1. Indice
- 1. Indice
- 2. Principi di base delle applicazioni
- 3. Applicazioni client-server
- 4. Applicazioni Peer-To-Peer (P2P)
- 5. Applicazioni di comunicazione in tempo reale
2. Principi di base delle applicazioni
Nel mondo di oggi esistono milioni di milioni di applicazioni.
Per quanto queste applicazioni si occupino di campi completamente diversi, tutte seguono tutta una serie di regole e protocolli comuni.
Le applicazioni girano solo sugli host, e va sottolineato che per avere un app distribuita è necessario che ci siano almeno due host che comunicano utilizzando la rete. I dispositivi del Network Core non realizzano i livelli di trasporto e applicazione.
Le applicazioni possono essere strutturate secondo due modelli fondamentali:
2.1. Client-Server
In questo modello, storicamente più il primo, si hanno due interpreti:
- client: richiede un servizio (browser)
- server: fornisce un servizio (web-server)
Quello che è importante sottolineare è che i due ruoli sono nettamente distinti. Da questo ne discendono diverse conseguenze.
| Server | Client |
|---|---|
Deve essere noto come raggiungere il servizio in un indirizzo IP permanente |
Deve essere in grado di comunicare con il server |
| Deve essere sempre disponibile su una porta nota | Potrebbe essere connesso non continuamente |
| Deve essere sempre disponibile e ricco di risorse | Può avere indirizzi IP dinamici |
| Per questioni di data-scaling si trova in data centers | Non comunica direttamente con un altro client |
2.2. Peer-To-Peer (P2P)
Questo diverso protocollo di comunicazione permette di evitare l’esigenza di avere un server sempre attivo.
Infatti si permette la comunicazione tra due host diversi, che possono agire sia da client che da server.
I pari (peers) richiedono servizi da altri peers (spesso file), in modo che da quel momento in poi anch’essi possano fornirlo. In questo modo si ha una self scalability.
Questa architettura risente però del fatto che i peers non sono connessi costantemente, né utilizzano IP permanenti. Questo rende la gestione del modello molto complesso.
2.3. Comunicazione tra processi
Definiamo un Processo:
È un programma che viene eseguito al’interno di un host
Si dividono in:
- Processi client: processi che iniziano la comunicazione
- Processi server: processi che attendono di essere contattati
All’interno dello stesso host, due processi possono comunicare tra di loro utilizzando comunicazioni inter-processo, definite dal sistema operativo.
Affinché due processi di host diversi possano comunicare, lo fanno scambiandosi messaggi.
In applicazioni P2P le applicazioni hanno sia processi client che processi server.
2.4. Sockets
Per poter scambiare messaggi si utilizzano i socket.
I socket sono strutture fisicamente reali, che gestiscono le comunicazioni come se fossero delle porte. I processi che inviano messaggi li fanno uscire dal socket. Questi processi si affidano all’infrastruttura “dall’altro lato della porta” per consegnare correttamente il messaggio all’altro socket.
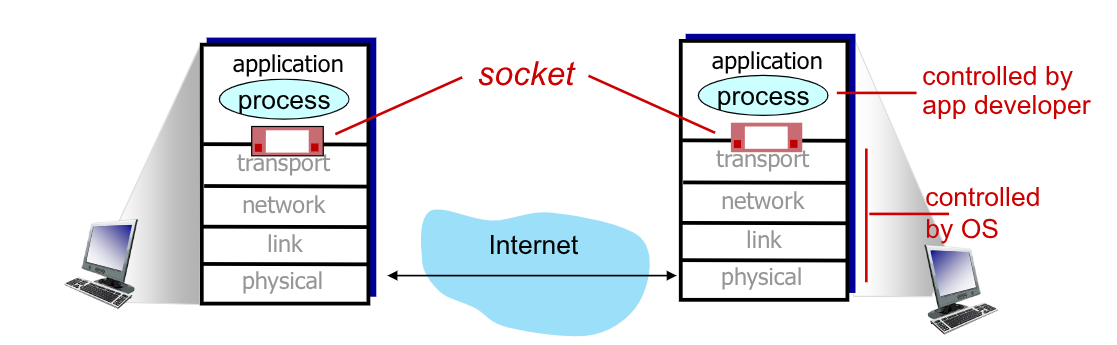
Quando un messaggio viene inviato attraverso una SEND, questa sfrutta i socket per riuscire a inviare e trasmetterlo.
Per ricevere i messaggi ogni processo deve avere un identificatore, che nei dispositivi host è:
IPunico a32bit(IPv4) o128bit(IPv6): questo numero definisce il calcolatore nella rete- Numero di porta: questo numero definisce il processo all’interno del calcolatore, così da poter avere più processi che comunicano in rete in parallelo
3. Applicazioni client-server
Esistono tantissipi tipi diversi di applicazioni, e ognuna di esse segue uno o più protocolli di riferimento che permetteno la corretta trasmissione dei messaggi tra le due.
Un protocollo di livello applicazione definisce il formato dei messaggi che l’applicazione invia e riceve. La sintassi del messaggio comprende:
- Tipo del messaggio scambiato:
Requestin caso di richieste oResponseper le risposte - Sintassi del messaggio: quali campi sono presenti e come sono delineati
- Semantica del messaggio: comprende il significato dell’informazioni nei campi
- Regole di comportamento: sanciscono come l’applicazione deve comportarsi prima, durante e dopo lo scambio del messaggio.
Di questi protocolli ce ne sono tanti, di diverse forme:
- Open Protocols: sono protocolli messi a disposizione di chiunque, definiti attraverso
RFCufficiali o testi di riferimento non ufficiali. Permettono l’interoperabilità. Alcuni esempi sono l’HTTPe l’SMTP - Protocolli proprietari: sono protocolli privati esclusivi degli ideatori. Un esempio era il protocollo utilizzato da Skype
Per sviluppare un applicazione dobbiamo prima capire come i dati vengono trasferiti.
Alcune applicazioni hanno infatti necessità di garanzie l’integrità dei dati trasmessi. Se infatti durante l’invio di un file si verificassero molti errori, il file risulterebbe corrotto, incorretto o addirittura inutilizzabile.
Altre applicazioni invece possono tollerare alcuni errori, non necessitando della correttezza dei dati al 100%. Un esempio sono le applicazioni che si occupano di trasmissione di audio e/o video, dove piccole perdite dei dati non influiscono sulla qualità del prodotto finale.
È inoltre importante stabilire le esigenze sul delay di invio e ricezione messaggi. Per applicazioni real-time, come i live streaming o giochi online, è richiesto infatti un delay basso per essere efficace, per applicazioni asincrone invece è tollerabile anche un delay più ampio.
Alcune app, come ad esempio quelle multimediali o di streaming, per essere efficaci necessitano invece che il throughput rispetti un certo minimo, altre invece, dette elastiche, possono utilizzare qualsiasi throughput.
Ultimo, ma non meno importante, è invece la sicurezza che l’applicazione richiede. Alcune applicazioni infatti maneggiano informaizoni sensibili per i quali vogliamo che i dati siano sempre al sicuro, altre invece che non maneggiano alcuna informazione si possono accontentare di sicurezze minori.
Una tabella che mostra alcuni requisiti per applicazioni comuni è la seguente:
| Applicazione | Perdita Dati | Throughput | Sensibilità al delay |
|---|---|---|---|
| Trasferimento file/Download | No | Elastico | Nessuna |
| No | Elastico | Nessuna | |
| Documenti Web | No | Elastico | Nessuna |
| Audio/Video real-time | Tollerante | audio: 5Kbps-1Mbpsvideo: 10Kbps-5Mbps |
10ms |
| Streaming Audio/Video | Tollerante | audio: 5Kbps-1Mbpsvideo: 10Kbps-5Mbps |
pochi ms |
| Giochi Interattivi | Tollerante | Kbps+ |
10ms |
| Messaggistica di testo | No | Elastico | Nessuna |
3.1. Protocolli Internet
I servizi di comunicazione su internet sono il protocollo TCP e quello UDP.
Servizio TCP
È un protocollo di trasporto affidabile nei processi di invio e ricezione.
Permette di controllare il flusso di comunicazioni, così da non sovraccaricare di messaggi il ricevitore, implementando servizi di controllo delle congestioni quando il network è sovraccaricato.
Non fornisce garanzie sul delay, sul throughput minimo né sulla sicurezza, ma si orienta sulla connessione: è infatti necessario un setup tra i processi client e quelli server.
Servizio UDP
È un servizio di trasferimento “non affidabile”, ovvero che non prevede l’affidabilità delle comunicazioni. I dati possono arrivare non in ordine o affetti da errore.
Non prevede affidabilità, controllo di flusso e di congestione, di delay, di throughput né di sicurezza.
Anche se sembra che questo servizio sia praticamente inutile e inefficace, questo è ampiamente utilizzato, poiché permette comunicazioni delle informaizoni più rapide e semplici.
Di seguito vediamo quale protocollo utilizzano comunemente le applicazioni web:
| Applicazione | Application Layer Protocol | Protocollo di trasporto |
|---|---|---|
| Trasferimento file/Download | FTP [RFC 959] | TCP |
| SMTP [RFC 5321] | TCP |
|
| Documenti Web | HTTP 1.1 [RFC 7320] | TCP |
| Telefonia Internet | SIP [RFC 3261], RTP [RFC 3550] o proprietario | UDP o TCP |
| Streaming Audio/Video | HTTP [RFC 7320], DASH | TCP o UDP |
| Giochi Interattivi | WOW, FPS (proprietario) | UDP o TCP |
I socket TCP e UDP di base non forniscono alcuna encryption, infatti trasmettono anche dati sensibili, come le password, come plaintext.
Per poter garantire l’encriptazione dei dati si utilizza il servizio TLS (Transport Layer Security). Questo servizio permette di utilizzare connessioni TCP criptate che garantiscono non solo l’integrità dei dati, ma anche un autenticazione end-point.
Il protocollo deve però essere implementato dalle applicazioni, che utilizzano librerie TLS sulle connessioni TCP.
Inoltre fornisce delle TLS socket API che criptano il plaintext fornito alla socket prima di inviarlo su internet. Vedremo meglio come funziona più avanti.
3.2. Web e HTTP
Prima di vedere le applicazioni web facciamo prima un breve ripasso.
Le pagine web consistono di oggetti, che possono essere salvati su web server differenti. Questi oggetti possone essere file HTML, immagini JPEG, applet Java, file audio mp3, …
In genrale:
Una pagina web consiste in un file
HTMLdi base che include diversi riferimenti ad oggetti, recuperabili attraverso unURL\(\underbrace{\text{www.someschool.edu}}_{\textit{host name}}\text{/}\underbrace{\text{someDept/pic.gif}}_{\textit{path name}}\)
La sigla HTTP sta per HyperText-Transfer-Protocol, ed è un protocollo di livello applicazione.
Si basa sul modello client/server:
- client: tipicamente un browser che richiede, riceve e mostrare gli Web object
- server: tipicamente un web server che invia Web object in risposta alle richieste
Il protocollo HTTP utilizza comunicazioni TCP. In particolare il client, quando fa una richiesta, inizializza la connessione TCP (ovvero crea un socket) al server nella porta 80. Il server accetta la connessione TCP del client, e viene invializzato uno scambio di messaggi HTTP tra il browser (HTTP client) e il web server (HTTP server).
Al termine la connessione TCP viene chiusa.
Questo protocollo si dice stateless, infatti il server non salva alcuna informazione sulle precedenti richieste di un client. Infatti i protocolli che mantengono uno stato sono più complessi, in quanto richiedono non solo il salvataggio degli stati con ciascuno dei client, ma anche una sincronizzazione tra le informazioni del client e del server qual’ora uno dei due crashasse e gli stati diventassero incosistenti.
Le connessioni HTTP si classificano in due tipologie
HTTP non persistente
Questa tipologia:
- Apre una connessione
TCP - Invia al massimo un oggetto attraverso la connessione
- Chiude la connessione
TCP
Questo implica che l’invio di più oggetti richiede tante connessioni quanti sono gli oggetti.
HTTP persistente
Questa tipologia invece:
- Apre la connessione
TCPcon il server - Invia più oggetti tra il client e il server sulla medesima connessione
TCP - Chiude la connessione
TCP
Le due tipologie hanno un’importante influenza sul tempo di risposta delle richieste.
Definiamo il RTT (Round Trip Time):
È il tempo necessario ad un piccolo pacchetto per andare dal client al server e poi tornare
Nel caso di HTTP non persistente, per ogni oggetto abbiamo:
- 1
RTTper inizializzare la connessioneTCP - 1
RTTper la richiestaHTTPe l’attesa dei primi byte della risposta - Tempo di trasmissione del file/oggetto
In totale il tempo di risposta è $2\text{RTT} + \text{tempo di trasmissione oggetto}$
Con questo approccio l’unico modo per migliorare le prestazioni è effettuare più connessioni TCP parallele per ognuno degli oggetti da recuperare.
Utilizzando invece connessioni HTTP presistenti (HTTP1.1) il server lascia la connessione aperta dopo aver inviato la prima risposta. Di conseguenza i messaggi HTTP tra gli stessi client/server sono inviati sulla stessa connessione, ogni qual volta che il client incontra il riferimento ad un nuovo oggetto. Abbiamo quindi che nel caso minimo abbiamo un solo RTT per tutti gli oggetti, dimezzando il tempo di risposta.
3.2.1. Formato messaggi HTTP
Esistono due tipi di messaggi HTTP: request e response
Le request HTTP sono scritte in formato ASCII.
Ogni riga è divisa dai caratteri di ritorno a carrello e nuova riga \r\n.
La prima riga rappresenta la request line che può utilizzare diversi comandi:
GET: per inviare dati al server. Include i dati dell’user direttamente nell’URLdella richiestaHTTP, inserite subito dopo il carattere?www.somesite.com/animalsearch?monkeys&banana
POST: invia oltre la pagina web anche gli input di un form, inviati in un corpo identità chiamatoHTTP POST request messageHEAD: richiede solamente gli header, senza gli oggetti. È spesso utilizzato durante le fasi implementativePUT: permette di caricare nuovi file/oggetti al server rimpiazzando completamente il file che esiste nell’URLspecificato con il contenuto dellaHTTP POST request message
Successivamente abbiamo gli le righe di header che contengono diverse informazioni.
Gli ultimi caratteri sono i 4 caratteri \r\n\r\n.
Un esempio:
GET /index.html HTTP/1.1\r\n
Host: www-net.cs.umass.edu\r\n
User-Agent: Firefox/3.6.10\r\n
Accept: text/html,application/xhtml+xml\r\n
Accept-Language: en-us,en\r\n
Accept-Encoding: gzip,deflate\r\n
Connection: keep-alive\r\n
\r\n
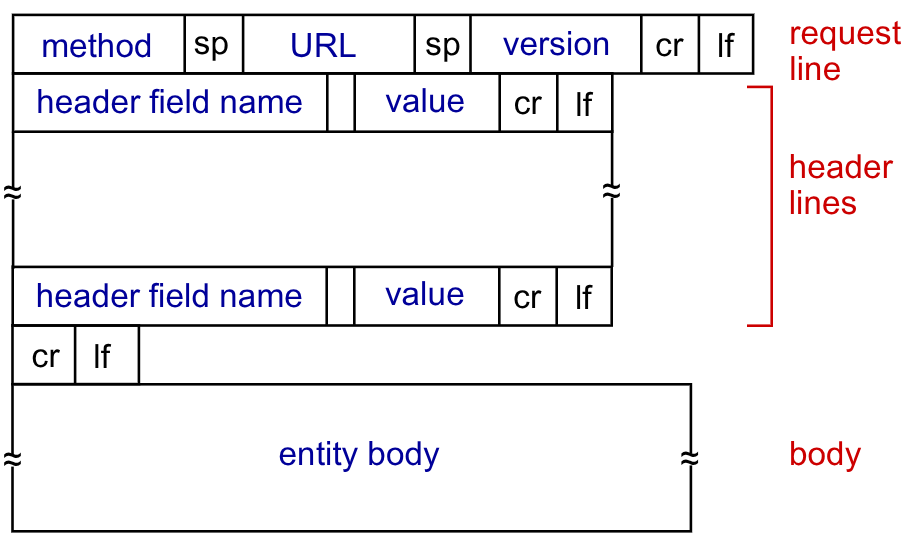
Il formato generale
Anche le HTTP response sono scritte in caratteri ASCII:
HTTP/1.1 200 OK\r\n
Date: Sun, 26 Sep 2010 20:09:20 GMT\r\n
Server: Apache/2.0.52 (CentOS)\r\n
Last-Modified: Tue, 30 Oct 2007 17:00:02
GMT\r\n
Content-Length: 2652\r\n
Keep-Alive: timeout=10, max=100\r\n
Connection: Keep-Alive\r\n
Content-Type: text/html\r\n
\r\n
data data data data data ...
Nella prima riga troviamo subito lo status code. Questo codice compare in ogni risposta nell’architettura client-server.
Ogni codice ha un significato, alcuni sono:
200 OK: richiesta completata con successo. L’oggetto richiesto si trova dopo nel messaggio301 Moved Permanently: oggetto della richiesta spostato, la nuova locazione è specificata dopo nel messaggio (sezioneLocation:)400 Bad Request:HTTP requestnon compresa dal server404 Not Found: documento richiesto non trovato su questo server505 HTTP Version Not Supported
È possibile provare a inviare delle richieste a dei server direttamente dalla shell attraverso il comando telnet:
# Apriamo una connessione TCP alla porta 80 del sito gaia.cs.umass.edu
telnet gaia.cs.umass.edu 80
# da adesso tutto quello che scriveremo sarà inviato alla porta 80 del webserver
# possiamo scrivere una richiesta GET
GET /kurose_ross/interactive/index.php HTTP/1.1
Host: gaia.cs.umass.edu
# Dopo aver effettuato un doppio invio questa breve richiesta GET viene effettuata al server
La risposta del server è questa:
HTTP/1.1 200 OK
Date: Wed, 01 Oct 2025 14:05:18 GMT
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/7.4.33 mod_perl/2.0.11 Perl/v5.16.3
X-Powered-By: PHP/7.4.33
Set-Cookie: DevMode=0
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
398b
<!DOCTYPE HTML>
<html>
…
3.2.2. Cookies
Ricordando che le interazioni tramite HTTP GET/ sono stateless, non abbiamo alcuna nozione per effettuare scambi a più step di messaggi HTTP per completare una trasazione.
Si utilizzano quindi i Cookies. I Cookies permettono di rendere stateful il protocollo stateless.
In questo modo, quando l’utente lo desidera, è possibile conservare lo stato attraverso gli step della transizione. Permettono inoltre di recuperare le transizioni parzialmente completate.
Il meccanismo dei cookies ha 4 componenti:
- Inserimento della cookie header line del messaggio
HTTP response - Inserimento della cookie header line del messaggio
HTTP request - Salvataggio del cookie nell’host client, gestiti nel file dei cookie dal browser
- Salvataggio dei cookie assegnati all’interno del website attraverso un database
Adesso le comunicazioni hanno una forma simile a questa:
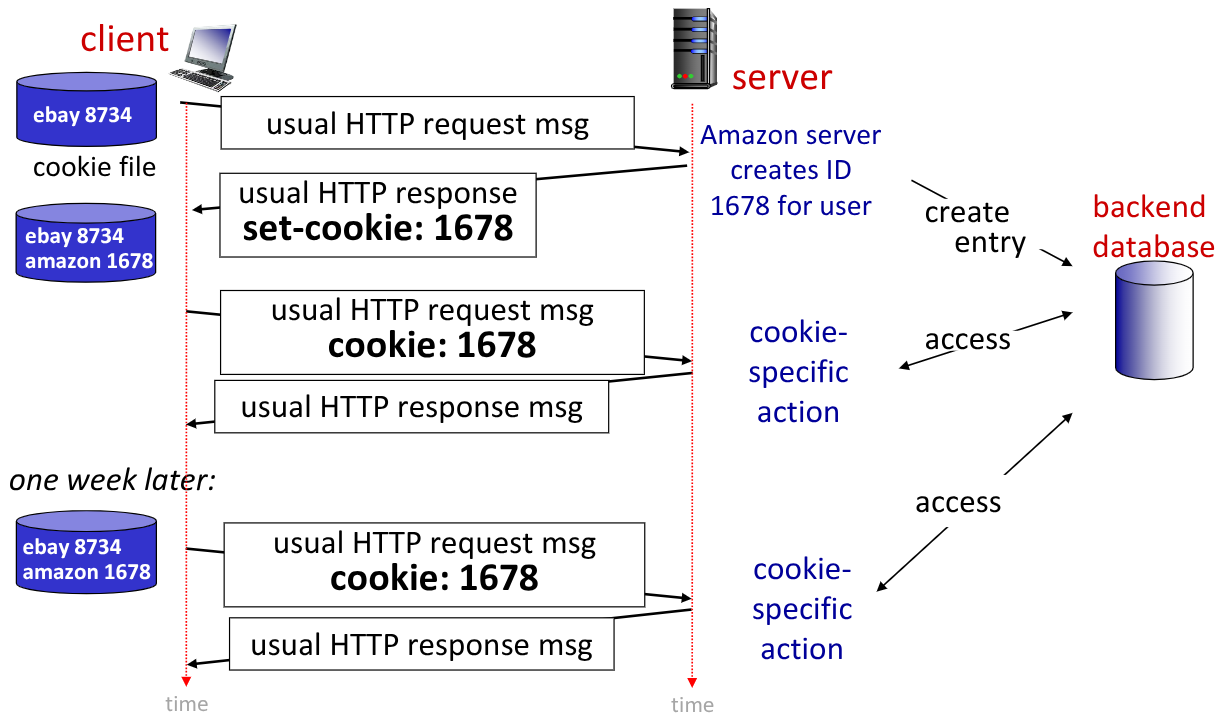
I cookie possono essere utilizzati per diversi scopi:
- Concessione di autorizzazioni
- Mantenimento di carrelli di acquisti
- Raccomandazioni e preferenze
- User session state
- …
Il meccanismo dei cookie non è l’unico con il quale è possibile mantenere lo stato. Infatti è possibile implementare anche diversi endpoints protocol per ottenere lo stesso risultato.
I cookies permettono ai siti di apprendere molte informazioni relative all’utente che naviga su un dato sito. In particolare esistono i third party persistent cookies che sono dei cookies di tracciamento che permettono di associare ad un utente un identità comune tracciabile attraverso diversi siti web.
3.2.3. Proxy Servers
I tempi di risposta nelle applciazioni devono rispettare dei vincoli di tempo sotto i quali è impossibile andare.
Nel tempo si sono quindi cercato delle metodologie per soddisfare le richieste dei client senza contattare direttamente il server di origine.
Per fare ciò si utilizza un protocollo simile a quello utilizzato nei processori, andando ad applicare i principi di località spaziale e temporale.
Ha quindi senso pensare ad una web cache che permette di evitare le richieste già effettuate in precedenza.
L’utente deve solamente configurare il proprio browser affinché per ogni richiesta consulti prima una Web Cache (Proxy):
- Se gli oggetti richiesti sono nella cache vengono restituiti immediatamente, tagliando di molto i tempi di risposta
- Se gli oggetti non sono presenti, il server proxy effettua la richiesta al server di origine e salva localmente la risposta prima di restituirla al client.
I proxy hanno quindi un doppio ruolo:
- Client quanto effettuano le richiesta ai server originali
- Server quando inoltrano le informazioni già ottenute al client
Tipicamente queste web cache sono installate direttamente dalle ISP, e permettono di raggiungere diversi vantaggi:
- Diminuisce il tempo di risposta al client, data proprio la vicinanza
- Diminuisce il traffico all’access link degli
ISP - Diminuisce il traffico su internet, diminuendo le probabilità di congestione
Può capitare che la copia contenuta nel proxy sia obsoleta, poiché il server ha aggiornato la sua versione della pagina.
Si utilizzano in questi casi le conditional GET. permettono di inviare l’oggetto solo se la versione contenuta dal server è più recente di quella contenuta in cache.
Questo è possibile con l’introduzione di un nuovo parametro if-modified-since: <date>.
È infatti sufficiente inserire come argomento la data della versione della copia contenuta, e il server risponderà:
- Con l’oggetto se è stato aggiornato più recentemente
- Con risposta
HTTP/1.0 304 Not Modified
3.2.4. HTTP+
Fin’ora abbiamo parlato dello standard HHTP1.0.
Nella versione 1.1 venne aggiornato l’algoritmo di scheduling introducendo l’algoritmo FCFS (Frst-Come-First-Serve).
In questo modo è stata introdotta la possibilità di effettuare richieste GET multiple in pipeline.
Seppur adesso il server sia impostato per rispondere in ordine di arrivo si verificano problemi di HOL blocking (Head-of-Line blocking), ovvero oggetti più massicci che bloccano oggetti più piccoli.
Inoltre i processi di recupero pacchetti persi, bloccano la trasmissione degli oggetti.
Con l’introduzione di HTTP/2 [RFC 7540,2015] è stata aumentata la flessibilità con il quale i server inviano gli oggetti al client.
Con questo protocollo tutti gli oggetti vengono divisi in frame. In questo modo è possibile per il server comunicare i gli oggetti in base alla priorità che il client gli assegna. Quando arriverà un frame a priorità più alta, il server procederà con il suo invio, magari interromplendo l’invio dell’oggetto attuale.
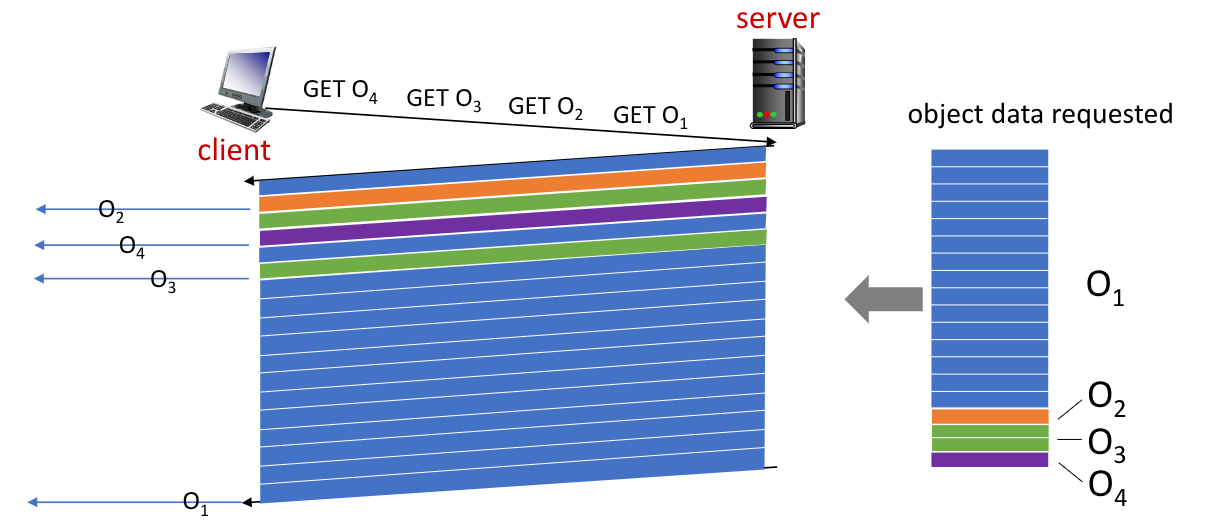
Il protocollo HTTP/2 opera ancora sul protocollo TCP, che quindi non fornisce alcun mezzo di sicurezza.
Oggi stiamo transitando verso HTTP/3 che invece aggiunge nativamente la sicurezza, migliora il controllo in caso di errori e congestioni. Per fare ciò si utilizzano connessioni UDP, che permette di evitare di aprire le connessioni.
Più informazioni su questo metodo si vedranno nei corsi magistrali.
3.3. Email e protocolli
Quando parliamo di posta elettronica ci sono 3 attori principali:
- User agent: il software che permette di accedere e inviare la posta elettronica
- I server di posta elettronica (mail-server): contengono i messaggi (codificati in
7-bit ASCII) in entrata all’interno della mailbox - Il Simple Mail Transfer Protocol
SMTP
I messaggi, quando vengono inviati, vengono inseriti in una coda di messaggi da mandare. Lo stesso mail server si comporta da:
- Client: quando invia dei messaggi che ha ricevuto
- Server: quando riceve dei messaggi inviati da altri web server
Il protocollo con il quale i server comunicano con i client si chiama SMTP.
Si basa sul protocollo TCP, inizialmente utilizzando la porta 25. La connessione è diretta, i due mail server che comunicano affrontano tre fasi di scambio durante la fase di trasferimento:
- Handshake
- Trasferimento vero e proprio
- Chiusura
L’interazione è di tipo command/response:
- I commands sono rappresentato da
ASCII text - Le response sono in un formato che comprende codice di status e descrizione
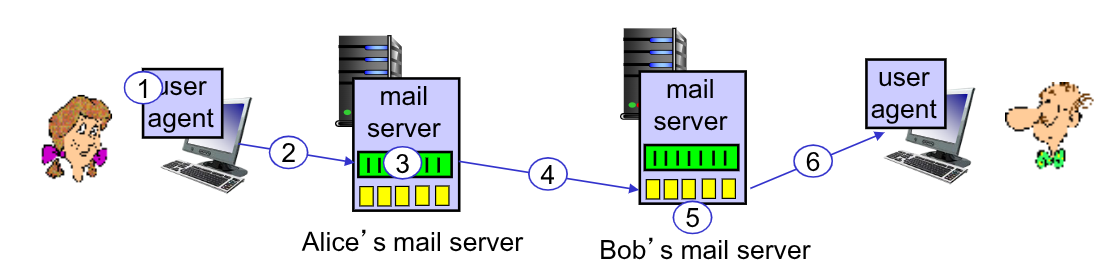
Facciamo quindi un esempio per vedere come avviene il trasferimento di posta elettronica tra Alice e Bob:
- Alice utilizza un user agent (gmail, Outlook, …) per scrivere un messaggio a
bob@some.edu - L’UA invia il messaggio al proprio mail server, posizionandolo nella message queue
- Il mail server di Alice si comporta da client inizializzando una connessione
TCP, seguendo il protocolloSMTP, con il mail server di Bob - I messaggi vengono trasferiti sulla connessione
- Il mail server di Bob conserva i messaggi trasferiti nella mailbox di Bob
- Quando Bob aprirà il suo UA troverà i messaggi che potrà leggere
Possiamo immaginare che il protocollo SMTP sia qualcosa del genere (S server, C client):
S: 220 hamburger.edu
C: HELLO crepes.fr
S: 250 Hello crepes.fr, pleased to meet you
C: MAIL FROM: <alice@crepes.fr>
S: 250 alice@crepes.fr... Sender ok
C: RCPT TO: <bob@hamburger.edu>
S: 250 bob@hamburger.edu ... Recipient ok
C: DATA
S: 354 Enter mail, end with "." on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 hamburger.edu closing connection
Oggi la porta 25 non è più utilizzata per motivi di sicurezza, tuttavia alcuni mail server consentono ancora comunicazioni su quella porta.
Con questi mail server è possibile provare a connettersi anche dalla shell:
telnet <server_name> 25
Il protocollo SMTP e quello HTTP sono simili:
SMTP |
HTTP |
|
|---|---|---|
| Comportamento | command/response | request/response |
| Tipo di comunicaizone | push | pull |
| Comunicazione | persistente | |
| Formato Oggetti | Più oggetti inviati in un singolo messaggio, codificato 7-bit ASCII |
Ogni messaggio incapsulato in un messaggio apposito |
Il protocollo STMP è definito in RFC 531, mentre la sintassi del messaggio è definita da RFC 822:
- Header line
- To:
- From:
- Subject:
- ….
- Corpo del messaggio: codificato solo con caratteri
ASCII
Il protocollo SMTP in realtà descrive solo il protocollo di comunicazione per inviare i messaggi ai mail server del destinatario, non al suo user agent. Infatti se l’UA fosse spento sarebbe impossibile inviarvi messaggi, andando a perderli.
Per recuperare le mail dal proprio mail server esistono altri due protocolli:
IMAP(Internet Mail Access Protocol): definito inRFC 3501, i messaggi rimangono salvati sul server. Il protocollo permette il recupero, l’eliminazione e l’incartellamento dei messaggi sul server. Sull’UA si hanno dei riferimenti ai messaggi nella mailbox. Più client diversi vedono quindi sempre tutta la stessa posta.POP: i messaggi vengono “poppati”, ovvero estratti dal mail server, spostandoli permanentemente su un client. Con questo protocollo se un client accede al mail server dopo un’altro, non vede la posta già visualizzato dal primo.
Oggi esistono tantissime interfacce web basate su SMTP/IMAP(POP) per inviare e recuperare le email. (gmail, Hotmail, Yahoo!Mail, …).
3.4. DNS
Il DNS (Domain Name System) è ciò che permette alle personi di tradurre gli URL in indirizzi IP.
Precedentemente avevamo già visto come sul web ogni host e router sia identificato dagli indirizzi IP su 32bit (o 128bit nelle versioni moderne, ma non li affronteremo). Tuttavia, come umani, siamo più avvezzi a ricordare dei nomi simbolici piuttosto che delle sequenze di numeri.
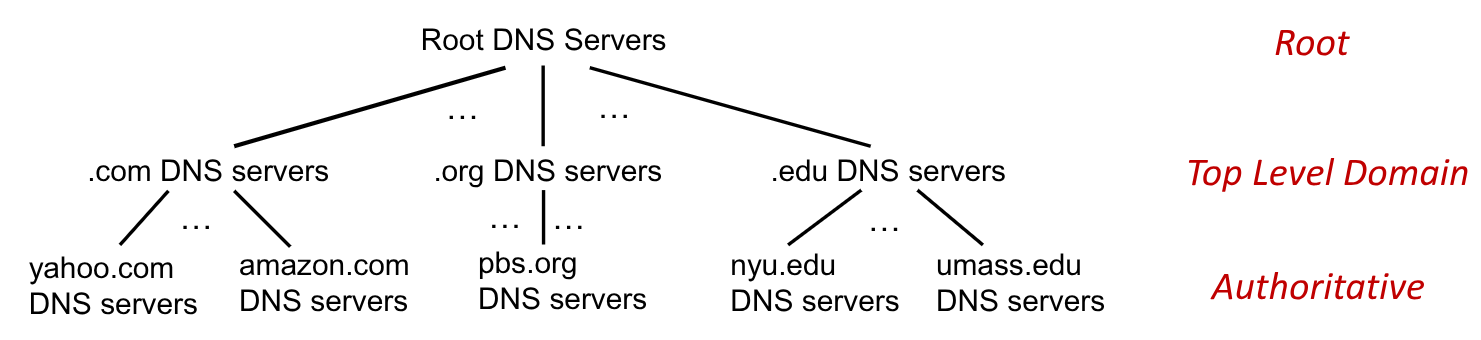
Il DNS implementa un database distribuito, basato sulla gerarchia dei nomi di dominio. Un dominio può rappresentare un’organizzazione (tipicamente americana) privata, in questo caso chiamati Top-Level Domain TLD, oppure di uno stato (Country Code TLD) CCTLD.
In questo modo si riduce l’univocità solo all’interno del dominio di riferimento. L’ente che si occupa di gestire l’assegnazione dei nomi all’interno dei domini è l’ICANN (Internet Corporation for Assigned Names and Numbers). Per farlo essa mantiene un registro dei nomi (sottodomini) registrati all’interno del dominio di riferimento.
Il DNS fa parte del livello applicazione: sono infatti gli host che effettuano le richieste con i nomi simbolici, ed è quindi necessario ancora prima di effettuare la richiesta vera e propria di effettuare la resolve del nome in un indirizzo.
Questo step comporta però un elevata complessità sul Network Edge. Proprio per questo non esiste un unico server DNS centrale, che provocerebbe:
- La creazione di un singolo point of failure
- La creazione di un enorme volume di traffico (infatti un server locale può andare in contro a più di
600Bqueries) - Il difficile mantenimento di un database enorme e distante dai vari client
Il DNS si occupa quindi di:
- Tradurre hostname in indirizzi
IP - host aliasing: permette di avere più hostname per lo stesso indirizzo
IP - mail server aliasing
- Distribuire il carico sui vari web server. Il
DNSè replicato sui vari server in maniera furba. Infatti, per non avere copie enormi dello stesso database, si fa in modo che più hostname diversi, che avrebbero traduzioni diverse, puntino tutte allo stesso webserver. Quest’ultimo si occuperà di ritradurre l’hostname secondo il proprioDNS, che stavolta potrebbe essere per quegli indirizzi più specifico.
Se un client vuole trovare l’IP di www.amazon.com, possiamo approssimare la sua ricerca come:
- Query al server di root per trovare il
DNSserver per traduzioni.com - Query al server
DNSdei.comper trovare il serverDNSperamazon.com - Query al server
DNSdiamazon.comper trovare l’IPdiwww.amazon.com
Esistono 13 server di root sparsi per il mondo (nessuno in Italia), ognuno implementato da server factory. Questi server sono in realtà contattati come last-resort dai server di dominio che non riescono ad effettuare la traduzione. Questi hanno però un importanza incredibile per il funzionamento di internet.
I server DNS si dicono authoritative se sanno tradurre url in indirizzi IP invece di rimandare ad altri server DNS.
I server TLD sono authorative per i domini come: .com, .org, .net, .edu, .aero, .jobs, .museums e tutti i CCTLD come: .it, .uk, .fr, .ca, .jp, .cn.
In realtà esiste un local DNS server che potrebbe non rispettare la gerarchia (in realtà c’è anche un secondario per affidabilità). Questi sono forniti dagli ISP (o dalle organizzazioni private), e sono conosciuti anche sotto al nome di default name server.
Il loro ruolo è quello di agire da proxy quando un host richiede una traduzione, il risultato viene prima salvato nella cache dal lDNSs, così da non dover rieffettuare la richiesta in un secondo momento.
Esistono due modi per effettuare le richieste di traduzione. Immaginiamo di avere:
- host:
enineering.nyu.edu - host:
gaia.cs.umass.edu
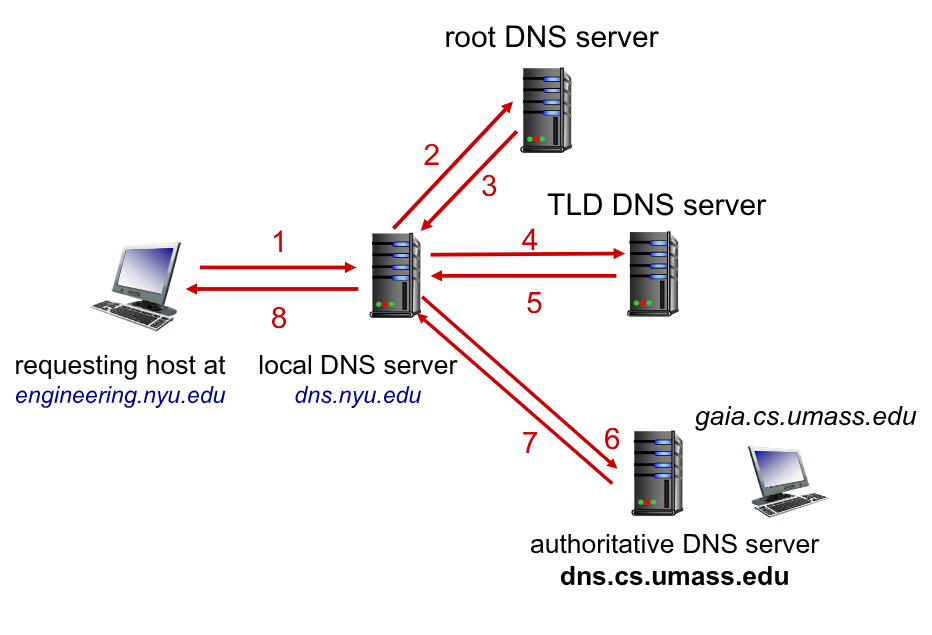
Query Iterativa
Quando si effettua una richiesta il lDNSs (se questo non ha la traduzione), lui chiede al server di root.
Se il root non ha la traduzione ritorna al lDNSs l’indirizzo IP del DNSs .edu
Il lDNSs chiede quindi a DNSs .edu, anche lui non authorative, che lo rimanda al DNSs umass.edu
La richiesta del lDNSs a DNSs umass.edu può essere authorative che restituisce finalmente l’indirizzo IP, che viene prima salvato e poi inviato al client, che solo adesso più aprire la connessione TCP.
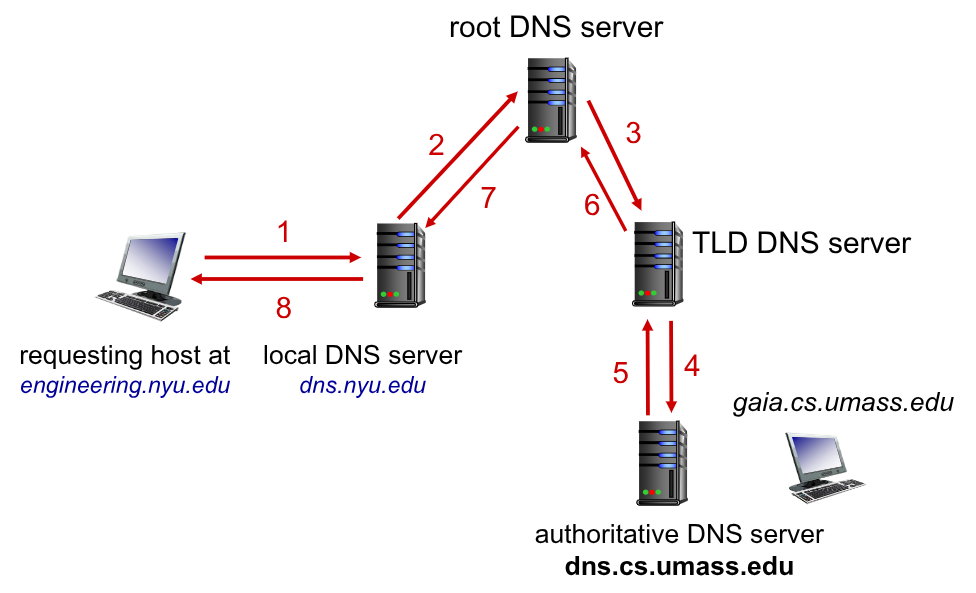
Query Ricorsiva
Funziona in maniera simile a quella delle query iterative, ma sono i DNSs stessi a effettuare le richieste per i livelli inferiori.
In questa architettura sono quindi necessari più cache level per ogni DNSs così da diminuirne il carico.
Quando un DNSs impara una nuova traduzione, la salva in locale su una sua cache interna. Un entrata di questa cache scade, ovvero viene rimossa, dopo un time-to-live TTL.
È quindi possibile che le entrate locali di un DNSs possano tutte essere scadute, oppure non aggiornate correttamente con la traduzione attuale (in caso di cambio di IP da parte di un host già cachato)
I meccanismi di aggiornamento e di notifica sono descritti dallo standard IETF nel RFC 2136.
3.4.1. Record del DNS
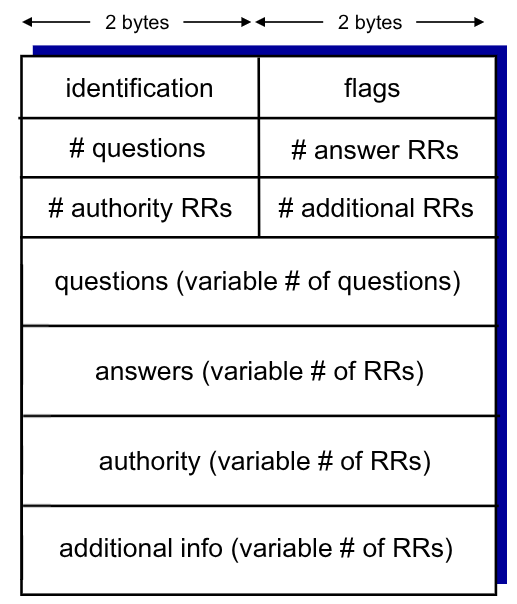
Abbiamo detto che il DNS è un database disribuito che conserva resource records RR.
Il loro formato è il seguente:
(name, value, type, ttl)
A seconda del type gli altri parametri (tranne il ttl) hanno significati diversi:
| Type | Name | Value |
|---|---|---|
A |
hostname | IP address |
NS |
dominio | hostname del DNSs authoritative del dominio |
CNAME |
alias del nome canonico (www.ibm.com) |
nome canonico (servereast.backup2.ibm.com) |
MX |
/ | È il nome del mailserver associato al name |
Sia le richieste che le risposte a DNS query hanno lo stesso formato:
La prima riga è chiamata header e contiene due informazioni:
identification: sono16bitche identificano la query. La risposta utilizzerà lo stesso numeroflags: indica alcuni dettagli della richiesta (se è richiesta/risposta, se vorrebbe un algoritmo di traduzione ricorsiva e se è disponibile, se la richiesta è di tipo authorative, …)
Sono presenti poi altre 4 sezioni di 16bit che identificano il numero di:
- Question: nomi e tipi per la query
- Answers: la risposta
RRdella query - Authority: record per server authorative
- Additional Info: altre informazioni che possono essere comode da utilizzare
Sui sistemi windows è presente il comando:
nslookup
Che permette di richiedere traduzioni da terminale.
3.4.2. Registrazione di un nuovo record di dominio
Ipotiziamo di voler creare una nuova azienda Network Utopia e di voler registrarne il sito web.
Il primo passo è quello di selezionare il dominio di riferimento top-level.
Successivamente è necessario registrarsi in un DNS registratore (ad esempio Network Solution) fornendo nome di dominio e indirizzo IP del server authoritative (sia primario che secondario)
Il registratore inserisce i seguenti record nel server TLD:
(networkutopia.com, dns1.networkutopia.com, NS)traduzione di alias per ilDNSs authoritative(dns1networkutopia.com, 212.212.212.1, A)
È quindi necessario attivare un server authoritative localmente all’indirizzo 212.212.212.1 che traduca:
- Record
Aperwww.networkutopia.com - Record
MXpernetworkutopia.com
4. Applicazioni Peer-To-Peer (P2P)
Sono applicazioni che seguono una filosofia diversa da quella del client-server. Infatti non c’è più una chiara distinzione tra client e server, ma i singoli host (chiamati peer) possono comportarsi in uno o in un altro in momenti diversi.
A differenza del modello client-server i peer non necessitano di essere costantemente disponibili, né di essere disponibili in indirizzi IP statici.
Le applicazioni P2P sono diverse, alcuni esempi:
- Condivisione di contenuti: i peer mettono a disposizione file per essere condivisi. Per poterlo fare però è necessario essere a conoscenza di dove si trova il file desiderato
- Messaggistica Istantanea: è necessario avere mappati gli indirizzi
IPdegli username. Quando un utente va online comunica il proprioIPcosì che gli altri utenti possano reperirlo per la comunicazione
Per tutte le applicazioni P2P è quindi necessario avere un indice che mappi le informazioni relativi agli indirizzi IP degli altri peer. Devono quindi essere fornite anche operazioni che permettano ad un peer di cercare e/o aggiornare le informazioni.
Gli indici sono contenuti in database basati su hash (key, value) $\to$ Led Zeppelin IV, 203.17.123.38.
I peer possono effettuare query a partire dalla chiave, o inserire intere coppie.
In questo modo si ha un indice centralizzato accessibile tramite Hash table distribuite
L’indice centralizzato può essere fornito da uno o più server, come ad esempio in Napster (un sistema ILLEGALE per la condivisione di musica).
In questi casi quando un utente diventa attivo, l’applicazione notifica l’indice con il suo indirizzo IP e i suoi file disponibili.
L’approccio in questi casi è ibrido:
- La distribuzione dei file è
P2P - La ricerca degli indirizzi
IPè client-server
Prendendo sempre come esempio Napster, abbiamo che l’indice centralizzato si trova a napster.com. Questo però ha due svantaggi che avevamo già visto: il single-point of failure e il performance bottleneck.
Un altro approccio completamente decentralizzato è quello del Query Flooding.
Introdotto nella versione originate di Gnutella (LimeWire). Si basa su un network di overlay rappresentabile come un grafo. Il grafo ha come nodi i peers attivi, e come edges le connessioni TCP tra i peer.
Il modello di query flooding si basa su fatto che se un peer non ha l’oggetto richiesto da un peer può propagare la stessa domanda agli altri peer ai quali è collegato, attraversto risposte unicast. Quando viene trovato un peer con i contenuti richiesti è solo il peer iniziale che scarica i contenuti. Questo approccio è scalabile, e spesso introduce un limite al flooding, riducendo il traffico e diminuendo le probabilità di localizzare il contenuto finale.
Esiste poi un ulteriore metodo che combina le migliori feature degli approcci precedenti, si chiama Overlay Gerarchico. Venne prodotto in FastTrack ed è anche utilizzato dal moderno Gnutella.
Non ha un server centrale ma introduce delle gerarchie tra gli peer.
Vengono introdotti i Super Nodes SN, che sono peer selezionati, con un ampia banda e un ampia disponibilità. I peer comuni effettuano le richieste ai super-peer, che contengono gli indici dei peer locali. Se il SN ha la risposta la fornisce, altrimenti effettua anch’egli una query al suo SN di riferimento.
Alla fine il primo peer scaricerà i file dal peer che li mette a disposizione.
Questi ultimi due metodi distribuiti si definisce come il più vicino il peer più vicino in ordine di successione. Asintoticamente, con $n$ peer vanno inviati in media $O(n)$ messaggi.
4.1. Confronto P2P e client-server
Abbiamo quindi visto entrambe le tecnologie, ma come variano i tempi e le performance tra i due?
Poniamoci il problema di distribuire su una rete, con sufficientemente banda, un file di dimensione $F$ da un server con capacità di upload $u_s$ a $N$ peers, sapendo che per ogni peer:
- $d_i$: capacità di download
- $u_i$: capacità di upload
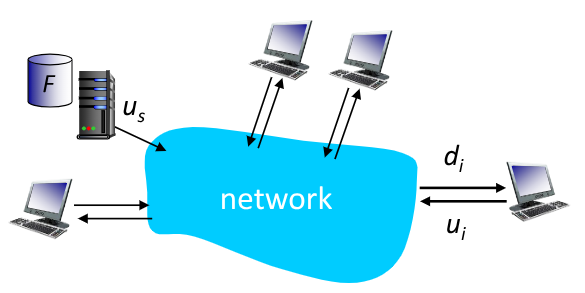
Nel caso di architetture client-server, quest’ultimo deve inviare $N$ copie dello stesso file. Sapendo che il tempo per inviare una copia è $F \over u_s$, in totale il tempo di invio sarà $N \frac{F}{u_s}$. D’altra parte ogni client deve scaricare la risorsa. Il client più lento impiegherà un tempo di $F \over d_{min}$.
Il tempo totale per distribuire a tutti i client il file sarà: \(D_{cs} \ge \max{\Biggl\{N\frac{F}{u_s}, \frac{F}{d_{min}}\Biggr\}}\)
Ipotizzando invece un approccio P2P, il “server” che contine il file dovrà caricare solamente una copia in quanto i peer possono re-distribuire i bit tra di loro, impiegando un tempo di $F \over u_s$.
I peer dovranno comunque scaricare il file, con il più lento che impiegherà sempre un tempo di $F \over d_{min}$.
Poiché ogni peer pià re-distribuire i dati, possiamo considerare la capacità totale di upload del sistema come $u_{tot} = u_s + \sum_i^N{u_i}$. Poiché il sistema, nel complesso, deve comunque consegnare $NF$ bit, abbiamo un tempo di distribuzione minimo di almeno $\frac{NF}{u_s + \sum{u_i}}$.
In totale il tempo di distribuzione necessario sarà: \(D_{P2P} \ge \max{\Biggl\{\frac{F}{u_s}, \frac{F}{d_{min}}, \frac{NF}{u_s + \sum_i^N{u_i}}\Biggr\}}\)
Nel caso di client-server abbiamo che il tempo cresce linearmente con il numero di client, mentre nel caso di P2P invece la crescita lineare cresce sì con il numero di client, ma è attenutata dalla loro capacità di upload complessiva.
Ipotizzando:
- $u_i = u$
- ${F\over u} = 1h$
- $u_s = 10u$
- $d_{min} \ge u_s$
Possiamo tracciare il seguente grafico:
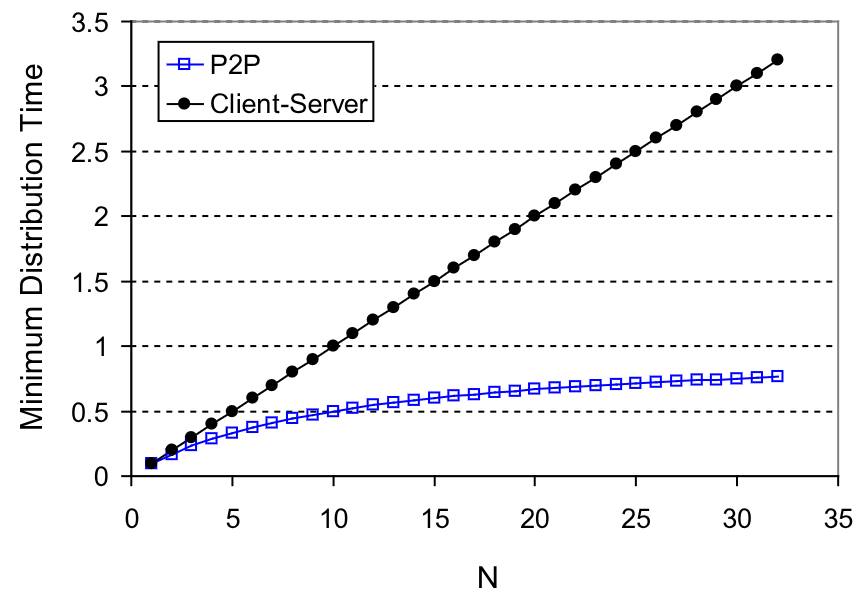
In casi generici il tempo per il P2P tende asintoticamente ad un valore di $F \over \overline{u}$
4.2. Protocollo BitTorrent
È il protocollo più utilizzato per le comunicazioni P2P. Non ha uno standard, ma è descritto in un articolo pubblico non ufficiale, preso comunque come standard di fatto.
I file vengono divisi in porzioni (chunk) di 256Kb.
I peer non vanno più a scambiarsi interi file, ma chunk di esso. In questo protocollo non ci si preoccupa del’ordine dei vari chunk, che potrebbero, e tendenzialmente lo fanno, arrivare sfusi.
Il protocollo rende la comunicazione multi-P2P, vediamo quindi perché.
Prima di fare ciò definiamo:
Torrent: l’insieme di peer che in un certo istante partecipano alla condivisione di un dato file
Nel torrent, in un certo istante troviamo tre tipi di peer:
- Leachers: coloro che devono ancora completare di scaricare il file
- Feeders: coloro che hanno completato il download del file. Potrebbero egoisticamente uscire dal torrent, ma decidono, altruisticamente, di rimanere per alimentare
- Free Riders: sono coloro che sono solo interessati a scaricare i file, senza fornire la possibilità di caricare i loro file
Con l’introduzione dei torrent si introducono anche dei tracker, che hanno come compito quello di tracciare i peer che in un certo istante fanno parte del torrent.
Quando un peer desidera ottenere un file, per prima cosa deve ottenere l’IP del tracker, richiedendolo ad un Torrent Server specificando il contenuto che desidera.
Questo restituisce un metafile .torrent nel quale si trova anche l’IP del tracker.
A questo punto il tracker viene contattato, e questi inserisce il peer nel torrent restituendogli una lista contenente gli IP degli altri dispositivi nel torrent.
A questo punto il peer cerca di effettuare connessioni TCP con tutti gli altri peer nella lista.
Statisticamente non riesce a creare una connessione con tutti i peer, ma questo non importa finché viene raggiunto un certo numero base.
I peer con i quali si riesce a instaurare una connessione vengono chiamati vicini.
Il peer chiede ai suoi vicini quali chunk possiedono, e comincia a richiederli partendo dal più raro (Rarest First), evitando di chiedere più volte lo stesso chunk e quelli che potrebbe già possiede. Infatti, se ci fosse una copia presente solo in un vicino, se questi dovesse uscire metterebbe in attesa a tempo indeterminato.
Mentre il peer scarica i chunk dai suoi vicini, questi potrebbero richiedergli altri chunk. Poiché queste richieste potrebbero essere troppe da seguire, si opera una graduatoria secondo la poiltica tit-for-tat.
Si decide di dare priorità a quei vicini che, nell’unità di tempo, mi inviano più dati. Questo scoraggia i Free Riders, e incentiva i vari peers di contribuire al torrent.
In particolare si inviano dati ai top-four providers, che tendenzialmente sono coloro che hanno una capacità di carico simile a quella del peer. Per ovviare a questa limitazione, ogni 30 secondi si seleziona casualmente un altro vicino e vi si inviano dei chunk, sperando che questo abbia una velocità di trasmissione maggiore a quella dell’attuale top-four.
5. Applicazioni di comunicazione in tempo reale
Oggi la maggior parte della banda di Internet è utilizzata per lo streaming di contenuti audio e video, sia registrati che live.
Nel 2020 l’80% del traffico era occupato dai distributori di contenuti (Netflix, YouTube, Amazon Prime Video, …).
Queste applicazioni hanno infatti platee di utenti molto grandi, anche nell’ordine del miliardo. Per riuscire a raggiungere tutti questi utenti, molto diversi tra di loro per tipo di dispositivi e capacità di rete (che potrebbe variare da istante a istante per lo stesso utente), si utilizza un’infrastruttura application-level distribuita.
L’utilizzo di un singolo mega-server comporterebbe problemi di single-point-of-failure, di sovraccarico e andrebbe a punire gli utenti fisicamente più distanti dal server e quelli meno capaci. Inoltre non permeterebbe nemmeno la scalabilità.
5.1. Streaming
I video sono:
Sequenze di immagini (frame) mostrate ad un rateo costante (frame-rate)
Un singolo frame è rappresentato come un array di pixel, ognuno rappresentato da una sequenza di 8bit.
Per diminuire il numero di bit da inviare si sfruttano le correlazioni presenti nelle sequenze video:
- Correlazione Spaziale: Avviene quando due o più pixel vicini sono sufficientemente simili da poter essere considerati uguali. Invece di inviare informazioni per ogniuno, è quindi sufficiente inviare solamente due valori: il colore e quanti pixel consecutivi lo hanno.
- Correlazione Temporale: Avviene quando due frame successivi avranno molti pixel uguali. In questi casi possiamo quindi concentrarci ad inviare solamente i valori di colore esclusivamente per i pixel che sono effettivamente cambiati
Esistono due tipi di codifica del video:
CBR(Constant Bit Rate): il rateo di encoding è fissoMPEG 1: utilizzato nei CD-ROM, è fisso a1.5Mbps
VBR(Variable Bit Rate): il rateo di encoding è cambia a seconda delle situazioni
Si dice streaming di un video, la visualizzazione di tale prima che sia stato comlpetamente scaricato.
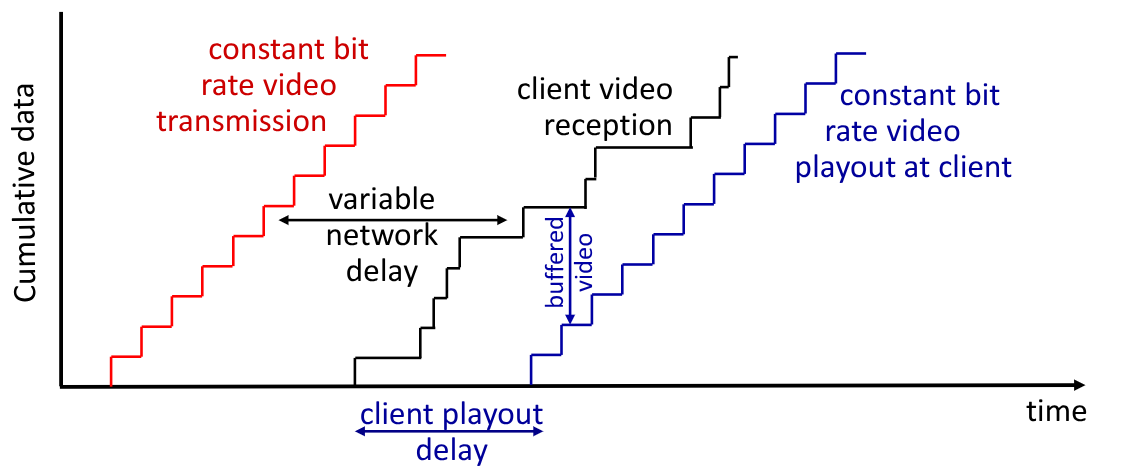
In un mondo ideale, i video registrati a 30fps vengono raccolti dal server e inviati con lo stesso rate. Il client li ottiene, dopo un certo delay, con lo stesso rate di invio e può visualizzarli senza problemi.
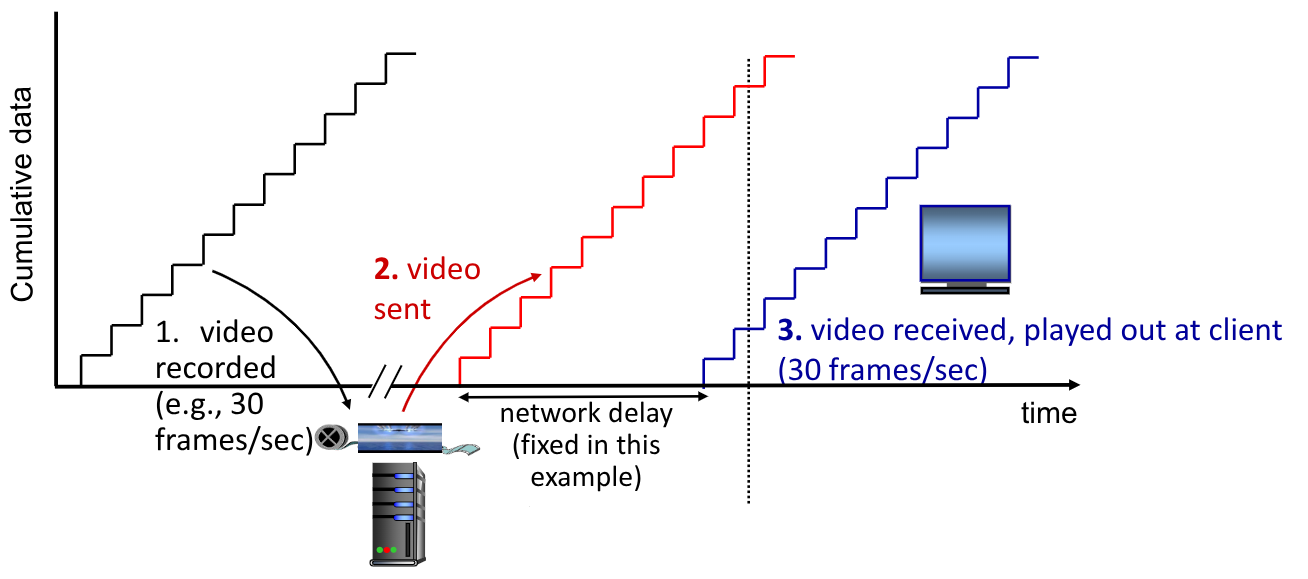
Nella realtà invece questo non accade, infatti l’utente potrebbe effettuare operazioni di pausa, fast-forward, rewind, saltare nel video. Inoltre alcuni pacchetti potrebbero essere persi, e potrebbe esserene necessario il reinvio. La variazione del delay all’interno della rete viene chiamata jitter
Per ovviare al jitter, si introduce un client playout delay. Si permette infatti al client di vedere il video solo dopo che è passato questo delay dall’arrivo del primo pacchetto, cercando quindi di compensare in questo modo il jitter perettendogli una visualizzazione CBR attraverso la bufferizzazione del video.
Una tecnica che migliora la qualità dello streaming multimediale è il DASH (Dynamic, Adaptive Streaming over HTTP).
In questo protocollo il server divide il file video in diversi chunk che vengono salvati e codificati a ratei diversi.
Viene introdotto quindi un manifest file che fornisce gli URL per i vari chunk.
Il client si occupa di misurare periodicamente la banda della connessione client-server. A seconda del suo valore consulta il manifest file richiedende un chunk alla volta, cercando di massimizzare il numero di bit data la banda in quel momento, scegliendo da diversi ratei in momenti diversi.
Questa tecnica rende il client in grado di determinare:
- Quando richiedere un chunk, per evitare overflow, buffer starvation, …
- Quale qualità di codifica richiedere: cercando di massimizzarla a seconda della banda
- Dove richiedere il chunk: può essere richiesto dal server più “vicino” o che possiede una banda più alta
Lo streaming video moderno è quindi un unione di codifica, DASH e playout buffering.
5.1.1. CDN
I CDN sono Content Distribution Networks, e si occupano di decidere come effettuare lo streaming di milioni di video a centinaia di migliaia di utenti in simultanea.
L’idea di un unico grosso “mega-server” non funziona per gli stessi motivi per il quale non ha funzionato fin’ora (single-point-of-failure, congestion, elevata distanza) oltre al fatto che avrebbe da inviare più copie dello stesso video attraverso lo stesso link, rischiando di saturare la connessione in uscita.
Si utilizzano quindi i CDN, che permettono di distribuire le informazioni, salvandole e rendendole disponibili in più sites geograficamente distributi.
Esistono due approcci per svilluppare un CDN:
- Enter deep: carica più server
CDNall’interno di diverse reti di accesso. Questo li “avvicina” agli utenti, ma è molto costoso. Un esempio è Akamai, che nel 2015 aveva più di 240.000 server distribuiti su più di 120 stati - Bring Home: crea un numero minore di cluster più grandi. Questi cluster si trovano in
POPsvicini alle reti di accesso, ma non all’interno. Un esempio di servizio che utilizza questa infrastruttura è Limelight
I CDN salvano copie dei contenuti all’interno dei nodi CDN. Quando un utente iscritto al servizio richiede un contenuto, viene direzionato ai server più vicini che contengono una copia. L’utente potrebbe inoltre richiedere copie diverse a server diversi, per ovviare alla congestione dei percorsi.
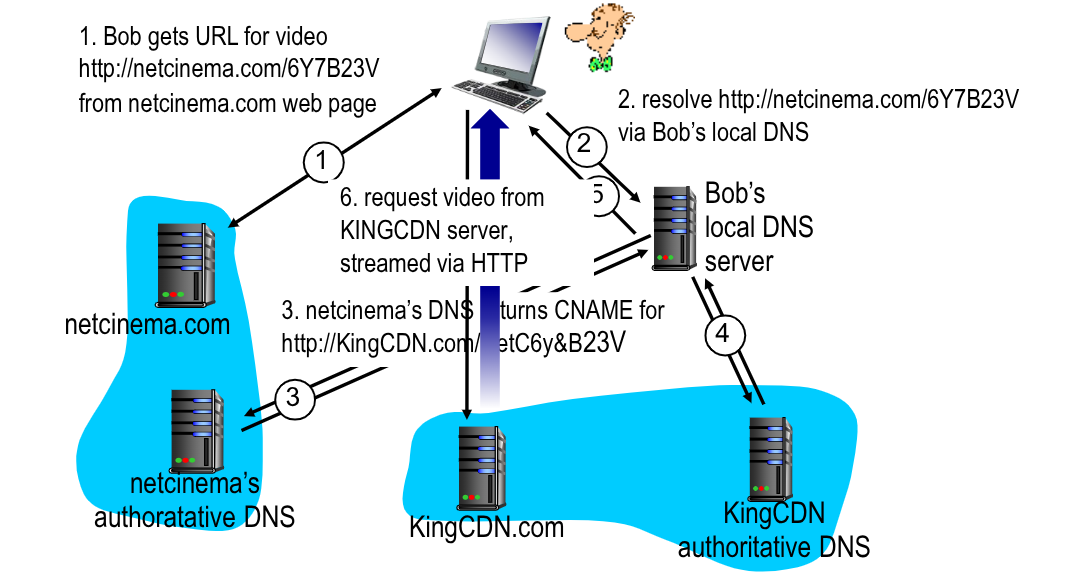
Facciamo un esempio, ipotizzando che un client (Bob) richieda un video a netcinema per un servizio che mette a disposizione contenuti appoggiandosi ad un’altra azienda (KingCDN) che invece possiede i video sui propri server.
Bob richiede al webserver di netcinema.com la pagina web, l’url fornito viene girato al DNS locale che troverà il DNS authorative di netcinema che restituisce il CNAME per il DNS auth di KingCDN che fornirà lui l’IP del server finale (di proprietà di KingCDN.com).
L’utente si collegherà quindi a questo server, ignaro del fatto che quello che crede essere su un sito, si trova sul sevrer di un altro.
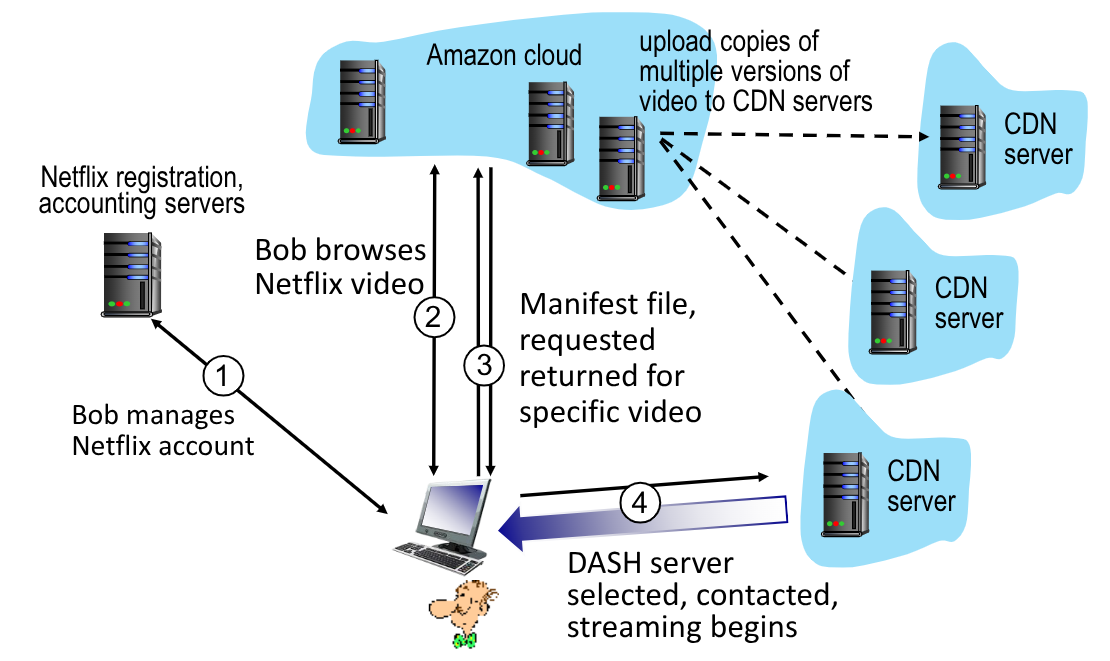
Un altro modo per distribuire i servizi è sfruttare il cloud. Un esempio di azienda che fa così è Netflix:
5.2. Socket-API
Ricordiamo che un socket è una porta di accesso per la comunicazione end-to-end tra due processi attraverso un protocollo.
Esistono due tipi di socket, ognuno che sfrutta un protocollo diverso:
UDP: fornisce datagrammi non sempre affidabiliTCP: più affidabile, orientato allo streaming dei dati ordinati
I socket UDP non richiedono una connessione client-server, non richiedono handshake di connessione, ma il mittente assegna esplicitamente un destinazione IP:port a ciascun pacchetto. Il ricevente starà in ascolto su quella porta estraendo i pacchetti in arrivo. Questo trasferimento può avvenire in ordine casuale e potrebbe soffrire di perdita di pacchetti.
Vedremo più a fondo come sviluppare client e server nelle lezioni di laboratorio.