1. Indice
2. Sistemi Multiprocesso
Per poter introdurre sistemi che possano eseguire più programmi contemporaneamente dobbiamo prima introdurre alcuni concetti.
2.1. Processi
Il primo tra i concetti che andiamo a vedere è il processo.
Un processo è un programma in esecuzione su dei dati di ingresso
Questa esecuzione la possiamo modellare come la sequenza degli stati attraverso il cui il sistema processore+memoria passa eseguendo il programma.
Questa definizione si applica bene ai programmi di tipo batch, in cui gli ingressi vengono specificati tutti all’inizio, e il processo prosegue indisturbato dino ad ottenere le uscite. Tuttavia non è difficile immaginarsi l’estensione di questa definizione ai programmi “interattivi”.
L’importante è capire che programma e processo sono due cose completamente distinte, infatti:
- Uno stesso programma può essere associato a più processi;
- Uno stesso processo può eseguire, in sequenza, più programmi;
- In generale non è esclusivamente il programma a decidere attraverso quali stati il processo dovrà passare, ma hanno influenze anche i vari segnali di input;
- Il programma potrebbe contenere dei cicli, che scrivono le cose da ripetere una sola volta, mentre nel processo vediamo le azioni ripetute tante volte.
2.2. Contesti
Per riuscire a realizzare i processi riutilizziamo il concetto che avevamo già utilizzato di contesto.
In un sistema multiprocesso infatti, il significato di una istruzione dipende dal processo che la sta eseguendo.
Se un processo P1 esegue una istruzione MOV %rax, 1000 si sta riferendo al “suo” registro %rax e al “suo” indirizzo 1000.
Mentre se la esegue un processo P2 parlerà di un diverso %rax e di un diverso contenuto dell’indirizzo 1000.
Il contesto di un processo comprenderà quindi:
- Tutta la memoria (
M2) usata dal processo. Qualora il processo non fosse in esecuzione, la immaginiamo per ora salvata nell’HD - Una copia privata di tutti i registri del processore, salvati in una opportuna struttura dati.
Per cambiare il contesto quando passiamo da un processo all’altro (ovvero quando eseguiamo swap-out e swap-in della memoria) utilizziamo tecniche sofware:
Ogni volta che si effettua un cambio di processo, andiamo a salvare in una struttura dati i valori dei registri e della memoria del processo terminato.
Successivamente copiamo i valori precedentemente salvati nella struttura dati associata al nuovo processo, rendendolo il processo corrente (o processo attivo)
Dobbiamo quindi implementare il software, in M1, che fa queste cose.
Il nome di questo software è kernel.
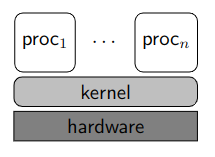
2.3. Kernel
Il kernel è quindi un software che sta sempre nello spazio di memoria di sistema (M1) e può riacquisire occasionalmente il controllo del flusso.
Il kernel gira infatti a livello sistema e può recuperare il controllo del flusso solamente tramite i gate della IDT (interruzioni esterne, eccezioni, chiamate int)
Rappresentazione dei livelli di privilegio e contesti
Il registro RIP del processore si trova sempre in uno e uno solo dei processi.
RIP non può attraversare due processi diversi, se non tramite il cambio di processo effettuato dal kernel stesso.
Il kernel ha diversi modi per decidere come saltare tra processi, noi ne vedremo uno in questo corso, mentre gli altri verranno esaminati nel corso di Sistemi Operativi.
Un’altra scelta che il kernel deve eseguire è quella di decidere la intravisibilità dei processi, ovvero se si possono interfacciare tra di loro o se sono indipendenti.
In questo corso vedremo un’implementazione mista dove ci sarà sia una parte della memoria condivisa sia una parte privata.
L’ultima precisazione da fare è che generalemnte tanti processi si riferiscono a diversi programmi, spesso persino di diversi utenti. Noi vedremo invece esclusivamente l’implementazione di un unico programma, di un unico utente, che genera tanti processi.
2.4. Semplice Sistema Multiprocesso
Il sistema che realizzeremo è organizzato in tre moduli:
sistemaioutente
Ogni modulo è un programma a sé stante, non collegato con gli altri due.
Il modulo sistema contiene la realizzazione dei processi, inclusa la gestione della memoria (tramite memoria virtuale).
Il modulo io contiene le routine di ingresso/uscita che permettono di utilizzare le periferiche collegate al sistema (testiera, video, hd, …)
Entrambi questi due moduli vengono eseguiti con il processore a livello sistema, in un contesto privilegiato, mentre utente verrà eseguito al livello utente.
Il ruolo di sistema e io è quello di fornire un supporto ad utente, sotto forma di primitive che possono essere da lui invocate.
In particolare utente può creare più processi che vengono eseguiti concorrentemente.
Il nostro sistema si sviluppa quindi nella directory nucleo-8.3/. (versione utilizzata durante la stesura di questi appunti)
Al suo interno troviamo le seguenti sottodirectory:
sistema/,io/eutente/, che contengono i file sorgenti dei rispettivi moduli;util/, che contiene alcuni script di utilità;include/, che contiene dei file.hinclusi dai vari sorgenti;build/, inizialmente vuota, destinata a contenere i moduli finiti;debug/, che contiene alcune estensioni per il debuggergdb;doc/, destinata a contenere la documentazione dei moduli.
Oltre a queste sottodirectory troviamo anche due file:
MakeFile: contiene le istruzioni per il programmamakedel sistema di appoggio.run: uno script che permette di avviare il sistema su unaVM
Il MakeFile può essere utilizzato per generare la documentazione (se sono installati Doxygen, Pandoc e Graphviz) lanciando il comando
make doc
Se ha successo si troverà nell’indice doc/html/index.html.
Per compilare tutti i moduli si utilizza, nella directory nucleo-8.3 il comando make.
Questo comando può prendere alcuni parametri:
make clean # Elimina tutti i file oggetto creati
make reset # Elimina tutti i file oggetto e i moduli creati
2.4.1. Scrittura programmi utente
Si suppone che i moduli sistema e io cambino raramente e costituiscano il sistema vero e proprio, mentre il modulo utente, di volta in volta diverso, rappresenta il programma che l’utente del nostro sistema vuole eseguire.
Per questo motivo la sottodirectory utente contiene solo:
- Alcuni file di supporto (
lib.cpp,lib.heutente.s) - Una sottodirectory
examples/contenente alcuni esempi di possibili programmi utente.
Un esempio minimo può essere il seguente:
#include<all.h>
void main(){
writeconsole("Hello, world!\n", 14);
pause();
// Serve ad evitare che lo shutdown venga eseguito troppo velocemente
terminate_p();
// Necessaria poiché il <main> deve chiedere al sistema di poter terminare
}
Hello, world!
Premere un tasto per continuare
2.4.2. Avvio sistema
Una volta costruiti i moduli possiamo avviare il sistema.
La procedura di boostrap è la stessa di quella già vista, e può essere avviata tramite lo script boot.
I processori intel sono ancora oggi progettati per avviarsi a 16bit in modalità non protetta.
Via software vengono poi portati in modalità protetta a 32bit, in generale grazie ad un programma di bootstrap nel BIOS.
Nel nostro caso sarà l’emulatore stesso ad effettuare questo primo passaggio.
Tocca a noi però portare il processore nella modalità a 64bit, e questo compito lo facciamo svolgere al programma boot.bin che può cedere il controllo al modulo sistema.
Il programma boot.bin esegue una serie di allocazioni in memoria per permettere il corretto funzionamento della nostra macchina.
Una volta avviato vedremo una nuova finestra che rappresenta il video della VM.
Nel terminale dal quale abbiamo lanciato boot vedremo tutta una serie di messaggi, che altro non sono che quelli inviati sulla porta seriale della VM, che adesso andiamo ad analizzare:
Le righe 1-15 arrivano dal programma boot.bin:
- Nelle righe 4–7 il programma
boot.binci informa del fatto che ilbootloaderprecedente (nel nostro casoQEMUstesso) ha caricato in memoria tre file, in particolare il filebuild/sistema.strip4all’indirizzo0x114000. - Nelle righe 8–11 ci informa di come sta copiando le sezioni di questo file nella loro destinazione finale.
- La riga 15 ci avverte infine che
boot.binha finito e sta per saltare all’indirizzo mostrato nella riga 12 (0x200178), dove si trova l’entry point del modulosistema.
I messaggi successivi arrivano dal modulo sistema (con alcuni,
come le righe 45–46, che arrivano dal modulo io).
Nella seconda sezione troviamo in particolare:
- Le righe 19–24 contengono informazioni relative alla memoria virtuale, che per il momento ignoriamo.
- Nelle righe 36-37 vengono creati i primi processi di sistema
- Alla riga 38 vediamo che viene inizializzato l’
APIC. - Nella riga 40 veniamo informati dell’inizializzazione dello heap di sistema (riutilizzando lo spazio occupato da
boot.bin).
Da questo punto in poi l’inizializzazione prosegue nel processo main_sistema (id 1) e main I/O (id 2).
Il processo main_sistema:
- Alla riga 41 attiva il timer
- Alle righe 42-43 crea e attiva il processo
main_io - Le righe 44–53 sono invece relative all’inizializzazione del modulo
io, eseguita da questo processo.
Quando il processo main_io termina, processo main_sistema crea il primo processo utente (righe 54–55) e gli cede il controllo (riga 56), semplicemente terminando (riga 57).
In questo caso il processo utente esegue del codice che verrà eseguito per poi terminare.
Il controllo passa quindi a dummy (id = 0), che si accorge che non ci sono più processi utente e quindi ordina lo shutdown della macchina QEMU (riga 60).
1 | [INF] - Boot loader di Calcolatori Elettronici, v1.0
2 | [INF] - Memoria totale: 32 MiB, heap: 636 KiB
3 | [INF] - Argomenti: /home/gabrieledc/CE/lib/ce/boot.bin
4 | [INF] - Il boot loader precedente ha caricato 3 moduli:
5 | [INF] - - mod[0]: start=114000 end=12f580 file=build/sistema.strip
6 | [INF] - - mod[1]: start=130000 end=1414e0 file=build/io.strip
7 | [INF] - - mod[2]: start=142000 end=147400 file=build/utente.strip
8 | [INF] - Copio mod[0] agli indirizzi specificati nel file ELF:
9 | [INF] - - copiati 108560 byte da 114000 a 200000
10 | [INF] - - copiati 970 byte da 12edb8 a 21bdb8
11 | [INF] - - azzerati ulteriori 79030 byte
12 | [INF] - - entry point 200178
13 | [INF] - Creata finestra sulla memoria centrale: [ 1000, 2000000)
14 | [INF] - Creata finestra per memory-mapped-IO: [ 2000000, 100000000)
15 | [INF] - Attivo la modalita’ a 64 bit e cedo il controllo a mod[0]...
16 | [INF] - Nucleo di Calcolatori Elettronici, v7.1.1
17 | [INF] - Heap del modulo sistema: [1000, a0000)
18 | [INF] - Numero di frame: 560 (M1) 7632 (M2)
19 | [INF] - Suddivisione della memoria virtuale:
20 | [INF] - - sis/cond [ 0, 8000000000)
21 | [INF] - - sis/priv [ 8000000000, 10000000000)
22 | [INF] - - io /cond [ 10000000000, 18000000000)
23 | [INF] - - usr/cond [ffff800000000000, ffffc00000000000)
24 | [INF] - - usr/priv [ffffc00000000000, 0)
25 | [INF] - mappo il modulo I/O:
26 | [INF] - - segmento sistema read-only mappato a [ 10000000000, 1000000f000)
27 | [INF] - - segmento sistema read/write mappato a [ 10000010000, 10000031000)
28 | [INF] - - heap: [ 10000031000, 10000131000)
29 | [INF] - - entry point: start [io.s:11]
30 | [INF] - mappo il modulo utente:
31 | [INF] - - segmento utente read-only mappato a [ffff800000000000, ffff800000005000)
32 | [INF] - - segmento utente read/write mappato a [ffff800000005000, ffff800000007000)
33 | [INF] - - heap: [ffff800000007000, ffff800000107000)
34 | [INF] - - entry point: start [utente.s:10]
35 | [INF] - Frame liberi: 7059 (M2)
36 | [INF] - Creato il processo dummy (id = 0)
37 | [INF] - Creato il processo main_sistema (id = 1)
38 | [INF] - Inizializzo l’APIC
39 | [INF] - Cedo il controllo al processo main sistema...
40 | [INF] 1 Heap del modulo sistema: aggiunto [100000, 200000)
41 | [INF] 1 Attivo il timer (DELAY=59659)
42 | [INF] 1 Creo il processo main I/O
43 | [INF] 1 proc=2 entry=start [io.s:11](1024) prio=1278 liv=0
44 | [INF] 1 Attendo inizializzazione modulo I/O...
45 | [INF] 2 Heap del modulo I/O: 100000B [0x10000031000, 0x10000131000)
46 | [INF] 2 Inizializzo la console (kbd + vid)
47 | [INF] 2 estern=3 entry=estern_kbd(int) [io.cpp:168](0) prio=1104 (tipo=50) liv=0 irq=1
48 | [INF] 2 kbd: tastiera inizializzata
49 | [INF] 2 vid: video inizializzato
50 | [INF] 2 Inizializzo la gestione dell’hard disk
51 | [INF] 2 bm: 00:01.1
52 | [INF] 2 estern=4 entry=estern_hd(int) [io.cpp:509](0) prio=1120 (tipo=60) liv=0 irq=14
53 | [INF] 2 Processo 2 terminato
54 | [INF] 1 Creo il processo main utente
55 | [INF] 1 proc=5 entry=start [utente.s:10](0) prio=1023 liv=3
56 | [INF] 1 Cedo il controllo al processo main utente...
57 | [INF] 1 Processo 1 terminato
58 | [INF] 5 Heap del modulo utente: 100000B [0xffff800000006068, 0xffff800000106068)
59 | [INF] 5 Processo 5 terminato
60 | [INF] 0 Shutdown
Il sistema sul quale lavoriamo è progettato affinché qualsiasi eccezione venga sollevata in modalità utente, resituisce il controllo al modulo sistema, il quale termina forzatamente il processo e invia alcuni messaggi sul log come il seguente:
1 | [WRN] 5 Eccezione 13 (errore di protezione), errore 0, RIP inputb [inputb.s:6]
2 | [WRN] 5 proc 5: corpo start [utente.s:10](0), livello UTENTE, precedenza 1023
3 | [WRN] 5 RIP=inputb [inputb.s:6] CPL=LIV_UTENTE
4 | [WRN] 5 RFLAGS=246 [-- -- -- IF -- -- ZF -- PF --, IOPL=SISTEMA]
5 | [WRN] 5 RAX= fee000b0 RBX= 0 RCX=fffffffffffffe68 RDX= 60
6 | [WRN] 5 RDI= 60 RSI=fffffffffffffe68 RBP=fffffffffffffff0 RSP=ffffffffffffffe8
7 | [WRN] 5 R8 =ffff800000106068 R9 = 0 R10= 0 R11= 0
8 | [WRN] 5 R12= 0 R13= 0 R14= 0 R15= 0
9 | [WRN] 5 backtrace:
10 | [WRN] 5 > main [utente.cpp:5]
11 | [WRN] 5 Processo 5 abortito
Questi messaggi hanno una struttura generalmente simile tra di loro.
Alla riga 1 viene indicata:
- il tipo di eccezione che ha generato lo shutdown del processo
Eccezione 13 (errore di protezione) - Una descrizione dell’errore
errore 0 - L’istruzione che l’ha sollevata
RIP inputb [inputb.b:6]
Nella seconda riga si hanno informazioni riguardanti il processo interrotto e il livello al quale l’eccezione è stata sollevata livello UTENTE, precedenza 1023
Successivamente nelle righe 3-8 è presente un riepilogo dello stato dei registri al momento dell’eccezione, utile per il debug.
Dalla riga 9 fino alla penultima si ha un backtrace delle chiamate che indica come siamo arrivati al file corrrente, in questo caso passando dal main nel file utente.cpp:5
L’ultima riga indica l’esito del processo, nel nostro caso sempre abortito.
Tutte queste informazioni che ci vengono fornite, sono processate dallo script util/show_log.pl a partire dal log inviato dal sistema che contiene solamente indirizzi numerici, usando le informazioni di debug contenute nei file della directory build/.
Nel caso si voglia vedere il contenuto del log non processato si può usare il comando:
CERAW=1 boot
2.4.3. Uso debugger
Anche per quanto riguarda il debug, così come per gli esempiIO, abbiamo la possibilità di collegare il debugger dalla macchina host e osservare tutto quello che accade nel sistema.
La procedura è quella già vista:
- Avviamo la VM tramite
boot -g - Da un altro terminale, ci portiamo nella stessa directory e lanciamo il comando
debug.
In questo caso però lo script, oltre alle estensioni già viste, carica altre estensioni dal file debug/nucleo.py, in modo che il debugger mostri informazioni specifiche sullo stato del nucleo.
In particolare, ogni volta che il debugger riacquisisce il controllo, viene mostrato:
- Lo stack delle chiamate (backtrace);
- Il file sorgente nell’intorno del punto in cui si trova
%rip; - Se il sorgente è
C++, i parametri della funzione in cui ci troviamo e tutte le sue variabili locali; Altrimenti se il file èassemblervengono mostrati i registri e la parte superiore della pila; - Il numero di processi (
utente) esistenti e le listeesecuzioneepronti(ed eventuali altre liste di processi); - Alcuni dettagli sul processo attualmente in esecuzione;
- Lo stato di protezione della CPU.
Oltre ai normali comandi di gdb, sono disponibili altri comandi personalizzati per il nostro nucleo.
Alcuni di quesi comandi sono:
process list: mostra una lista di tutti i processi attivi (utenteosistema);process dump id: mostra il contenuto (della parte superiore) della pila sistema del processoide il contenuto dell’arraycontestodel suo descrittore di processo.
Altri comandi disponibili servono ad esaminare altre strutture dati che per il momento non abbiamo ancora introdotto.
Possiamo notare inoltre che il debugger è preimpostato per caricare i simboli di tutti e tre i moduli.
È quindi possibile inserire breakpoint liberamente nel codice del modulo sistema, utente e io.
3. Descrizione Processi
Abbiamo già detto che il processore utilizza un contesto diverso per l’esecuzione di ogni processo, senza però introdurlo formalmente.
Il contesto non è altro una struttura dati salvata in M2, ed è formato da:
id: descrittore processo- corpo: contenuto dei registri del processore
priorità: indica il livello di priorità del processo
Sappiamo già che il processore lavora per stati. Anche i processi seguono la stessa logica e, durante la loro vita, si trovano costantemente in uno degli stati di esecuzione:
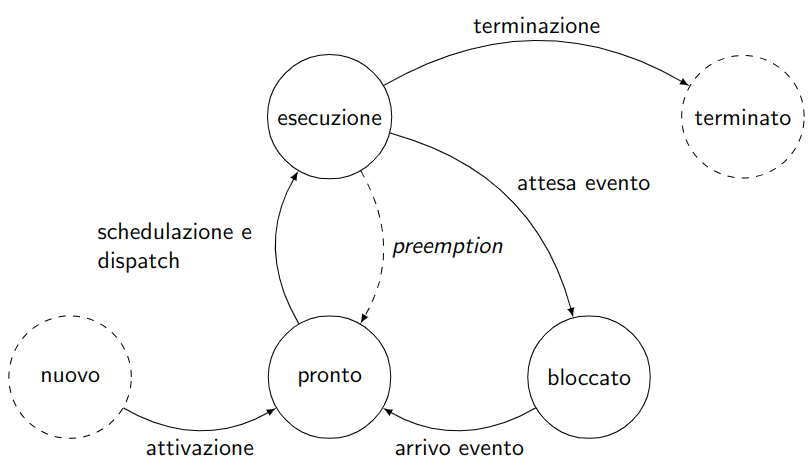
Lo schema di riferimento per gli stati dei processi.
I processi devono essere prima di tutto attivati, in modo che possano cominciare ad essere eseguiti. L’attivazione comporta la creazione di tutte le strutture dati necessarie al corretto funzionamento del processo. Queste strutture comprendono due componenti:
- Descrittore di processo
- Pile
In alcuni sistemi i processi da attivare sono decisi staticamente all’avvio del sistema. Nel sistema che realizzeremo, descriveremo il caso in cui i processi possano essere creati dinamicamente da altri processi (tranne ovviamente il primo processo, che sarà creato dal sistema stesso all’avvio).
Una volta attivato correttamente, il processo si trova quindi nello stato di pronto, nel nostro sistema questa lista è rappresentata dalla lista pronti.
A questo punto, il processore, tramile la schedulazione e il dispatch, porta il processo in esecuzione, nel nostro sistema rappresentata dalla variabile esecuzione.
È importante capire che Schedulazione e Dispatch sono due cose diverse.
La schedulazione si occupa di gestire l’ordine dei processi pronti all’interno della lista, scegliendo quello che andrà in esecuzione.
Nel nostro sistema abbiamo una funzione sistema chiamata schedulatore() che si occupa proprio di selezionare la testa di pronti (costruita in modo da essere ordinata per priorità) e inserirla in esecuzione.
Il dispatch si occupa invece di tutti i passaggi necessari per far cedere il controllo ad un processo ed assegnarlo ad un altro. Nel nostro sistema questa avviene tramite le operazioni di:
CALL carica_stato
IRETQ
Chiamate all’uscita del gate.
Infatti queste fanno adesso riferimento al constesto del processo che si trova in esecuzione, aggiornando quindi i dati all’interno dei registri con quelli del nuovo processo.
Se un processo si trova nello stato di esecuzione, il processore sta eseguendo le sue istruzioni. In questo momento il processo ha il controllo del processore, e può cambiare nel tempo il suo stato. Con un solo processore un solo processo per volta può trovarsi in esecuzione.
Mentre si trova in esecuzione un processo può chiedere di terminare, oppure di sospendersi in attesa di un evento.
Nel primo caso il processo rientra nello stato di terminazione (abbiamo la routine terminate_p() nella nostra macchina).
Nel secondo invece passa allo stato bloccato.
Mentre un processo è bloccato il processore prosegue con un’altro nella coda pronti.
Quando l’evento atteso si verifica il processo torna nello stato di pronto (può anche accadere che vada direttamente in esecuzione, anche se ciò non è mostrato esplicitamente in figura)
Nello schema si trova anche la preemption, che permette ad un processo di passare dall’esecuzione direttamente allo stato pronto.
In questo caso il processo non sta attendendo un evento, non è più in esecuzione soltanto perchè un altro processo, per un motivo o per un altro (ad esempio priorità) sta occupando il processore durante quello che doveva essere il suo tempo. Nei sistemi senza preemption un processo può occupare il processore indefinitamente senza lasciare mai il processore agli altri processi, basta che non chieda mai di terminare, che non generi processi a priorità più elevata o che non vada mai nello stato di bloccato.
Per quanto riguarda lo scheduling esistono diverse strategie da poter seguire, quella vedremo noi è la strategia a priorità fissa. Secondo questa politica, ad ogni processo, al momento della creazione, è assegnata una priorità numerica. Il nostro sistema si impegna quindi a garantire che, in ogni istante, si trovi in esecuzione il processo che ha la massima priorità tra tutti quelli pronti.
Questo ci permette di dover eseguire una azione di schedulazione() solo quando un processo passa da:
- esecuzione $\to$ bloccato: il processore si libera, e dunque dobbiamo mettere in esecuzione il processo a maggiore priorità tra quelli in
pronti - bloccato $\to$ pronto: si genera quando c’è un nuovo processo pronto, che potrebbe avere priorità maggiore di quello attualmente in esecuzione. Per rispettare la regola che abbiamo promesso di garantire potremmo dover fare preemption sul processo in esecuzione.
Dobbiamo inoltre notare che anche quando un processo P1 ne attiva un altro P2 ci troviamo in una situazione simile, in quanto il nuovo processo appena creato viene inserito in pronti, e potrebbe avere priorità superiore a quello in esecuzione.
Quello che ci impegniamo a garantire quindi è che i processi non possano attivarne altri a priorità maggiore della propria. Perciò nel nostro sistema non saranno mai necessarie preemption dopo le creazioni dei processi.
3.1. Transizione Processi
Sottolineamo che l’unico modo per transizionare da un processo ad un altro è tramite un gate della IDT.
Quando si accede ad un gate della IDT (tramite interruzione, eccezione o int), sappiamo che vengono già salvate delle informazioni (5 long word):
- [0] Informazioni per noi non rilevanti
- [1]
RSP: indirizzo della pila al momento del passaggio - [2]
RFLAGS: stato dei flag al momento del passaggio - [3]
CS: livello precedente all’attraversamento del gate - [4]
RIP: istruzione dalla quale ripartire
Perciò tutto quello che dovrà fare il dispatch è salvare il contenuto dei registri tramite la routine invocata:
routine_gate:
CALL salva_stato ; Macro che salva il contenuto di tutti i registri in pila
/*
* corpo routine
*/
CALL carica_stato ; Macro che carica il contenuto di tutti i registri dalla pila
IRETQ
(le informazioni complete su salva_stato e carica_stato si trovano nel file nucleo-8.3/sistema/sistema.s)
Inoltre, per capire a quale processo ci stiamo riferendo quando invochiamo salva_stato e carica_stato utilizziamo come già detto una variabile globale esecuzione.
esecuzione è implementata come un puntatore a descrittore di processo des_proc*:
struct des_proc {
/// identificatore numerico del processo
natw id;
/// livello di privilegio (LIV_UTENTE o LIV_SISTEMA)
natw livello;
/// precedenza nelle code dei processi
natl precedenza;
/// indirizzo della base della pila sistema
vaddr punt_nucleo;
/// copia dei registri generali del processore
natq contesto[N_REG];
/// radice del TRIE del processo (vedere la parte sulla memoria virtuale)
paddr cr3;
/// prossimo processo in coda
des_proc* puntatore;
/// parametro `f` passato alla `activate_p`/`_pe` che ha creato questo processo
void (*corpo)(natq);
/// parametro `a` passato alla `activate_p`/`_pe` che ha creato questo processo
natq parametro;
/// @}
};
Lo scheduler, che invece identifica e ordina i processi pronti, utilizza un’altra variable globale pronti che punta ad una lista dove si trovano i vari processi nello stato di pronto.
Poiché la nostra politica è quella di eseguire i processi a priorità maggiore, quando inseriamo i processi in questa lista, lo facciamo in ordine di priorità, cosicché il prossimo processo da eseguire sarà sempre quello in cima alla lista.
Per quanto riguarda la gestione dello stato bloccato vedremo che sarà necessario considerare ogni azione di bloccaggio in maniera diversa.
Le varie operazioni eseguite nel modulo sistema (come questa routine stessa), sono indipendenti dai processi, che si trovano come congelati durante questo frangente.
(finché la prima cosa nella routine che facciamo è salvarne lo stato, e l’ultima cosa è caricarlo)
Quando entriamo nel gate da un processo P1 salviamo, tra le varie informazioni, l’indirizzo della pila utilizzata dal processo, nella sezione rsp della pila di sistema di P1.
Facciamo ciò perché il registro rsp del processo in questo istante punta proprio alla pila di sistema di P1.
Quando eseguiamo quindi la salva_stato, il registro rsp punta proprio la pila di sistema P1 salvata dall’entrata al gate.
Ciò significa che, carica_stato ripristinerà la pila di sistema del processo P2, e la successiva IRETQ ripristinerà proprio le istruzioni relative a quel processo, reinserendo il valore della pila di stack di P2.
Tutto il necessario per cambiare processo è quindi cambiare la variabile esecuzione all’interno del corpo della routine.
Quando viene selezionato il prossimo processo però può avvenire che ci sia un solo processo in esecuzione e che questo vada in blocco.
In questo caso la coda pronti è vuota, e dovremmo gestire il nostro processore in maniera che faccia comunque qualcosa in attesa il processo in blocco torni in pronti.
La strategia che adottiamo è quella di inserire un processo dummy con priorità più bassa di tutte (0), sempre presente in coda.
Questo processo consiste in nient’altro che un in un ciclo infinito, che ha come obiettivo quello di attendere semplicemente che arrivi un nuovo processo significativo nello stato di pronto.
3.2. Creazione nuovo Processo
Quando viene creato un processo (activate_p(f, a, prec, livello)), dobbiamo fare in modo che, quando questo venga selezionato per andare in escuzione lo faccia eseguendo la funzione f(a).
Alla creazione del processo la activate_p(), oltre ad inserire un puntatore al processo in una nuova riga della proc_table, ne alloca tutte le strutture dati nella porzione M1 della memoria:
- Descrittore di processo (
desc_proc) - Pila Sistema
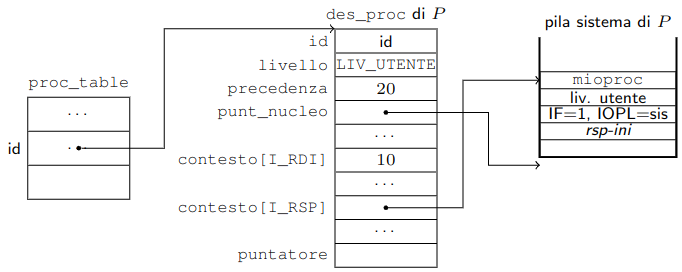
desc_proc
-
id: codice identificativo nellaproc_tabledel processo -
livello:LIV_UTENTEper tutti i processi che vogliamo possano essere chiamati ed eseguiti dall’utente. -
precedenza: valore diprecpassato daactivate_p() -
punt_nucleo: punta alla base pila di sistema, come se fosse vuota. Questo è necessario per gestire opportunamente le interruzioni quando il processo sarà in operazione a livelloutente. Infatti, in questo caso, la sia pila sistema è sempre vuota. -
contesto: contiene il valore dei registri al momento della creazione del processo, quindi sono tutti vuoti, ad eccezione di:-
contesto[I_RDI]: parametroapassato daactivate_p() -
contesto[I_RSI]: indirizzo della pila sistema
-
Pila Sistema
-
RIP: funzionefpassata daacrivate_p() -
CS: livello di chi è entrato nel gate (solitamenteLIV_UTENTE) -
RFLAG: Registro dei flag completamente resettato, tranne per quanto riguarda due flag:-
IF = 1: per permettere le interruzioni durante l’esecuzione della routine -
IOPL = sis, setta la priorità di sistema alle perifericheIOper vietare l’utilizzo di istruzioni qualiIN,OUT. Inoltre modifica il livello di privilegio per bloccare anche le istruzioniSTIeCLI
-
-
RSP:rsp-ini, vedremo più avanti in cosa consiste
(quando si modifica RFLAG tramite POPF i flag IF e IOPL non vengono modificati)
Il codice che gestisce tutto questo nella nostra macchina QEMU si trova nei file sistema.cpp e sistema.s nella directory nucleo-8.3/sistema/.