1. Indice
2. La Memoria Virtuale
Abbiamo definito la memoria virtuale, adesso è il momento di implementarla.
Nel nostro calcolatore realizzeremo un caso ibrido rispetto alla visibilità della memora: i processi avranno sia zone di memoria condivise tra tutti, sia zone di memoria private per ciascuno.
Tutti i processi utente avranno caricato nella propria memoria virtuale un unico programma: quello contenuto nel modulo utente.
La memoria virtuale di ogni processo sarà quindi organizzata come nell’immagine a destra.
La memoria virtuale di un processo è divisa in due macrozone: utente e sistema, sfruttando la naturale divisione dovuta alla normalizzazione degli indirizzi.
La parte che va dall’indirizzo 0x0000 0000 0000 0000 all’indirizzo 0x0000 7fff ffff ffff è deditata al sistema, ed ha quindi settato il bit U/S = 0, mentre la parte che va da 0xffff 8000 0000 0000 a 0xffff ffff ffff ffff è dedicata all’utente, ed ha quindi settato il bit U/S = 1.
Inoltre gli indirizzi virtuali della prima pagina (0 a 0xfff) sono lasciati non mappati, per intercettare dereferenzazioni di nullptr indipendentemente dal livello del privilegio del processore.
Ogni macro-zona è ulteriormente divisa.
La sezione sistema è divisa in:
- Memoria
sistemacondivisa: la sua dimensione è decisa a priori, e dipende dalla memoria fisica installata (per via della finestra). Contiene la finestra sulla memoria fisica, le variabili/strutture dati sistema globali e il codice del modulosistema. - Memoria
sistemaprivata: contiene la pila sistema del processo. - Memoria
I/Ocondivisa: contiene il moduloI/O, ovvero le sezioni.texte.dataestratte dal filebuild/ioe mappate al loro indirizzo di collegamento. Contiene anche lo heap I/O, utilizzato dagli operatori dinewedeletenel moduloI/O.
La sezione utente è divisa invece in:
- Memoria
utentecondivisa: contiene le sezioni.text,.dataestratte dabuild/utente. Contiene inoltre anche lo heap utente, utilizzato dagli operatori dinewedeletenel moduloutente. - Memoria
utenteprivata: contiene la pila utente del processo.
La RAM è divisa in frame, che sono rappresentati da una pila. Ciò ci è comodo per la sua gestione, in quanto se necessitiamo di un nuovo frame è sufficente estrarre il primo libero.
Alla pila è associato un array (des_frame vdf[N_FRAME]), che contiene un elemento per ogni frame.
In questo array troviamo il numero di indirizzi validi in un determinato frame.
In questo modo siamo in grado di capire quando un frame è pieno o quando è vuoto.
La memoria fisica è suddivisa al solito in una parte M1 e una parte M2.
La parte M1 della memoria fisica è così organizzata:
- I primi due
MiBcontengolo lo heap di sistema: è una zona di memoria in cui le primitive allocano ides_proc, le strutturerichiestae in generale qualunque struttura dati allocata dinamicamente tramitenewedelete. Quando il modulosistemaparte, il bootloader ha già usato parte dello heap sistema per allocare alcune strutture dati, come le tabelle di traduzioni per la finestra e il segmentoTSS. - La parte dedicata al
modulo sistemacontiene le sezioni.texte.dataestratte dal filebuild/sistemae caricate al loro indirizzo di collegamento.
Dal simbolo end definito nel modulo sistema, otterremo l’inizio della parte M2.
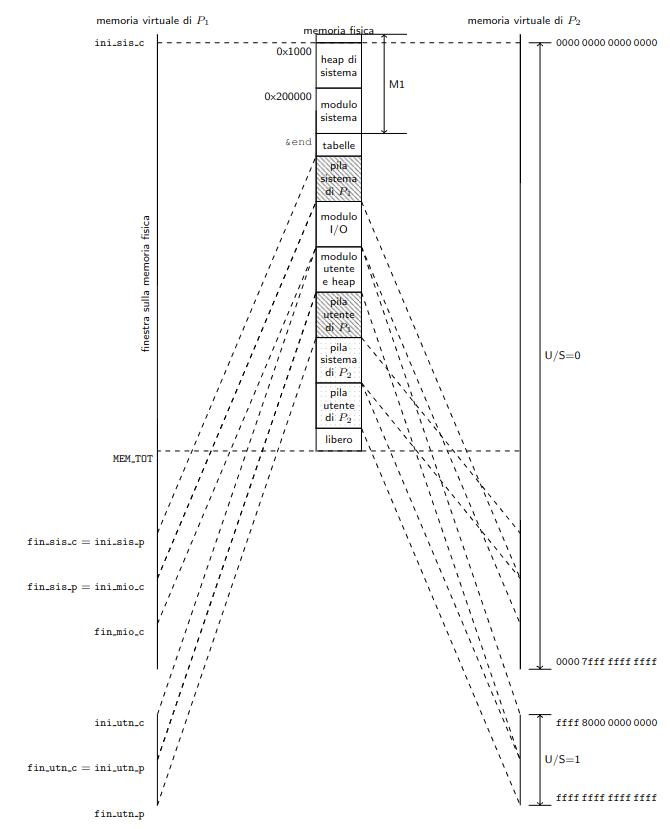
Indirizzamento virtuale di due processi P1 e P2.
Il nome delle costanti ha tre parti:
La stringa ini per l’inizio o fin per la fine
La stringa sis per le sezioni sistema, mio per la sezione modulo I/O e utn per le sezioni utente
Il carattere c per le sezioni condivise o p per quelle private.
3. Implementazione
Vediamo adesso le strutture dati e le funzioni relative all’implementazione della memoria virtuale.
La suddivisione dello spazio di indirizzamento dei processi e delle sue varie parti è stabilita da costanti definite in costanti.h.
Per semplicità le varie parti occupano ciascuna un numero intero di regioni di livello massimo, ovvero 512 GiB (trie a 4 livelli).
//costanti.h
///< prima entrata sistema/condivisa
#define I_SIS_C 0
///< prima entrata sistema/privata
#define I_SIS_P 1
///< prima entrata modulo IO/condivisa
#define I_MIO_C 2
///< prima entrata utente/condivisa
#define I_UTN_C 256
///< prima entrata utente/privata
#define I_UTN_P 384
///< numero entrate sistema/condivisa
#define N_SIS_C 1
///< numero entrate sistema/privata
#define N_SIS_P 1
///< numero entrate modulo IO/condivisa
#define N_MIO_C 1
///< numero entrate utente/convidisa
#define N_UTN_C 128
///< numero entrate utente/privata
#define N_UTN_P 128
// sistema.cpp
static const natq PART_SIZE = dim_region(MAX_LIV - 1);
///< base di sistema/condivisa
const vaddr ini_sis_c = norm(I_SIS_C * PART_SIZE);
///< base di sistema/privata
const vaddr ini_sis_p = norm(I_SIS_P * PART_SIZE);
///< base di modulo IO/condivisa
const vaddr ini_mio_c = norm(I_MIO_C * PART_SIZE);
///< base di utente/condivisa
const vaddr ini_utn_c = norm(I_UTN_C * PART_SIZE);
///< base di utente/privata
const vaddr ini_utn_p = norm(I_UTN_P * PART_SIZE);
///< limite di sistema/condivisa
const vaddr fin_sis_c = ini_sis_c + PART_SIZE * N_SIS_C;
///< limite di sistema/privata
const vaddr fin_sis_p = ini_sis_p + PART_SIZE * N_SIS_P;
///< limite di modulo IO/condivisa
const vaddr fin_mio_c = ini_mio_c + PART_SIZE * N_MIO_C;
///< limite di utente/condivisa
const vaddr fin_utn_c = ini_utn_c + PART_SIZE * N_UTN_C;
///< limite di utente/privata
const vaddr fin_utn_p = ini_utn_p + PART_SIZE * N_UTN_P;
Per tener traccia delle informazioni necessarie per ogni frame si utilizza la struttura des_frame:
// sistema.cpp
struct des_frame {
union {
/// numero di entrate valide (se il frame contiene una tabella)
natw nvalide;
/// prossimo frame libero (se il frame è libero)
natl prossimo_libero;
};
};
/// Numero totale di frame (M1 + M2)
natq const N_FRAME = MEM_TOT / DIM_PAGINA;
/// Array dei descrittori di frame
des_frame vdf[N_FRAME];
/// Numero di frame in M1
natq N_M1;
/// Numero di frame in M2
natq N_M2;
/// Testa della lista dei frame liberi
natq primo_frame_libero;
/// Numero di frame nella lista dei frame liberi
natq num_frame_liberi;
Tramite questa struttura siamo in grado di capire se un frame è libero o meno, ed eventualmente quale sarà il prossimo frame libero in lista.
I descrittori di frame sono raccolti in vdf[], indicizzato proprio dal numero di frame.
La funzione init_frame(), chiamata in fase di inizializzazione, si occupa prorpio di inizializzare questo array inserendo tutti i frame di M2 nella lista dei frame liberi.
void init_frame(){
extern char _end[];
// Tutta la memoria non ancora occupata viene usata per i frame.
// La funzione si preoccupa anche di inizializzare i descrittori dei frame
// in modo da creare la lista dei frame liberi.
// end è l'indirizzo del primo byte non occupato dal modulo sistema
// (è calcolato dal collegatore).
// La parte M2 della memoria fisica inizia al primo frame dopo end.
// primo frame di M2
paddr fine_M1 = allinea(int_cast<paddr>(_end), DIM_PAGINA);
// numero di frame in M1 e indice di f in vdf
N_M1 = fine_M1 / DIM_PAGINA;
// numero di frame in M2
N_M2 = N_FRAME - N_M1;
if (!N_M2)
return;
// creiamo la lista dei frame liberi, che inizialmente contiene tutti i
// frame di M2
primo_frame_libero = N_M1;
/// @cond
#ifndef N_STEP
// Alcuni esercizi definiscono N_STEP == 2 per creare mapping non
// contigui in memoria virtale e controllare meglio alcuni possibili
// bug
#define N_STEP 1
#endif
/// @endcond
natq last = 0;
for (natq j = 0; j < N_STEP; j++) {
for (natq i = j; i < N_M2; i += N_STEP) {
vdf[primo_frame_libero + i].prossimo_libero =
primo_frame_libero + i + N_STEP;
num_frame_liberi++;
last = i;
}
vdf[primo_frame_libero + last].prossimo_libero =
primo_frame_libero + j + 1;
}
vdf[primo_frame_libero + last].prossimo_libero = 0;
}
Da questo punto in poi è possibile allocare e deallocare frame utilizzando le funzioni alloca_frame() e rilascia_frame(p).
/*! @brief Estrae un frame dalla lista dei frame liberi.
* @return indirizzo fisico del frame estratto, o 0 se la lista è vuota
*/
paddr alloca_frame(){
if (!num_frame_liberi) {
flog(LOG_ERR, "out of memory");
return 0;
}
natq j = primo_frame_libero;
primo_frame_libero = vdf[primo_frame_libero].prossimo_libero;
vdf[j].prossimo_libero = 0;
num_frame_liberi--;
return j * DIM_PAGINA;
}
/*! @brief Restiuisce un frame alla lista dei frame liberi.
* @param f indirizzo fisico del frame da restituire
*/
void rilascia_frame(paddr f){
natq j = f / DIM_PAGINA;
if (j < N_M1) {
fpanic("tentativo di rilasciare il frame %lx di M1", f);
}
// dal momento che i frame di M2 sono tutti equivalenti, è
// sufficiente inserire in testa
vdf[j].prossimo_libero = primo_frame_libero;
primo_frame_libero = j;
num_frame_liberi++;
}
Le funzioni di utilità inc_ref(), dec_ref() e get_ref() servono a manipolare il contatore nvalide di una tabella di cui conosciamo l’indirizzo fisico.
void inc_ref(paddr f){
vdf[f / DIM_PAGINA].nvalide++;
}
void dec_ref(paddr f){
vdf[f / DIM_PAGINA].nvalide--;
}
natl get_ref(paddr f){
return vdf[f / DIM_PAGINA].nvalide;
}
Nel modulo sono anche ridefinite le funzioni alloca_tab() e rilascia_tab() della libce, in modo che la tabella venga allocata/deallocata dalla lista dei frame liberi di M2, invece che dallo heap sistema.
paddr alloca_tab(){
paddr f = alloca_frame();
if (f) {
memset(voidptr_cast(f), 0, DIM_PAGINA);
vdf[f / DIM_PAGINA].nvalide = 0;
}
return f;
}
void rilascia_tab(paddr f){
if (int n = get_ref(f)) {
fpanic("tentativo di deallocare la tabella %lx con %d entrate valide", f, n);
}
rilascia_frame(f);
}
Le traduzioni relative alle parti condivise dei processi possono invece essere create una sola volta all’avvio del sistema. I processi possono infatti condividere tutto il sottoalbero che implementa queste traduzioni, a partire dal livello inferiore a quello della radice. Per esempio possiamo creare la traduzione della finestra sulla memoria una sola volta. Tutte le entrate di indice 0 delle tabelle di tutti i processi punteranno poi alla stessa tabella di livello inferiore, e dunque tutto il sottoalbero sarà condiviso tra tutti i processi, risparmiando molto spazio e tempo ad ogni creazione di un nuovo processo.
Le traduzioni della parte sistema/condivisa sono create dal bootloader prima di abilitare la paginazione tramite la funzione crea_finestra_FM().
bool crea_finestra_FM(paddr root_tab, paddr mem_tot){
auto identity_map = [] (vaddr v) -> paddr { return v; };
/// mappiamo tutta la memoria fisica:
/// - a livello sistema (bit U/S non settato)
/// - scrivibile (bit R/W settato)
/// - con pagine di grandi dimensioni (bit PS)
/// (usiamo pagine di livello 2 che sono sicuramente disponibili)
/// @note vogliamo saltare la prima pagina per intercettare *nullptr, e inoltre
/// vogliamo settare il bit PWT per le pagine che contengono la memoria video.
/// Per farlo dobbiamo rinunciare a settare PS per la prima regione
natq first_reg = dim_region(1);
// [0, DIM_PAGINA): non mappato
// [DIM_PAGINA, 0xa0000): memoria normale
if (map(root_tab, DIM_PAGINA, 0xa0000, BIT_RW, identity_map) != 0xa0000)
return false;
// [0xa0000, 0xc0000): memoria video
if (map(root_tab, 0xa0000, 0xc0000, BIT_RW|BIT_PWT, identity_map) != 0xc0000)
return false;
// [0xc0000, first_reg): memoria normale
if (map(root_tab, 0xc0000, first_reg, BIT_RW, identity_map) != first_reg)
return false;
// mappiamo il resto della memoria con PS settato
if (mem_tot > first_reg) {
// utilizziamo pagine da 2MiB invece che da 4KiB
// è settato il BIT_RW
if (map(root_tab, first_reg, mem_tot, BIT_RW, identity_map, 2) != mem_tot)
return false;
}
flog(LOG_INFO, "Creata finestra sulla memoria centrale: [%16llx, %16llx)", DIM_PAGINA, mem_tot);
/// Mappiamo tutti gli altri indirizzi, fino a 4GiB, settando sia PWT che PCD.
/// Questa zona di indirizzi è utilizzata in particolare dall'APIC per mappare i propri registri.
/// Proprio per questo sono settati i bit PCD e PWT
vaddr beg_pci = allinea(mem_tot, 2*MiB);
vaddr end_pci = 4*GiB;
if (map(root_tab, beg_pci, end_pci, BIT_RW|BIT_PCD|BIT_PWT, identity_map, 2) != end_pci)
return false;
flog(LOG_INFO, "Creata finestra per memory-mapped-IO: [%16llx, %16llx)", beg_pci, end_pci);
return true;
}
Il bootloader mappa così in se stessi tutti gli indirizzi da DIM_PAGINA a MEM_TOT, in modo da creare la finestra sulla memoria fisica, lasciando non mappata la prima pagina (dereferenziazioni di nullptr).
La creazione dei processi si trova nella funzione crea_processo():
des_proc* crea_processo(void f(natq), natq a, int prio, char liv){
des_proc* p; // des_proc per il nuovo processo
paddr pila_sistema; // pila_sistema del processo
natq* pl; // pila sistema come array di natq
natl id; // id del nuovo processo
// allocazione (e azzeramento preventivo) di un des_proc
p = new des_proc;
if (!p)
goto err_out;
memset(p, 0, sizeof(des_proc));
// riempiamo i campi di cui conosciamo già i valori
p->precedenza = prio;
p->puntatore = nullptr;
// il registro RDI deve contenere il parametro da passare alla
// funzione f
p->contesto[I_RDI] = a;
// selezione di un identificatore
id = alloca_proc_id(p);
if (id == 0xFFFFFFFF)
goto err_del_p;
p->id = id;
// creazione della tabella radice del processo
p->cr3 = alloca_tab();
if (p->cr3 == 0)
goto err_rel_id;
init_root_tab(p->cr3);
// creazione della pila sistema
static_assert(DIM_SYS_STACK > 0 && (DIM_SYS_STACK & 0xFFF) == 0);
if (!crea_pila(p->cr3, fin_sis_p, DIM_SYS_STACK, LIV_SISTEMA))
goto err_rel_tab;
// otteniamo così un puntatore al fondo della pila appena creata.
// Si noti che non possiamo accedervi tramite l'indirizzo virtuale 'fin_sis_p',
// che verrebbe tradotto seguendo l'albero del processo corrente, e non
// di quello che stiamo creando.
// Per questo motivo usiamo trasforma(), per ottenere il corrispondente indirizzo fisico.
// In questo modo accediamo alla nuova pila tramite la finestra FM.
//
// Si noti anche che dobbiamo sottrarre almeno 1 a fin_sis_p prima di tradurre,
// perché fin_sis_p stesso è fuori dalla parte sistema/privata.
pila_sistema = trasforma(p->cr3, fin_sis_p - 1) + 1;
// convertiamo a puntatore a natq, per accedervi più comodamente
pl = ptr_cast<natq>(pila_sistema);
if (liv == LIV_UTENTE) {
// inizializziamo la pila sistema.
pl[-5] = int_cast<natq>(f); // RIP (codice utente)
pl[-4] = SEL_CODICE_UTENTE; // CS (codice utente)
pl[-3] = BIT_IF; // RFLAGS
pl[-2] = fin_utn_p - sizeof(natq); // RSP
pl[-1] = SEL_DATI_UTENTE; // SS (pila utente)
// eseguendo una IRET da questa situazione, il processo
// passerà ad eseguire la prima istruzione della funzione f,
// usando come pila la pila utente (al suo indirizzo virtuale)
// creazione della pila utente
static_assert(DIM_USR_STACK > 0 && (DIM_USR_STACK & 0xFFF) == 0);
if (!crea_pila(p->cr3, fin_utn_p, DIM_USR_STACK, LIV_UTENTE)) {
flog(LOG_WARN, "crea_processo: creazione pila utente fallita");
goto err_del_sstack;
}
// inizialmente, il processo si trova a livello sistema, come
// se avesse eseguito una istruzione INT, con la pila sistema
// che contiene le 5 parole quadruple preparate precedentemente
p->contesto[I_RSP] = fin_sis_p - 5 * sizeof(natq);
p->livello = LIV_UTENTE;
// dal momento che usiamo traduzioni diverse per le parti sistema/private
// di tutti i processi, possiamo inizializzare p->punt_nucleo con un
// indirizzo (virtuale) uguale per tutti i processi
p->punt_nucleo = fin_sis_p;
// tutti gli altri campi valgono 0
}
else {
// processo di livello sistema
// inizializzazione della pila sistema
pl[-6] = int_cast<natq>(f); // RIP (codice sistema)
pl[-5] = SEL_CODICE_SISTEMA; // CS (codice sistema)
pl[-4] = BIT_IF; // RFLAGS (abilitiamo le interruzioni)
pl[-3] = fin_sis_p - sizeof(natq); // RSP (primo elemento della pila)
pl[-2] = 0; // SS
pl[-1] = 0; // ind. rit.
//(non significativo)
// i processi esterni lavorano esclusivamente a livello
// sistema. Per questo motivo, prepariamo una sola pila (la
// pila sistema)
// inizializziamo il descrittore di processo
p->contesto[I_RSP] = fin_sis_p - 6 * sizeof(natq);
p->livello = LIV_SISTEMA;
// tutti gli altri campi valgono 0
}
// informazioni di debug
p->corpo = f;
p->parametro = a;
return p;
err_del_sstack: distruggi_pila(p->cr3, fin_sis_p, DIM_SYS_STACK);
err_rel_tab: clear_root_tab(p->cr3);
rilascia_tab(p->cr3);
err_rel_id: rilascia_proc_id(p->id);
err_del_p: delete p;
err_out: return nullptr;
}
Per gestire correttamente l’allocazione e la deallocazione delle tabelle, occorre fare attenzione al contatore delle entrate libere, che va aggiornato ogni volta che cambia un bit P all’interno di una tabella.
Il modo più semplice per farlo e utilizzare le seguenti funzioni:
-
paddr alloca_tab(): (ridefinita) alloca un frame destinato a contenere una tabella. Rispetto ad una semplicealloca_frame()provvede anche ad azzerare sia il frame, sia il contatorenvalidenel suo descrittore; -
void rilascia_tab(): (ridefinita) rilascia un frame che conteneva una tabella. Rispetto ad una semplicerilascia_frame(), controlla anche che il contatorenvalidenon sia diverso da zero, in modo da intercettare errori di programmazione in cui si tenta di rilasciare tabelle che ancora contengono entrate valide; void set_entry(paddr tab, natl j, tab_entry se): fa il contrario dellaget_entry(), settando l’entrataj-esima della tabella di indirizzo fisicotabcon il nuovo valorese. Si preoccupa inoltre di aggiornare opportunamente il contatorenvalidese il valore del bitPcambia per effetto dell’assegnamento;void set_entry(paddr tab, natl j, tab_entry se){ tab_entry& de = get_entry(tab, j); // il contatore deve essere aggiustato se il bit P cambia valore if ((se & BIT_P) && !(de & BIT_P)) { inc_ref(tab); } else if (!(se & BIT_P) && (de & BIT_P)) { dec_ref(tab); } de = se; }void copy_des(paddr src, paddr dst, natl i, natl n): copianentrate a partire dallai-esima della tabella di indirizzo fisicosrcnelle corrispondenti entrate della tabelle di indirizzo fisicodst. Si preoccupa inoltre di aggiornare opportunamente il contatorenvalidedella tabelladst. Questa funzione è utile quando si crea un nuovo processo e si devono copiare le entrate delle parti condivise dalla tabella radice del processo genitore;void copy_des(paddr src, paddr dst, natl i, natl n){ for (natl j = i; j < i + n && j < 512; j++) { tab_entry se = get_entry(src, j); set_entry(dst, j, se); } }void set_des(paddr dst, natl i, natl n, tab_entry e): settanentrate a partire dallai-esima della tabella di indirizzo fisicodst, impostandole tutte uguali ae, aggiornando opportunamente il contatorenvalide. Questa funzione è utile soprattutto quandoe == 0perché si sta distruggendo un albero di traduzione. (terminazione di processi)void set_des(paddr dst, natl i, natl n, tab_entry e){ for (natl j = i; j < i + n && j < 512; j++) { set_entry(dst, j, e); } }
La paginazione viene effettivamente attivata dalla funzione attiva_paginazione(info, entry_point, MAX_LIV), contenuta nel file boot.s, in particolare nella sezione:
; ...
; settiamo il bit 31 di CR0
MOVl %cr0, %eax
ORl $0x80010000, %eax // paging & write-protect
MOVl %eax, %cr0
; ora la modalità a 64 bit è attiva ...