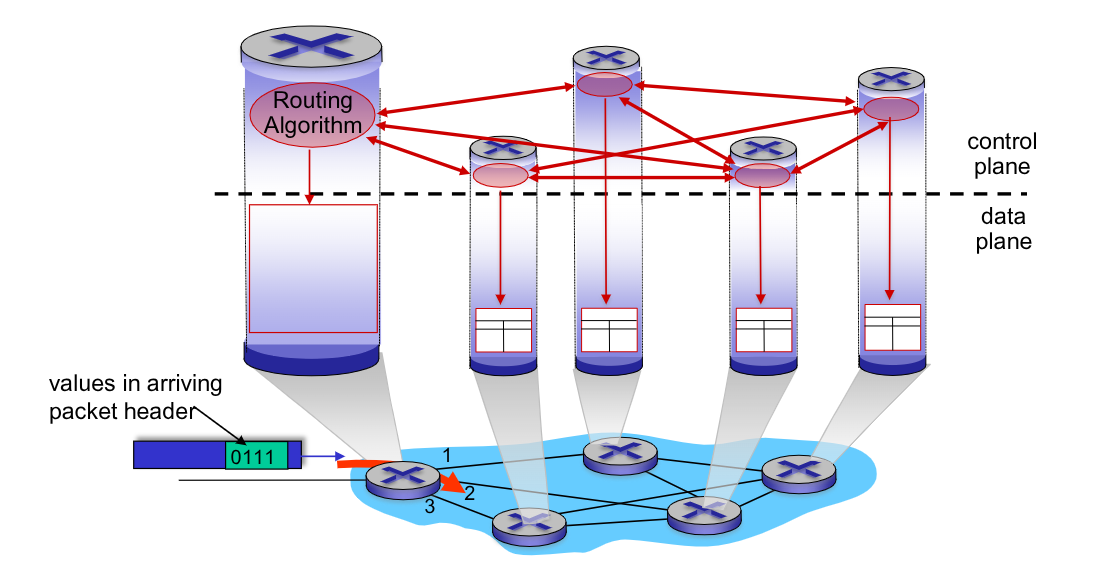
Il protocollo opera su due piani diversi.
Il primo piano è il piano dei dati, che è locale per ogni router. Questo piano determina, a partire dalla tabella di forwarding, a quale porta inoltrare il datagramam in entrata.
Il secondo è il piano di controllo, che ha una logica network-wide. Determina come il datagramma deve essere nistradato attraverso i router cos’ da percorrere “il percorso più breve”, scrivendo la tabella di forwarding.
Questo piano può creare la tabella attraverso diversi approcci. Il primo approccio è attraverso Algoritmi di routing tradizionali implementati nei singoli router, che operano atrtaverso lo scambio di informaizoni tra router adiacenti.
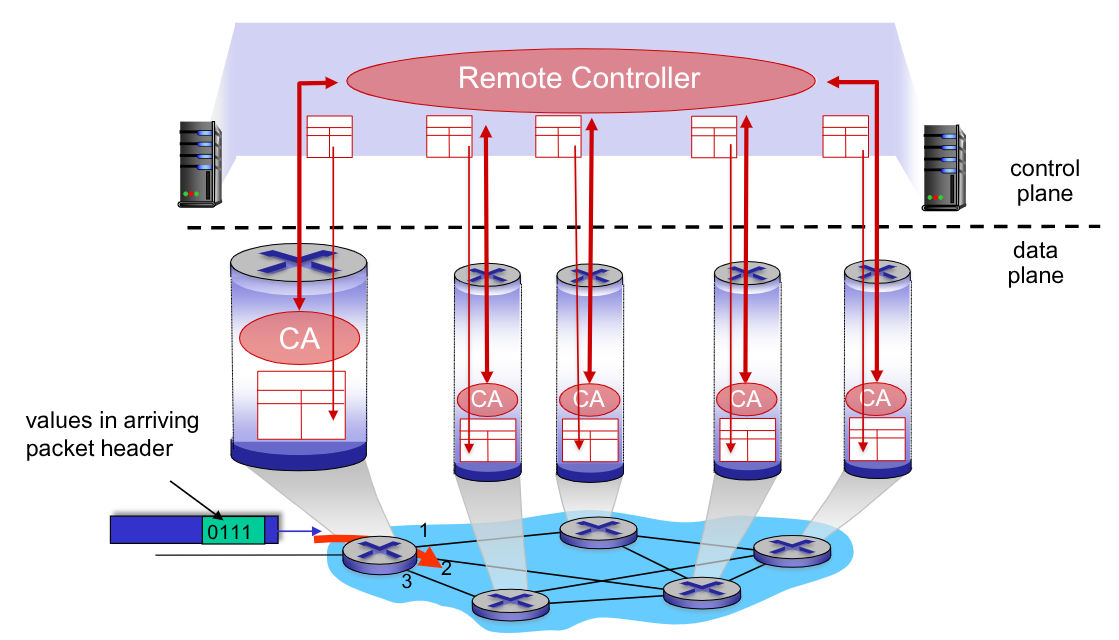
Un secondo approccio è il Networking software-defined che sono implementati il server remoti che opera nel cloud, e calcola i percorsi in maniera centralizzata.
2.1. Modello di Servizio
Il serivce model di internet è basato sul best effort. Quetso non fornisce alcuna garanzia su:
- Corretta spedizione dei datagrammi a destinazione
- Ordine di arrivo e controlli di tempo
- Banda disponibile per un flusso end-to-end
Negli anni sono stati definiti diversi service models:

Anche se può sembrare che vi siano diversi modelli migliori sulla carta rispetto al best-effort, la sua semplicità ha permesso ad Internet di essere ampiamente sviluppato e adottato. L’ampia fornitura di banda permette alle applicazioni real-time di essere “abbastanza buone” per “la maggior parte del tempo”. Questa banda è otttenuta attraverso servizi dell’application-layer distribuiti e replicati.
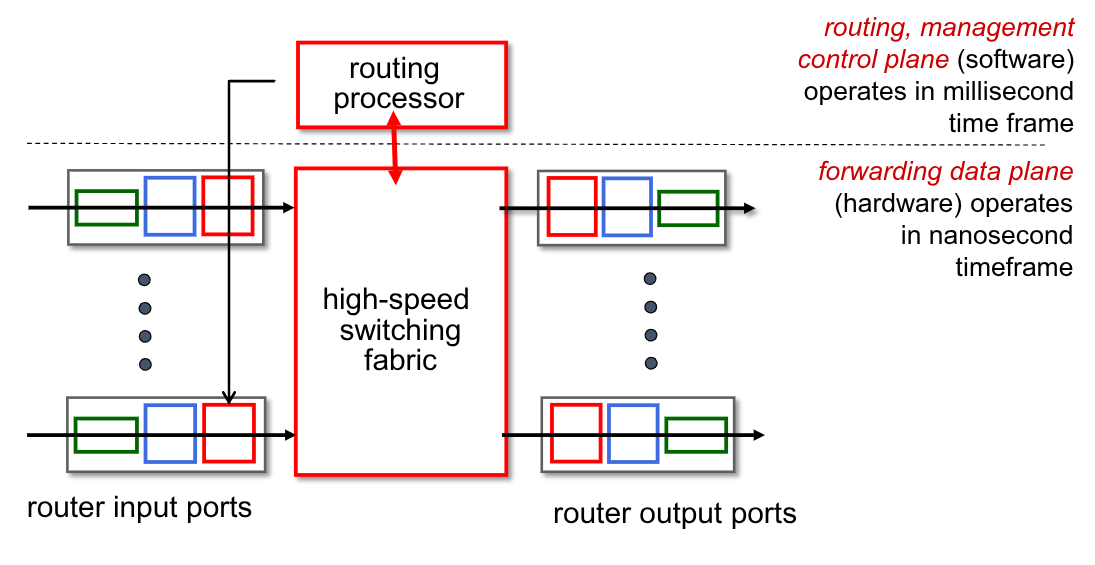
2.2. Router
Un router è un calcolatore dedicato che fa forwarding dei datagram che gli arrivano. È fornito di:
- Porte di ingresso
- Porte di uscita
- Data and Control Plane
- Meccanismi che permettono il forwarding
Questi servizi sono eseguiti su microcontrollori dedicati.
Le porte di input sono composte da 3 parti principali:
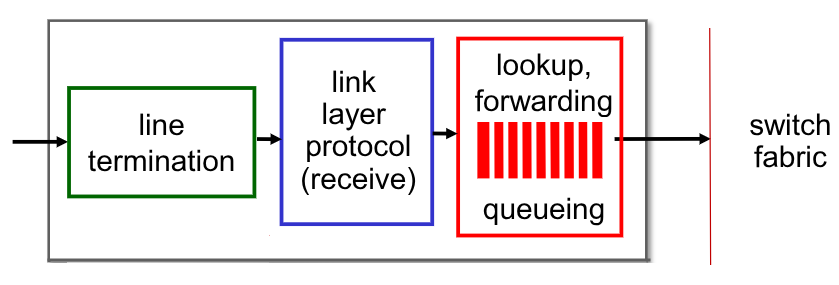
Il line termination implementa il physical layer, ovvero la ricezione fisica dei bit.
Il link layer protocol implementa, come dice il nome, il link layer.
I servizi di lookup, forwarding e queueing forniscono al circuito di commutazione (switch fabric) i pacchetti da istradare, associandoli alle informaizoni per poterlo fare correttamente.
Il servizio di lookup controlla il contenuto dei campi header per recuperare informazioni relative alla destinazion del pacchetto. Successivamente, queste informazioni vengoo confrontate dal servizio di forwarding con forwarding table, per determinare quale delle porte di uscita del router va selezionata.
Il forwarding si differenzia in:
- Destination-Based: fa un inoltro basandosi esclusivamente sull’indirizzo IP del destinatario
- Generalized: recupera diverse informazioni dall’header per stabilire il forwarding
Un esempio di forwarding table for destination-based forwarding è il seguente:

Il servizio di queueing è necessario qual’ora l’arrivo del datagramma sia più veloce dell’inoltro allo switch fabric, e si creassero delle code.
2.2.1. Circuiti di Commutazione (switching fabrics)
Permettono di trasferire un pacchetto dal link di entrata all’uscita.
Da questo circuito dipende il switching rate, ovvero la velocità con la quale i router possono trasferire pacchetti dagli input agli output.
Ipotizzando che tutti gli $N$ link di entrata abbiano un bit rate di $R$ bps, idealmente vorremo un rate di $N\cdot R$ bps. Vedremo che questo valore è impossibile a causa di overhead e inoltri multipli da diversi link di entrata verso lo stesso link di uscita, che quindi geenra concorrenza.
Vi sono diversi metodi per implementare la switching fabric alcuni più complessi, altri più semplici. Noi vedremo i circuiti basati su:
- Memoria condivisa
- Bus
- Conessioni interlacciate
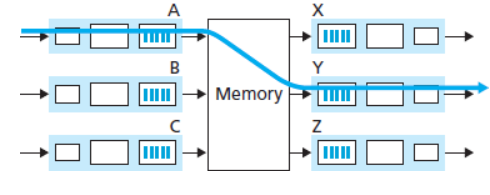
2.2.1.1. Switching via memoria
Era la metodologia utilizzata nella prima generazione di router.
In questa architettura troviamo una memoria condivisa nella quale vengono copiati dal microcontrollore i datagrammi in entrata.
Succesivamente, lo stesso microcontrollore, si occuperà di copiare il messaggio nella porta di uscita corretta.
Questo tipo di router ha un throughput tra i più bassi possibile, in quanto non solo soffre di una banda limitata, ma è rallentanto ulteriormente dalla necessità di effettuare un doppio accesso in memoria.
2.2.1.2. Switching via bus
Si basa su una specie di rete ethernet in miniatura. Tutte le porte sono collegate ad un bus comune con accessi mutualmenti esclusivi o arbitrati per l’accesso multiplo, senza alcun intervento da parte del processore di routing.
Si rende questa modalità possibile appendendo davanti all’header uno switch-internal label che permette al circuito di capire in autonomia (tramite le maschere alle porte), dove instradare il messaggio.
Il link di output si occuperà di rimuovere questa label aggiuntiva prima di inoltrare il pachetto verso il prossimo router.
Questo tipo di switching limita il throughput per via del bottleneck provocato dal singolo bus, che non permette a più link di entrata di inoltrare verso le uscite più messaggi in parallelo.
Questa tecnologia è comunque sufficientemente veloce per la maggior parte dei router di accesso, arrivando in alcuni router, come il Cisco 6500, a comunicazioni sul bus di 32Gbps.
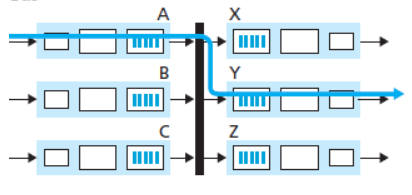
2.2.1.3. Switching via rete interconnesse
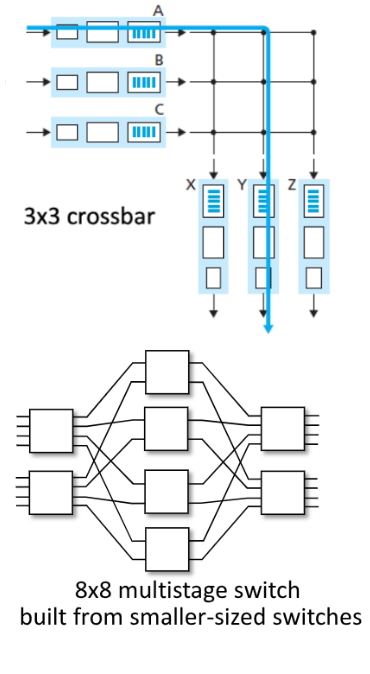
Perette di ovviare alla limitazione della banda dovuta ad un unico bus condiviso, attraverso una interconnessione di bus più complessa. Alcuni esempi di reti di interconnessione utilizzati sono i crossbar (come in figura sulla destra). Dati $N$ link di entrata e $N$ link di uscita, sono presenti $2N$ bus per il collegamento.
Ogni bus erticale interseca tutti i bus orizzontali in dei punti chiamati crosspoints, che possono essere opportunamente aperti o chiusi dal controllore del circuito, secondo una logica che fa parte del circuito stesso.
Se un pacchetto deve essere inviato dal link A verso il link Y il controllore chiudera il crosspoint di intersezione tra i due link diretti (come in figura).
Quello che possiamo notare immediatamente è che questa interconnessione permette di avere matrici di bus che possono sfruttare comunicazioni in parallelo, aumentando notevolmente il throughput.
Nell’esempio a destra possiamo notare come una comunicazione da B a X sia perfettamente possibile anche mentre quella da A a Y è in atto.
Tuttavia la crossbar non risolve problemi di concorrenza sulla porta di uscita, in quanto una comunicazione da C a Y non sarebbe possibile in parallelo a quella da A a Y.
Altre tecnologie che ovviano a questo problema sono ad esempio i multistage switch, che permettono a più pacchetti diretti sulla stessa uscita di arrivarvi senza problemi. In questi casi però è fondamentale una buona implementazione del queuing.
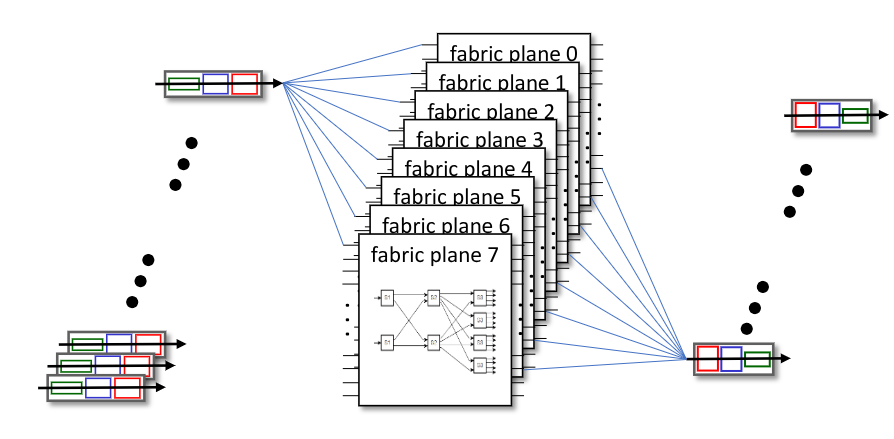
Ovviamente possiamo mettere in parallelo più fabrics così da implementare ulteriormente il throughput, come nei Cisco CRS router:
2.3. Port Queuing e Buffer Management
Se a switch fabric fosse più lenta di tutte le input port combinate, potrebbero verificarsi degli accumuli di pacchetti in coda sulle porte di ingresso.
Questo problema si chiama Head-Of-the-Line blocking HOL, ovvero quando il datagramma testa alla coda trova il suo percorso occupate e non permette agli altri pacchetti successivi (potenzialmente instradabili) di passare.
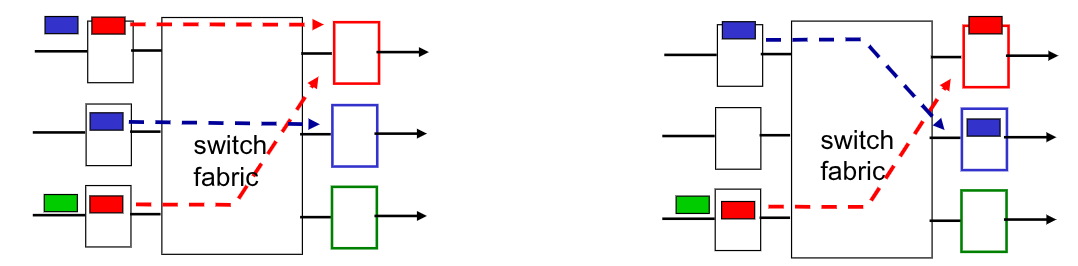
Questa logica pu avvenire anche nelle porte di uscita, nel caso in cui la switch fabric inoltri più datagram di quanti la porta di uscita riesca a gestire.
In entrambi i casi dobbiamo implementare un buffer, che però può saturarsi costringendoci a scelgiere una politica di gestione delle perdite.
Dobbiamo quindi seguire una gestione del buffer:
- Drop: scegliamo di “perdere” un pacchetto quando il buffer è pieno. Questo può essere:
- Tail Drop: rimuove i nuovi pacchetti in arrivo
- Priority Drop: rimuove i pacchetti a seconda di una priorità
- Marking: permette di inviare dei pacchetti speciali per segnalare la congestione al nodo sorgente, così da fargli abbassare il rate.
In internet si gestisce il buffer attraverso il drop.
2.4. Algoritmi di Schedulazione
Il packet scheduling permette di decidere qual’è il prossimo pacchetto da inviare attraverso il link.
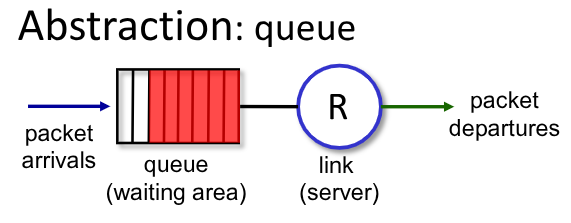
Vediamo alcuni esempi.
2.4.1. First-Come-First-Served - FCFS
È il più semplice algoritmo che possiamo pensare.
Si basa sul trasmettere i pacchetti in ordine di arrivo.
Questo algoritmo tratta tutti i pacchetti in modo uguale. Nella realtà però abbiamo applicazioni diverse, ogniuna con necessità diverse.
2.4.2. Priorità
Implementa più code a priorità differenziata, ognuna gestita con FCFS.
Si predilige la coda con priorità più alta, e inoltrando quelli nella coda a priorità minore solo se l’altra è vuota.
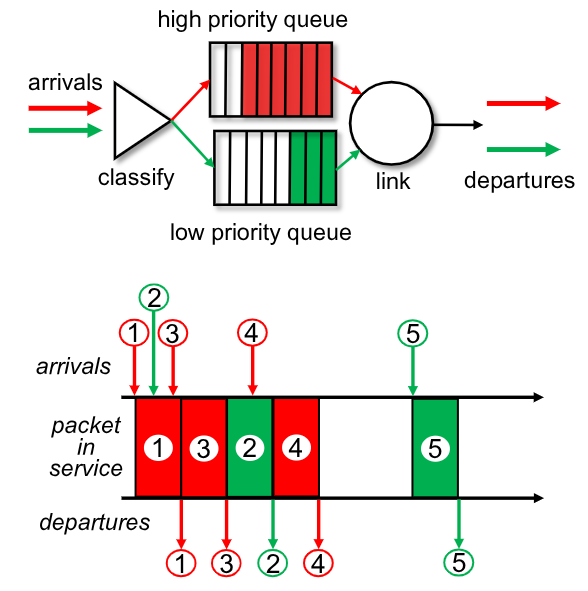
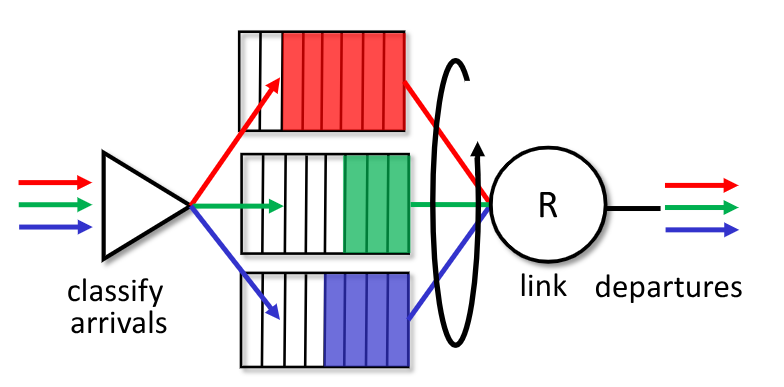
2.4.3. Round-Robin - RR
È un RR implementato su più code diverse. Invia un pacchetto alla volta da una coda diversa alla volta
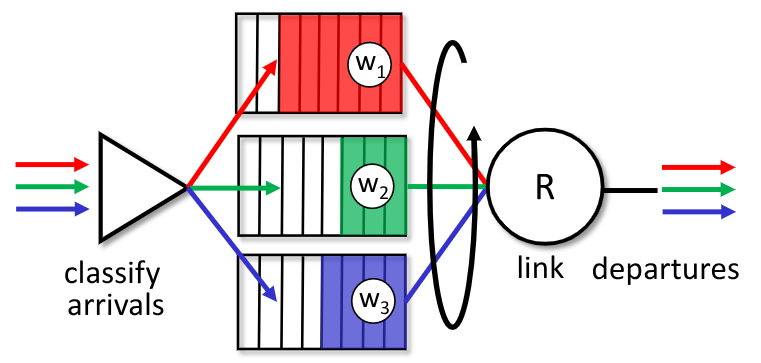
2.4.4. Weighted-Fair-Queuing - WFQ
È una generalizzazione del RR che tratta ogniuna coda attraverso un peso wi.
Ogni classe $i$ ha un peso $w_i$ e prende un tempo sul totale di $\frac{w_i}{\sum_j{w_j}}$.
Questo permette anche di fornire una garanzia di banda minima.
2.5. Network Neutrality
È un problema rilevante discusso da molti studiosi.
Affronta il problema della rete da diversi punti di vista:
- Tecnico: come un
ISPdovrebbe allocare/condividere le sue risorse? - Sociale e Economico: dovrebbe proteggere la “libertà di parola” incoraggiando “innovazione” e “competizione, trattando tutti “alla stessa maniera”? Oppure dovremmo fornire ad ogniuno “le risorse che necessita, anche se più di un altro”
- Legale: dovrebbe forzare regole e politiche?
Diversi stati hanno diversi punti di vista sulla newutralità della rete
2.6. Protocollo IP
È il protocollo di livello network utilizzato su internet.
All’interno di ogni host definisce:
- Il formato dei datagram
- Il formato di indirizzamento a livello di internet
- Le regole di instradamento
Si avvale anche dei protocolli:
ICMP(Internet Control Media Protocol), che permette di fare error reporting e router signaling.ARP: lo vedremo più avanti
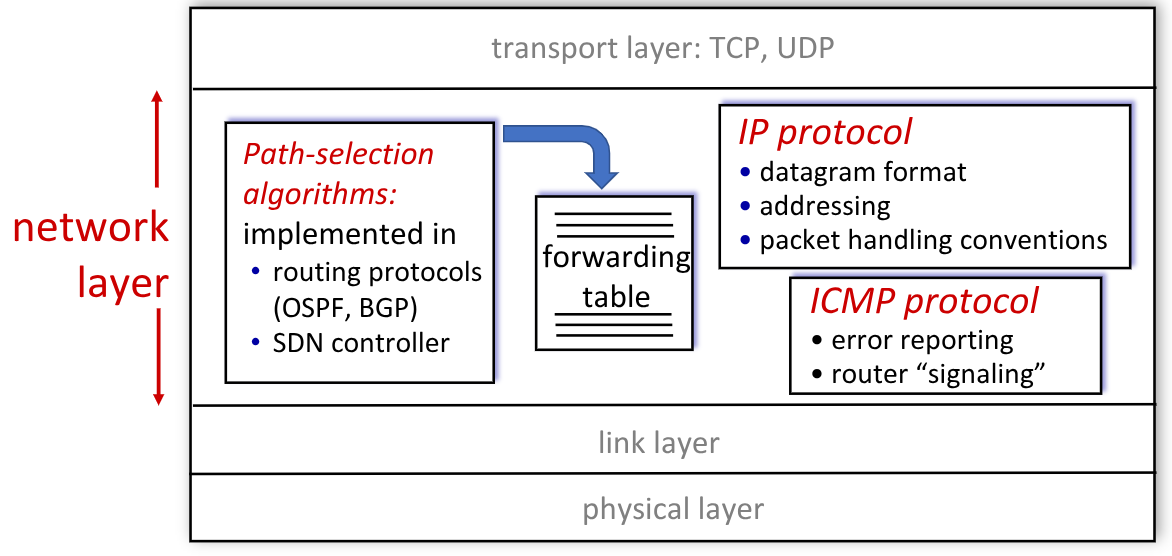
2.6.1. Formato Datagram
Il datagram del network layer è più complesso di quelli visti fin’ora, e presenta tanti campi:
- IP protocol version number (
4bit): deve essere inserita la versione4. - Header length (
4bit): indica la lunghezza dell’header inByte. Tipicamente è20 Byte, ma potrebbe essere più ampio - Type of Service (
8bit): permette di implementare diversi servizi, come livelli di servizi (priorità) attraverso i primi6bit. Il bit6e7, se implementati, servono ai router per le notifiche di congestione, anche se questo meccanismo non viene utilizzato. - Lunghezza complessiva del datagram (
16 bit): indica la lunghezza complessiva del datagram inByte. La dimensione massima è quindi di64KB. - Indentificatore (
16bit): descritto nella prossima sezione - Flags (
3bit): descritto nella prossima sezione - Fragment Offset (
13bit): descritto nella prossima sezione - Time-To-Live (
8bit): va da1a255ed è decrementato ad ogni hop dal router. Se arriva a0il router scarta il pacchetto. Serve per evitare che il datagram possa finire in cicli infiniti che occupano solamente banda. - Upper Layer (
8bit): serve a specificare se il protocollo èTCPoUDP - Header Checksum (
16bit): serve per l’error detection - Indirizzo IP Sorgente (
32bit) - Indirizzo IP Destinatario (
32bit) - Campi opzionali (
32bit): sono ad esempio timestamps, route taken in caso di routing statici (oggi non utilizzati), … - Payload: effettivi dati da inoltrare. Hanno una dimensione variabile
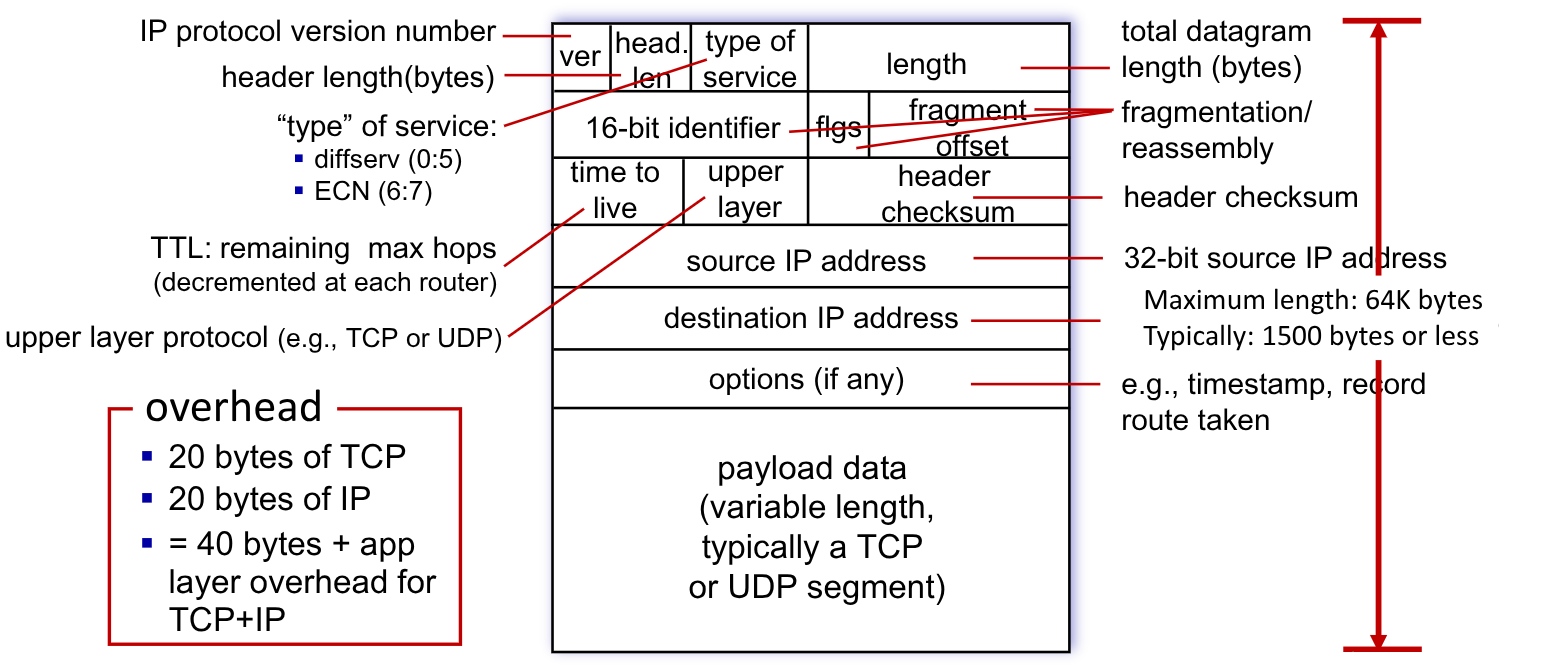
La dimensione minima dell’header del datagramma IP è di 20 Bytes, qualora non fossero presenti i campi opzionali.
Ricordando che nel caso l’header del frame TCP era anch’esso di 20 Byte, otteniamo che la dimensione minima dell’overhead considerando solo questi due livelli è di 40 Byte.
2.6.2. Frammentazione e Riassemblaggio
Nella seconda parola troviamo i campi che si occupano di gestire la frammentazione.
La frammentazione è un meccanismo necessario per risolvere un problema dei network links . Questi infatti hanno una MTU (Maximum Transfer Size) che sancisce il più grande link-level frame che sono in grado di trasferire.
Inoltre, diversi tipi di link possono avere diversi MTU.
Per poter consegnare grossi datagrammi IP, quello che si fa è frammentarli in diversi frammenti così da permetterne la trasmissione.
Chi riceve i vari frammenti però necessita di diverse informazioni per poter riassemblare correttamente i vari frammenti nel messaggio originale.
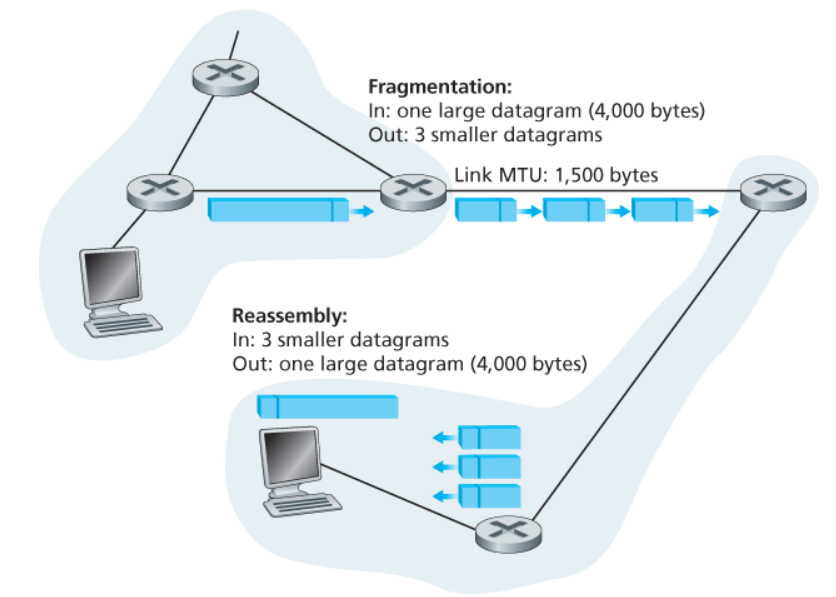
Queste informazioni sono contenute proprio nella seconda parola:
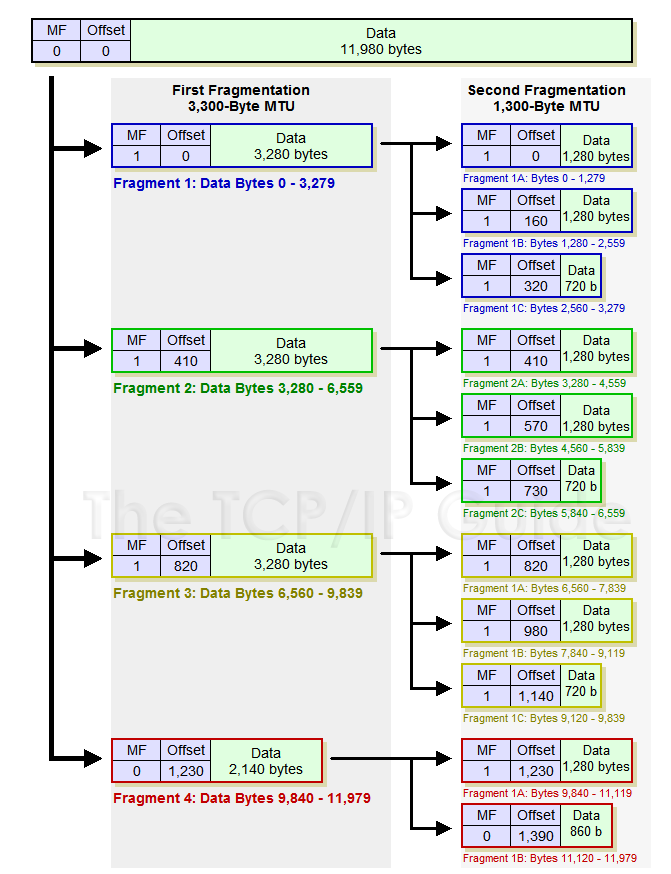
- Indentificatore (
16bit): sono16 bitche indicano univocamente il datagram originale. Rimane invariato in tutti i frammenti dello stesso datagram - Flags (
3bit): sono bit che servono a gestire la frammentazione:- Res (Null bit): non è utilizzato
- DF (Don’t Fragment): Se
1indica che il datagramma non dovrebbe essere frammentato. È principalmente utilizzato per testare laMTUdi una rete, in quanto molti protocolli lo mantengono a0. - MF (More Fragments): se
0indica che è l’ultimo frammento del messaggio,1altrimenti. Se un frammento conMF = 1viene riframmentato anche i nuovi frammenti avranno tuttiMF = 1
- Fragment Offset (
13bit): risolve il problema della sequenziazione, indicando la posizione nel messaggio originale del primo bit del frammento. Per riuscire a indicare tutte le posizioni (che possono essere espresse su16bitdal campo lunghezza), viene inserito prendendo come unità8 Byte, ovveroposizione/8.
2.6.3. IP Addressing
Abbiamo visto come gli indirizzi IPv4 sono rappresentati da una stringa di 32bit, resa leggibile per l’occhio umano tramite notazione puntata.
L’indirizzo IP, a differenza dell’indirizzo MAC che è univoco per ogni NIC e non fornisce indicazioni sulla locazione del dispositivo, è “logicamente” diviso in due parti:
- La prima indica la sottorete. I dispositivi che si trovano nella stessa sottorete hanno gli stessi bit alti
- La seconda indica l’host.
Una sottorete è così definita:
L’insieme dei nodi che possono raggiungersi fisicamente senza passare da un router. Ovvero tutti i nodi che condividono la prima parte dell’indirizzo IP
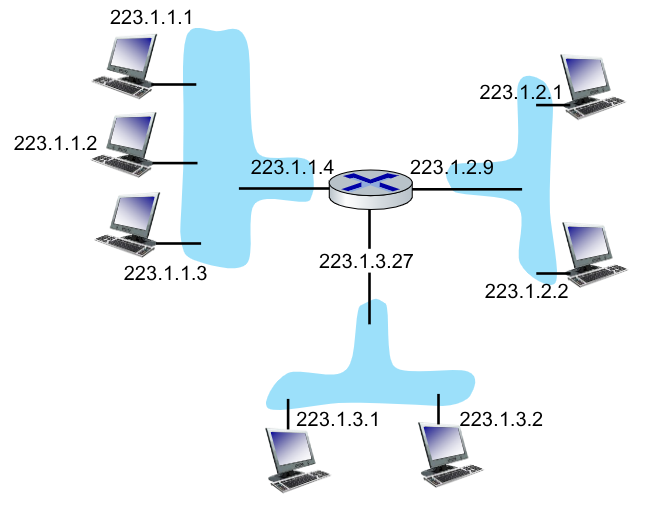
Rete 223.1.X.X composta da tre sottoreti 223.1.1.X, 223.1.2.X e 223.1.3.X
Per generare una nuova sottorete si separano le varie interfaccie dal proprio router, creando delle reti isolate, ovvero le sottoreti.
Gli indirizzi di una sottorete hanno il seguente formato a.b.c.d. L’indirizzo di una sottorete è il risultato tra l’AND logico tra:
- L’indirizzo di un nodo della sottorete
- La maschera di sottorete
Possiamo impropriamente dire che la sottorete rappresenta l’host 0.
2.6.4. Classi di indirizzi
Gli indirizzi delle sottoreti sono caratterizzate in classi. Queste classi si differenziano sulla suddvisione dei bit tra bit di sottorete e bit di host:
| Classe | Bit di sottorete | Bit di Host | Massimo numero di host per una rete |
|---|---|---|---|
A |
8 |
24 |
$2^24 - 3 \approx 16M$ |
B |
16 |
16 |
$2^16 - 3 \approx 64K$ |
C |
24 |
8 |
$2^8 - 3 = 253$ |
Vi sono poi altre due classi:
D: riservati al multicastE: riservati per scopi futuri
Se un organizzazione avesse necessità di avere 15 host, sprecherebbe più di 200 indirizzi utilizzando una rete di classe C.
Allo stesso modo, se ad un certo punto diventasse abbastanza rande da avere più di 253 host, dovrà ottenere una nuova
Durante l’espansione di internet venne studiato che, continuando ad assengare gli indirizzi attraverso le classi, gli indirizzi IP sarebbero termianti entro la metà degli anni ‘80.
Questa “crisi” generò diverse idee:
IPv6: ampliare il numero dibitNAT: si vedrà meglio in un capitolo successivoCIDR
2.6.4.1. Classless InterDomanin Routing - CIDR
Pronunciato cider, permette di assegnare gli indirizzi nel modo più efficiente possibile, assegnando ad ogni subnet solamente il numero di host bit ad essa necessari.
Segue il formato a.b.c.d/x dove x indica il numero di bit dedicati agli host.
In questa conformazione è possibile avere un indirizzo come 145.23.4.6/23.
La maschera di rete viene quindi costruita così: $(2^32 - 1) « x$.
2.6.5. Ottenere un indirizzo host - DHCP
Vediamo adesso come si fa un host ad ottenere un indirizzo IP.
Un host può ottenere un indirizzo IP in due modi:
- Recuperandolo da un file di configurazione scritto dall’amministratore di sistema. In
UNIXquesto file si trova tin/etc/rc.config. Questa assegnazione è hard-coded e permanente. DHCP(Dynamic Host Configuration Protocol): fornisce dinamicamente gli indirizziIPottenendoli da un server, per dei tempi
Il primo metodo ha diversi problemi, uno tra i principali è quello che difficilmente un dispositivo è costantemente connesso in rete. Quindi per tutto il tempo per il quale non è collegato, abbiamo un indirizzo “sprecato” e inutilizzato.
La soluzione utilizzata da internet è quindi quella del DHCP.
Il DHCP ha anch’egli alcuni problemi da risolvere:
- Deve poter rinnovare l’indirizzo assegnato ad un host qualora continui ad utilizzarlo oltre il tempo limite che gli si era assegnato
- Deve permette il riutilizzo degli indirizzi che non sono più utilizzati
- Deve fornire la possibilità ai dispositivi di unirsi/lasciare la rete
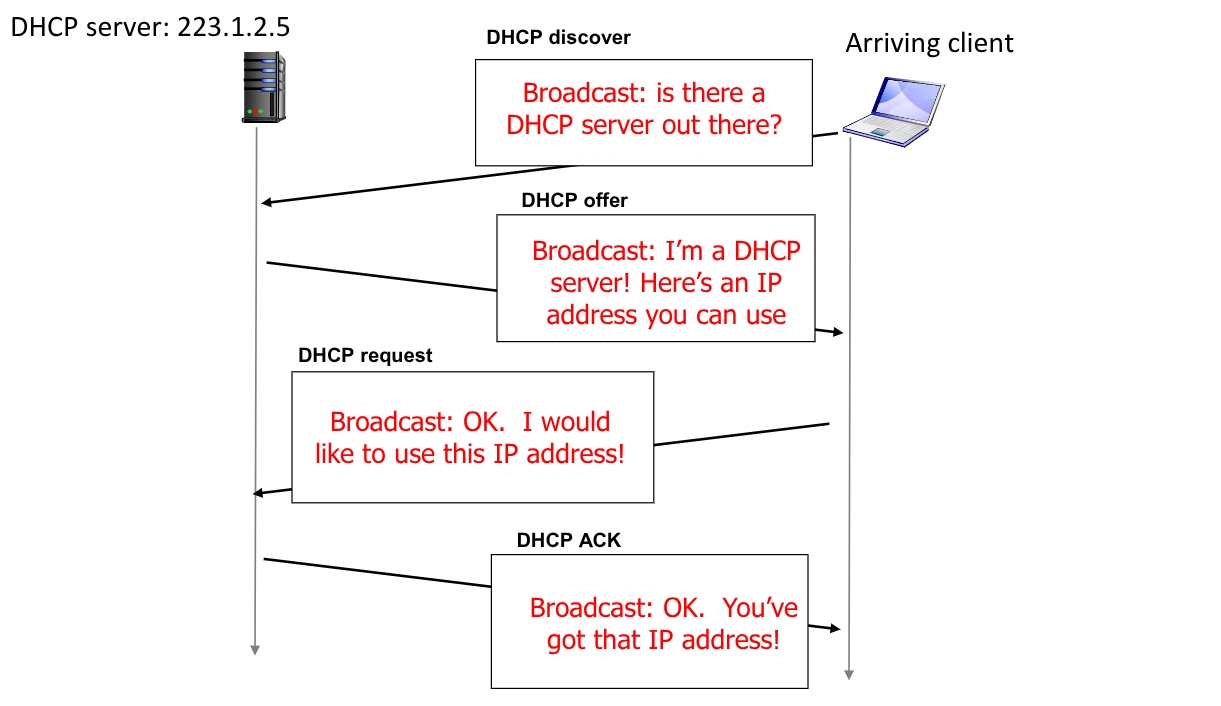
La comunicazione di un nuovo dispositivo si effettua su quattro fasi. Per ogni fase vediamo anche un mockup di messaggio, ridotto solamente ai campi utili per il nostro studio.
La prima fase è chiamata DHCP discover: l’host invia un messaggio in broadcast dove chiede se è presente un server DHCP all’interno della rete.
src: 0.0.0.0, 68
dest.: 255.255.255.255, 67
yiaddr: 0.0.0.0
transaction ID: 654
La seconda fase si chiama DHCP offer: il server risponde in broadcast fornendo un indirizzo IP da poter utilizzare.
src: 223.1.2.5, 67
dest.: 255.255.255.255, 68
yiaddr: 223.1.2.4
transaction ID: 654
lifetime: 3600 secs
La terza fase è chiamata DHCP request: l’host, sempre in broadcast, risponde facendo la vera e propria richiesta per l’indirzzo IP da utilizzare, diminuendo eventualmente il lifetime.
La comunicazione continua ad avvenire in broadcast per due motivi:
- Il protocollo è stato definito così, quindi funziona così
- Potrebbero esserci più server
DHCPche collaborano all’interno di una rete. Mandando il broadcast la richiesta aumenta la probabilità di trovarne uno libero
src: 0.0.0.0, 68
dest.: 255.255.255.255, 67
yiaddr: 223.1.2.4
transaction ID: 655
lifetime: 3600 secs
La quarta e ultima fase è la DCHP ACK: il server invia un ultimo messaggio, sempre in broadcast riconfermando l’assegnazione dell’indirizzo
src: 223.1.2.5, 67
dest.: 255.255.255.255, 68
yiaddr: 223.1.2.4
transaction ID: 655
lifetime: 3600 secs
Da questo momento in poi il nuovo host comunicherà utilizzando il nuovo indirizzo IP assegnatoli.
Le prime due fasi possono non avvenire qual’ora un host avesse già fatto parte precedentemente alla subnet.
In questo caso procede direttamente con il terzo step, allegando l’indirizzo IP precedentemente assegnatoli.
Se l’indirizzo fosse libero il DHCP confermerà il vecchio indirizzo, se invece fosse occupato risponderà con una nuova DHCP offer
Oltre all’indirizzo in realtà il server DHCP fornisce altre informazioni, quali:
- Indirizzo dell’access router della rete
- Nome e indirizzo
IPdel serverDNS - Maschera di rete
2.6.6. Ottenere un indirizzo di rete
Per quanto riguarda gli indirizzi di rete, questi vengono forniti dagli ISP.
Gli ISP hanno a disposizione blocchi di indirizzi, che porzionano tra le varie reti che gestiscono,
Iporizziamo di avere un ISP che ha il blocco 200.23.16.0/20.
Se dovesse dividere gli indirizzi tra 8 organizzazioni identiche, potrebbe fornire loro 9bit per gli host (circa 500 host possibili) dividendo il proprio blocco così:
200.23.16.0/23: parto dal blocco di partenza e fornisco200.23.18.0/23200.23.20.0/23- ….
200.23.30.0/23
‘utilizzo degli indirizzi CIDR permette anche di diminuire le dimensioni delle forwarding table. Infatti è possibile inoltrare i messaggi diretti ad un host prima al suo ISP, che ha un blocco ampio.
In questo modo non è più necessario specificare tutti gli indirizzi delle varie reti nelle tabelle dei core router, ma è sufficiente metterne solo uno.
Successivamente sarà l’host stesso a ridirezionare il messaggio nelle varie sottoreti che gestisce.
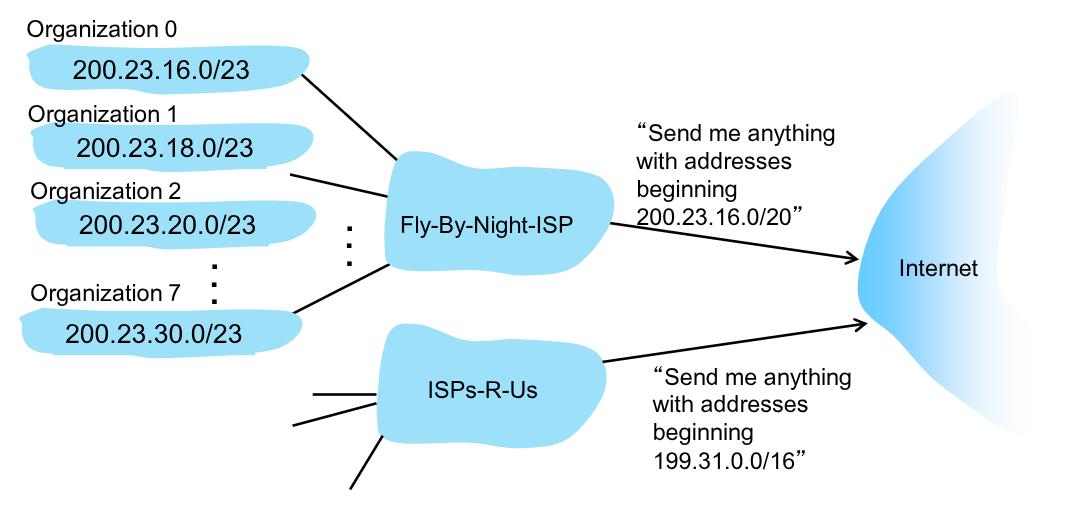
Nel caso in cui un organizzazione cambiasse il proprio ISP ma volesse mantenere il proprio indirizzo IP sarà quindi sufficiente inserire nella tabella di forwarding del nuovo ISP la condizione che sia presente proprio l’indirizzo specifico dell’organizzazione.
Affinché un ISP possa ottenere un blocco di indirizzi deve chiedere a sua volta ad un altro ISP.
L’ISP gerarchicamente di riferimento è la ICANN (INternet Corporation for Assigned Names and Numbers) che permette di allocare gli indirizzi IP attraverso 5 registri regionali RR.
SI occupa anche di gestire le zone di root DNS e della gestione dei vari TLD.
2.7. Scarsità di indirizzi
Quando venne introdotto lo standard degli indirizzi IP a 32bit ($2^32 \approx 4G$ indirizzi) si pensava che fosse più che sufficiente per tutti i dispositivi.
La storia però ha dimostrato il contrario, infatti ICANN ha assegnato l’ultimo blocco di indirizzi IPv4 ai RR nel 2011
È stato quindi necessario trovare dei metodi per poter ampliare il numero di indirizzi IP disponibili.
Sono state proposte diverse soluzioni, noi vedremo quelle che hanno preso piede e che sono attualmente utilizzate:
NATIPv6
2.7.1. Network Address Translation - NAT
Il NAT permette di far condividere, dal punto di vista del mondo esterno, a tutti i dispositivi in una stessa rete locale un unico indirizzo IPv4.
Prima di poter spiegare come funzioni il NAT dobbiamo dire che esistono alcuni indirizzi IP particolari che sonon dedicati a comunicazioni particolari:
- Indirizzi speciali pubblici: possono essere utilizzati per ocmunicare sulla internet pubblica
0.0.0.0: indirizzo utilizzato da nuovi host nella rete che non hanno ancora indirizzo255.255.255.255o0..01..1(parte rete settata): indirizzo di broadcast
- Indirizzi speciali privati: possono essere utilizzati per creare delle interreti private, non collegate alla rete pubblica
10.0.0.0/8172.16.0.0/12- `192.168.0.0/16
Il NAT permette di sfruttare questi indirizzi privati per aumentare il numero di indirizzi IPv4 disponibili.
All’interno delle reti che utilizzano NAT i dispositivi credono di essere gli unici nel mondo ad utilizzare quegli indirizzi privati.
Nell’esempio sulla destra possiamo vedere che i dispositivi nella rete credono di essere nella rete 10.0.0.0/24.
Il router di uscita avrà quindi:
- Un indirizzo privato: con la quale più comunicare con gli host interni
- Un indirizzo pubblico: con il quale può comunicare con l’esterno
Il problema di questo approccio è che un host interno alla rete privata non può per definizione comunicare con l’esterno.
Quello che permette di fare il NAT è di far comunicare con l’esterno gli host, facendo finta che sia il router a fare le richieste. I NAT-enabled router sono infatti visti dalla rete esterna come se fosse un host.
Il problema di questo approccio è che se l’host 10.0.0.1, 3345 invia una richiesta all’esterno, il router la inoltra con indirizzo 138.76.29.7, 5001. Il webserver risponderà quindi a 138.76.29.7, 5001 e non all’host che ha effettuato la richiesta.
È quindi necessario trovare un modo per il router di capire come inoltrare correttamente il messaggio ricevuto all’interno della rete privata.
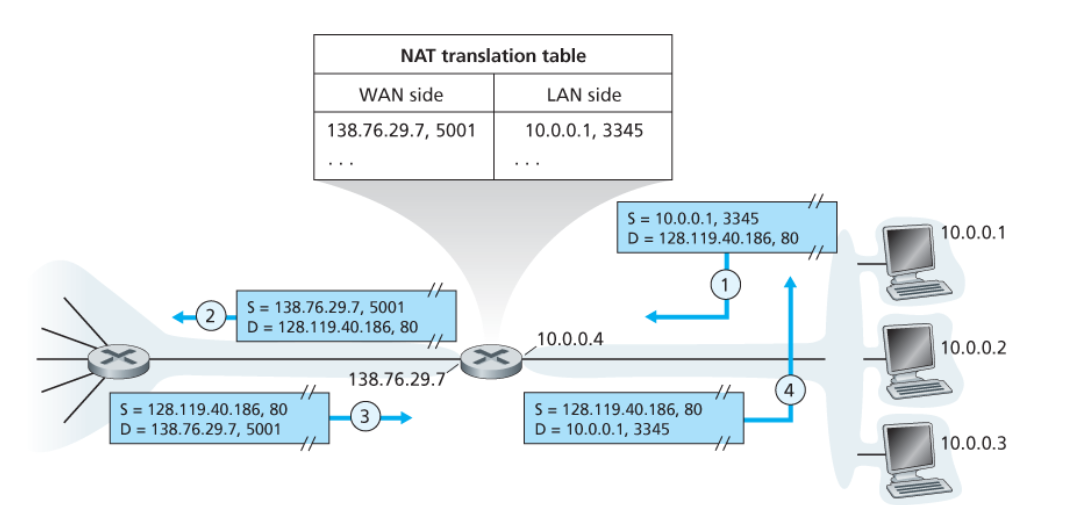
Per fare ciò il NAT utilizza una NAT translation table composto da 4 colonne:
Indirizzo Pubblico: uguale per tutte le righePorta Pubblica: diversa per ogni rigaIndirizzo Privato originariaPorta Privata originaria
Quando il router riceve una richiesta da 10.0.0.1, 3345, e decide di inoltrarla come 138.76.29.7, 5001 inserirà il seguente record:
138.76.29.7 |
5001 |
10.0.0.1 |
3345 |
Questa traduzione permette di rendere routable i mesasggi da e verso la rete, anche se si hanno indirizzi privati.
Il servizio del NAT è stato tuttavia criticato per diversi motivi:
- Viola la stratificazione perfetta: pur essendo un servizio di livello 3 accede ad informazioni di livello 4 (transportation), ovvero il numero di porta
- È una soluzione di “corto respire”: dato che è presente una soluzione a lungo tempo, ovvero
IPv6 - Viola il principio dell’end-to-end argument: le informazioni dovrebbero essere viste solo dal richiedente e dal destinatario, e non dovrebbero essere manipolate da terzi
Pone inoltre un problema nelle comunicazioni a server protetti da NAT.
In questi casi non è possibile accedere direttamente al server, solo al router che lo “protegge”.
È quindi necessario inizalizzare in maniera preventiva la NAT translation table dedicando una o più porte alle comunicazioni con il server.
2.7.2. IPv6
È la verisone sucessiva a IPv4.
Si chiama v6 perché la v5 esisteva già ma non aveva avuto successo.
È stato creato perché si è scoperto che lo spazio di indirizzi della versione quattro non era sufficientemente grande.
Risolve anche altre esigenze:
- Aumenta la velocità di processing e forwarding, fissando la lunghezza degil header a
40 Byte, evitando al router di consultare il campo header-lenght per capire quanto è lungo l’header - Permette di differenziare meglio i “flussi di dati” diversi (comunicazione di dati, audio, video, …)
Un datagram IPv6 segue quindi il seguente formato:
- Version (
4bit): contiene il valore6 - Traddic class (
8bit): come il campoTOSè utilizzato pe rdare priorità a certi datagrammi all’interno di un “flusso” rispetto ad un altro - Flow Label (
20bit): identifica il flusso al quale il datagram appartiene - Payload Length (
16bit): è considerato ununsigned integere indica la dimensione del payload - Next Header (
8bit): identifica quale protocollo utilizzano i dati nel payload (TCP,UDP, …) - Hop Limit (
8bit): equivalente alTTLe indica il numero massimo di hop del datagramma prima di venire scartato - Indirizzio sorgente (
128bit) - Indirizzio destinatario (
128bit)
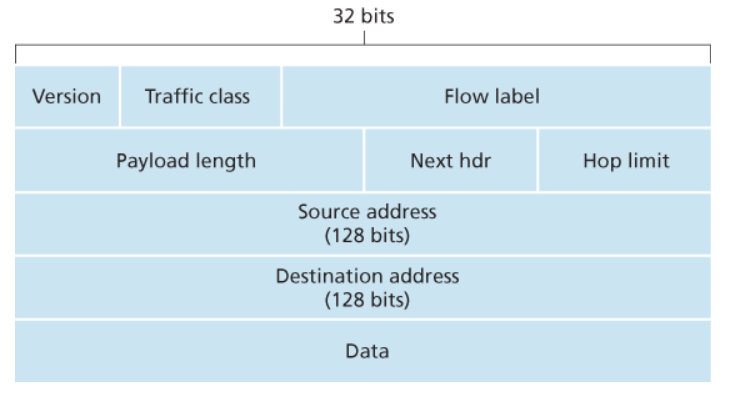
Possimao notare come manchino diversi campi all’interno degli header IPv6:
- Informazioni relative alla frammentazione/riassemblaggio: per ottimizzare i tempi di elaborazione del messaggio. Quello che accade se un router non riesce a instradare il datagram poiché troppo grande lo droppa inviando al sender un messaggio di notifica
ICMP“Packet Too Big” . Il sender si occuperà di reinviare il messaggio in datagram più piccoli. - Informazioni sul checksum: per ottiimzzare i tempi di elaborazione del messaggio. Banalmente, cambiare il
TTLad ogni passo implica anche il ricalcolare ilCRC. - Opzioni aggiuntive: erano già poco utilizzate negli indirizzi
IPv4e si è deciso di rimuoverli poiché anche presenti negli header del livello transportation
La transizione da IPv4 a IPv6 non è avvenuta in un unca notte, e ancora oggi, dopo 25 anni, siamo in transizione.
Per permettere tuttavia ai “vecchi” router IPv4 di comunicare con i nuovi router IPv6 sono state utilizzate diverse tecniche.
La prima tecnica è quella del Tunneling. I datgrammi IPv6 vengono trasportati come datagram IPv4 (pacchetto nel pacchetto).
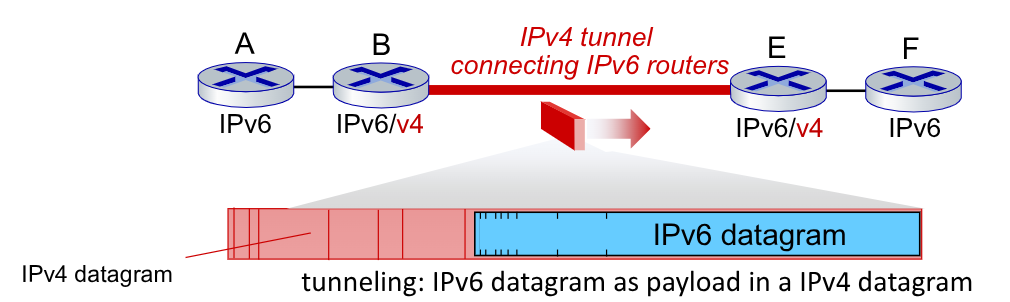
Per questa soluzione è necessario che ci siano dei router specifici che possono comunicare sia con IPv4 che IPv6.
L’altra opzione, è quella di dotare tutti i router IPv6 anche delle funzionalità IPv4. Il router sceglierà il protocollo di inoltro a seconda del tipo di messaggio che gli viene inoltrato.
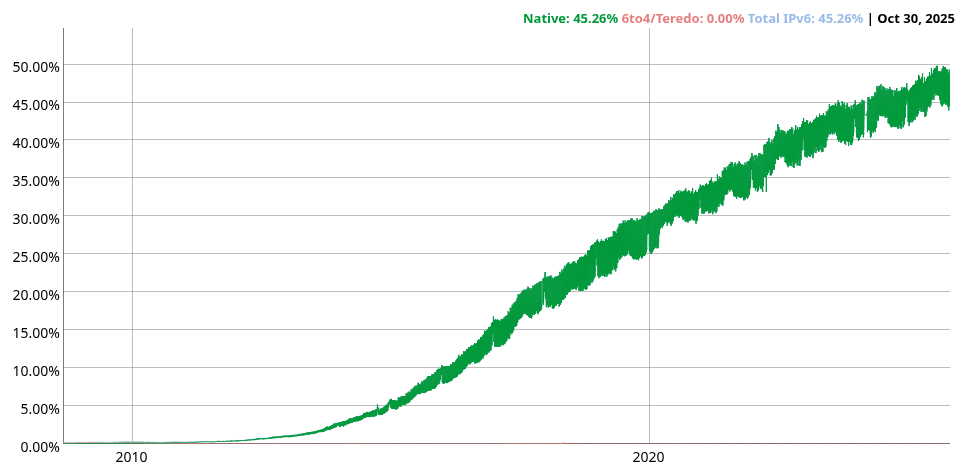
Ogni anno Google effettua un indagine per stimare gli acessi ai propri servizi in IPv4 o IPv6, consultabile a questo link.
Al 30 ottobre 2025 poco più del $45\%$ degli accessi ai servizi google è effettuato in IPv6.
Regionalmente la situazione è molto differenziata:
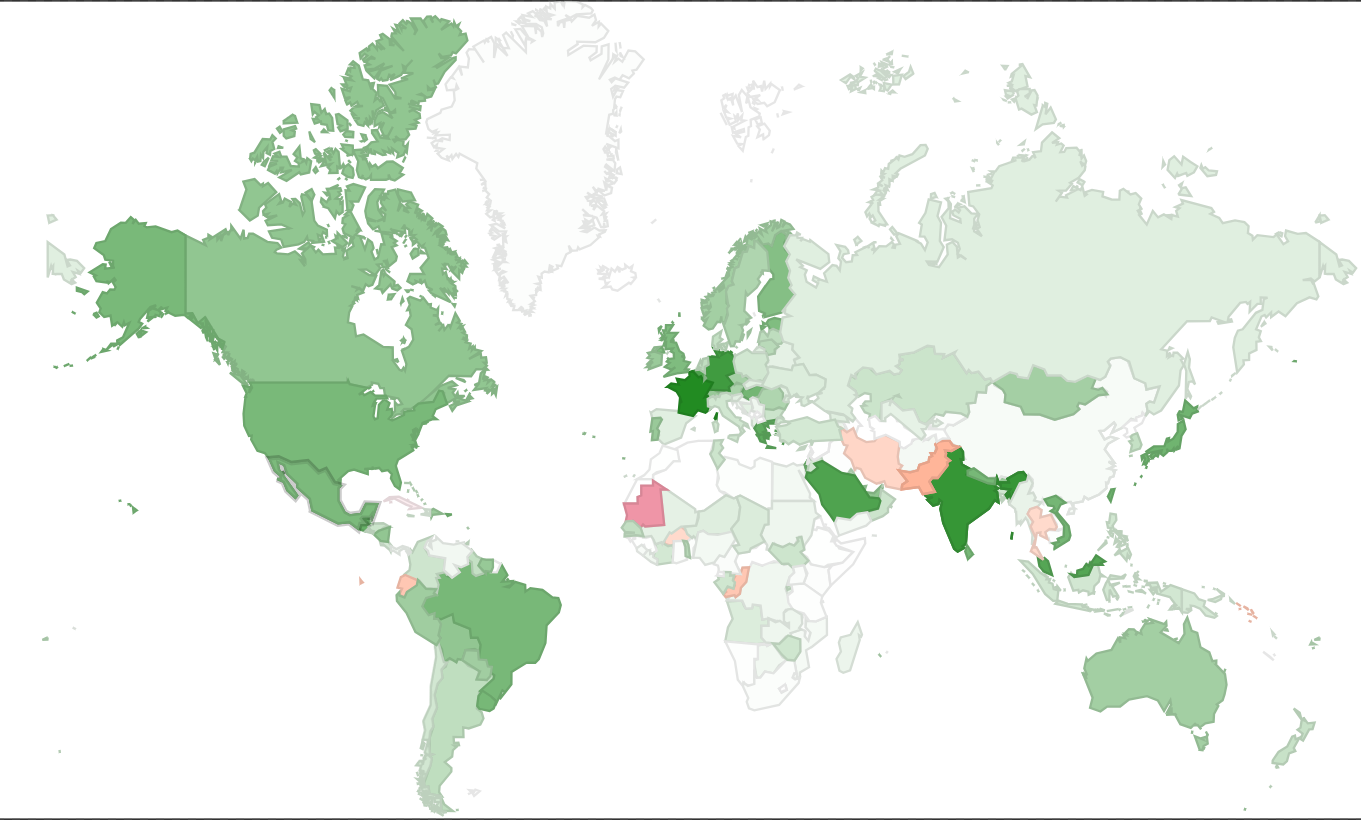
Dallo studio si evince che l’Italia è tra le ultime in classifica, con solo un adozione del circa $18.17\%$. A confronto la Francia, prima al mondo, è all’$86.7\%$ seguita dall’India al $78.73\%$, e dalla Germania al $75.09\%$. Gli Stati Uniti hanno un utilizzo al $52.47\%$.
Un’indagine NIST dice che solo $\frac{1}{3}$ delle reti governative statunitensi sono capaci di comunicare tramite reti IPv6.
2.8. Address Resolution Protocol - ARP
Fin’ora abbiamo dato per scontato che un dispositivo che deve comunicare con un altro ne conosca tutti i dettagli.
Tuttavia è molto più probabile che un host A conosca sì l’indirizzo IP di un altro host B, ma che non ne conosca il MAC.
Il protocollo ARP permette di determinare l’indirizzo MAC di un altro host conoscendone solamente l’indirizzo IP.
Per fare ciò ogni nodo IP (router e host) possiedono una ARP table.
La tabella ARP permette di mappare gli indirizzi MAC e gli indirizzi IP in una struttura < IP_address, MAC_address, TTL >. Il TTL, tipicamente 20 minuti, indica il tempo oltre il quale rimuovere un entrata dalla tabella.
Nel caso di reti locali, qual’ora non esista ancora l’entrata nella ARP table, il mittente A invia un ARP query packet in broadcast, contenente l’indirizzo IP di B.
Il dispositivo B che riceve il pacchetto, risponde con il proprio indirizzo MAC direttamente ad A.
Una cache interna ad A salverà la nuova entrata nella tabella che poi comincierà a trasmettere.
Questa soluzione è plug-and-play, e non necessita di interventi terzi.
Nel caso di reti distribuite la situazioen è un po’ più complessa.
A creerà un datagramma IP con mittente A e destinazione B. Utilizzando il protocollo ARP otterrà l’indirizzo MAC del router di accesso R.
A invierà quindi il messaggio che conterrà:
- Indirizzo
IPdiB - Indirizzo
MACdiR
Quando R otterrà il pacchetto da inoltrare, farà lui una richiesta ARP sulla rete successiva a partire dall’indirizzo IP di B. Procederà quindi a modificare il contenuto dell’indirizzo MAC di destinazione con la nuova corrispondenza e inoltrerà il messaggio.
Questo accade finché il pacchetto non raggiunge l’ultima rete, dalla quale, tramite richiesta ARP otterrà l’effettivo MAC di B. Il router finale inoltrerà quindi correttamente il messaggio.
2.9. Protocollo ICMP
È utilizzato dagli host e dai router per counicare informazioni di livello network, ad esempio errori (ad esempio unreachable host) oppure inviare messaggi di echo request o echo reply (usati ad esempio dal comando ping)
Funzionalmente il protocollo ICMP sta sopra il protocollo IP, poiché i messaggi ICMP vengono incapsulati dentro datagrammi IP.
Un messaggio ICMP contiene:
- Tipo del messaggio
- Codice del messaggio
- Header e
8 Bytedel messaggioIPche ha causato la notifica
Alcuni esempi di tipologie di messaggi
| Type | Code | description |
|---|---|---|
0 |
0 |
echo reply (ping) |
3 |
0 |
dest. network unreachable |
3 |
1 |
dest host unreachable |
3 |
2 |
dest protocol unreachable |
3 |
3 |
dest port unreachable |
3 |
6 |
dest network unknown |
3 |
7 |
dest host unknown |
4 |
0 |
source quench (not used) |
8 |
0 |
echo request (ping) |
9 |
0 |
route advertisement |
10 |
0 |
router discovery |
11 |
0 |
TTL expired |
12 |
0 |
bad IP header |
2.10. Generalized Forwarding
Inizialmente si utilizzava esclusivamente il destination based forwarding, dove la scelta di instradamento avveniva ad ogni router basandosi solo sull’indirizzo finale del pacchetto.
Negli ultimi anni è stato introdotto un nuovo metodo più generale per effettuare instradamento, detto appunto genralized forwarding.
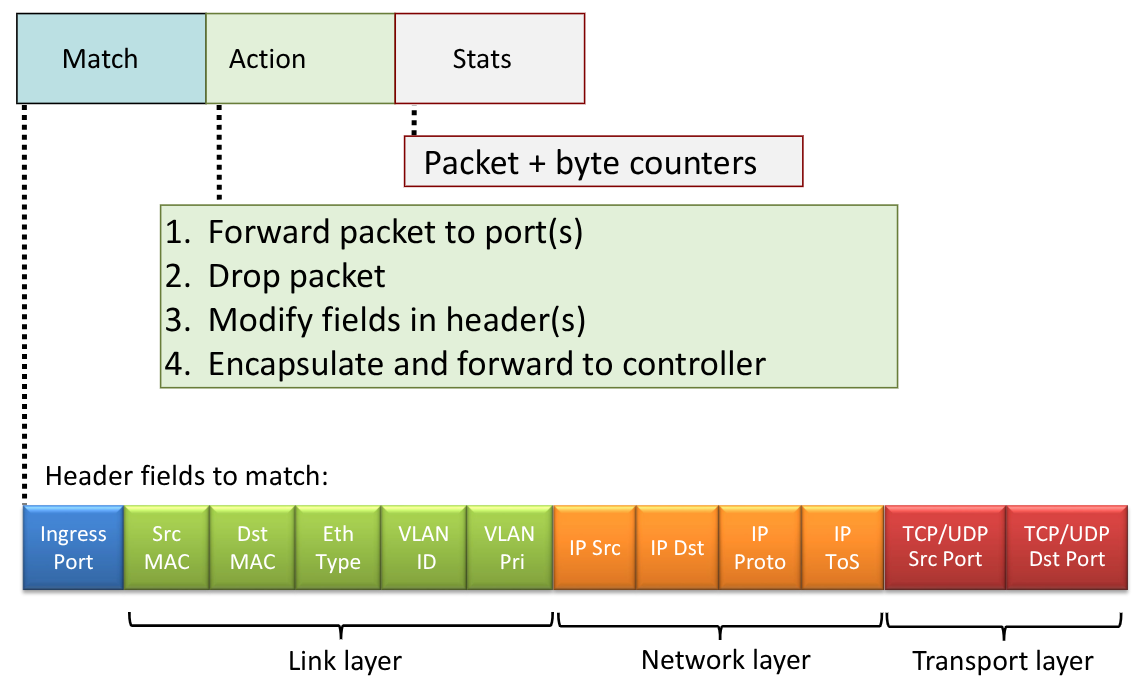
Si basa sempre sul meccanismo match-plus-action che utilizzava il destination based, ma questa volta, invece di basarsi esclusivamente sull’indirizzo IP della destinazione, si valutano più informazioni contenute nell’header.
Inoltre inserisce la possibilità di effettuare altre azioni oltre all’inoltro, quali la copia, la modifica, il drop o il salvataggio di un log.
Per poter utilizzare questa nuova metodologia dobbiamo ampliare la tabella di forwarding, inservendovi tutte le altre informazioni necessarie per prendere le decisioni.
La tabella cambia il nome in tabella di flusso, dove un flusso viene definito dai valori nei diversi campi dell’header.
I record hanno ora struttura più complessa:
- match: pattern di riferimento
- actions: per un singolo match si possono avere più azioni (drop, forward, modify, send to controller)
- priority: permette di togliere l’ambiguità tra pattern che si sovrappongono
- counters: indica il numero di bytes e il numero di pacchetti
Un esempio:
| match | action | Descrizione |
|---|---|---|
src: *.*.*.*, dest=3.4.*.* |
forward(2) |
Comportamento simile al precedente |
src: 1.2.*.*, dest=*.*.*.* |
drop |
Implementa un gateway |
src: 10.1.2.3, dest=*.*.*.* |
send to controller |
permette di fare filtri per determinati indirizzi |
Un protocollo che sfrutta questo approccio geenralizzato è OpenFlow:
Il protocollo OpenFlow è molto flessibile, e permette di unificare diversi tipi di servizi diversi attraverso la stessa astrazione:
| Servizio | match | action |
|---|---|---|
Router |
prefisso IP di destinazione più lungo |
fai il forwarding su un link |
Switch |
indirizzo MAC di destinazione |
forwarding su una o più porte (flood) |
Firewall |
indirizzi IP e numero di porta TCP/UDP |
permettilo o bloccalo |
NAT |
indirizzo IP e porta |
modifica l’indirizzo e la porta |
2.11. Middlebox
Sono i dispositivi che si trovano nel network core, codì definiti:
Una middlebox è una qualunque scatola che esegue funzioni diverse da quelle standard di un normale router IP o sul percorso tra un host sorgente e un host destinatario
Ad esempio, il NAT, la cache o il firewall sono delle middlebox. Altri esempi di middlebox sono i load balancers, gli ids (controlla il pacchetto e i successivi per ispezionarli e filtrare pacchetti potenzialmente pericolosi) e altri più application specific..
Inizialmente le middlebox erano soluzioni proprietarie chiuse su certi tipi di reti.
Nel tempo ci siamo spostati verso un “whitebox” hardware programmabili attraverso API pubbliche.
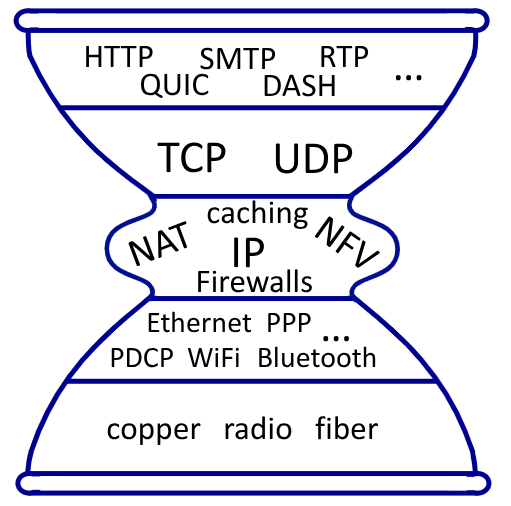
3. La clessidra di internet
L’immagine sulla destra rappresenta internet attraverso i protocolli e le soluzioni ai problemi di ogni livello..
Possiamo notare come il livello network rappresenti il “restingimento” di questa clessidra, attraverso l’unico protocollo IP che deve essere implementato da tutti i miliardi dei dispositivi connessi ad internet.
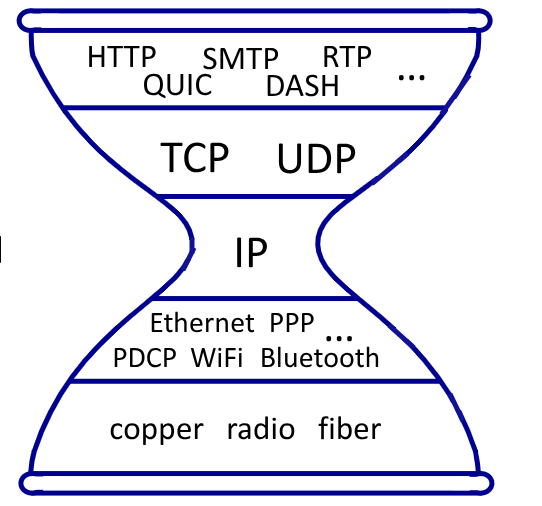
Attraverso l’introduzione delle varie middlebox oggi abbiamo ampliato il restingimento nel livello network: