1. Indice
2. Driver I/O
Aver implementato la Protezione implica adesso che se un processo vuole fare un’operazione di I/O, non può parlare direttamente con le periferiche (tastiera, video, …).
L’unica possibilità che gli abbiamo lasciato è quella di usare una primitiva, nella nostra macchina ad esempio abbiamo readconsole() e writeconsole().
La struttura generale delle primitive di I/O che il sistema deve fornire è la seguente:
// Lettura di quanti byte in un buffer, nella periferica id
extern "C" void read_n(natl id, char* buf, natq quanti);
// Scrittura di quanti byte in un buffer, nella periferica id
extern "C" void write_n(natl id, const char* buf, natq quanti);
La primitiva cede quindi il controllo al sistema e avvia l’operazione, rendendo P1 bloccato e schedulando un nuovo processo indipendente P2.
P1 non sa di questo passaggio, e non deve farlo. Dobbiamo quindi fargli credere che tutto sia stato eseguito come una semplice chiamata a funzione.
Sarà quindi necessario “sbloccare” il processo P1, ovvero riportarlo in coda pronti, solo quando l’operazione di I/O sarà terminata.
Tuttavia il completamento dell’operazione del processo P1 avviene mentre esso è sospeso, e in esecuzione vi è un altro processo P2 generalmente scorrelato.
Per poter fare questo il sistema deve gestire la corsa attraverso le interruzioni.
Sarà quindi necessario programmare la tastiera in modo che generi questi segnali, così da riaffidare il controllo al sistema per una corretta gestione.
Il sistema, poiché è stato scritto da qualche parte nella memoria globale, non solo conosce la sorgente dell’interruzione, ma sa anche a quale processo è riferita.
Quando questo segnale viene quindi generato, si andrà a riempire il buffer dell’esito indicato dal processo P1.
Solo quando il buffer sarà stato riempito, dopo quanti byte, allora P1 ritornerà nello stato pronto.
A questo punto dobbiamo quindi “solamente” capire come gestire questi aggiornamenti del buffer del processo in attesa.
La gestione di questo compito è affidata ai driver, funzioni esterne delle periferiche, associate ad una data operazione.
L’operazione nel suo complesso ha quindi due attori:
- La primitiva ha lo scopo di avviare l’operazione di
I/Oe bloccare il processo, garantendo la mutua esclusione - Il driver ha il compito di trasferire effettivamente i byte e sbloccare il processo quando l’operazione si è conclusa.
2.1. Gestione Primitiva
Finché abbiamo in esecuzione un solo processo nel nostro calcolatore non subentrano problemi. Quando vi sono però più processi in attesa degli stessi segnali cominciano a crearsi situazioni da gestire opportunamente.
Nel nostro esempio sopra immaginiamo quindi che anche P2 ad un certo punto voglia effettuare la stessa operazione di I/O di P1, accodandosi.
Questa concorrenza genera problemi di mutua esclusione oltre che di sincronizzazione.
Per gestirli una prima idea potrebbe essere quella di utilizzare i semafori.
Questi ci permetterebbero infatti di:
- Gestire le code di processi in attesa dello stesso evento. (Mutua esclusione)
- Risvegliare il processo nel momento corretto.
Tuttavia l’utilizzo dei semafori nel contesto sistema comporta delle problematiche, due in particolare:
- Non vorremmo utilizzare la
intin modalità sistema (vincolo facilmente “bypassabile” chiamando direttamente le primitivec_sem_wait,c_sem_iniec_sem_signal). - Fatto più importante, la primitiva deve essere atomica, quindi non dovrebbe effettuare
salva_statoecarica_statoall’entrata e all’uscita del sistema.
Il motivo per il quale richiediamo l’atomiticità è per via delle modifiche alle strutture dati condivise, così da garantirne la mutua esclusione, in particolare alle code processi.
Consideriamo però il fatto che accediamo alla coda processi solamente attraverso le funzioni sem_wait() e sem_signal(), ovverto tramite funzioni atomiche.
Quindi, finché non accediamo a nessuna struttura dati condivisa e ci concediamo l’utilizzo della int almeno in questo caso, possiamo permetterci di non avere atomicità nella c_read_n e nella c_write_n, utilizzando quindi i semafori.
Tuttavia il passaggio dal gate nella chiamata a a_read_n e successivamente nelle sem_wait e sem_signal effettuano sovrascritture dello stato, poiché salva_stato viene chiamata più volte di fila per lo stesso processo.
Per risolvere questo problema è sufficiente rimuovere la salva_stato e la carica_stato nell’a_read_n.
È qundi come se questa primitiva girasse mentre P1 è ancora in esecuzione, a differenza delle primitive viste fin’ora che giravano con i processi “messi in pausa”.
La read_n è quindi così implementata:
; Utente.s
.global
read_n:
int $IO_TIPO_RN
ret
; Sistema.s
.global a_read_n
.extern c_read_n
a_read_n:
call c_read_n
iretq
extern "C" void c_read_n(natl id, char* buf, natq quanti){
// ....
sem_wait(mutex);
// ....
sem_wait(sync);
sem_signal(mutex);
// ....
}
Dichiariamo quindi una struttura che ci permetta di conservare informazioni sui dati:
struct des_io{
ioaddr iRBR, iCTL;
char* buf;
natq quanti;
natl mutex;
natl sync;
};
È quindi sufficiente avere un array di tali descrittori array_des_io e usare il campo id come indice degli elementi al suo interno.
La c_read_n sarà quindi così strutturata:
extern "C" void c_read_n(natl id, natb *buf, natl quanti){
/// Controllo sui parametri omesso, vedere dopo
des_io *d = &array_des_io[id];
sem_wait(d->mutex); /// Garantisco la mutua esclusione
/// Trasferisco le informazioni al descrittore
d->buf = buf;
d->quanti = quanti;
/// Abilito le interruzioni.
/// Si suppone che sia sufficente settare CTL a 1
outputb(1, d->iCTL);
/// Blocco il processo sul semaforo di sincronizzazione
sem_wait(d->sync);
sem_signal(d->mutex); /// Garantisco la mutua esclusione
}
2.2. Gestione Driver
Il driver andrà in esecuzione per effetto di una richiesta di interruzione da parte dell’interfaccia, arrivata alla CPU attraverso l’APIC.
Per gestire i gate dei driver quello che facciamo è creare per ognuno un diverso gate di nome a_driver_i, dove i è un numero progressivo che rappresenta quello che nel .cpp chiamiamo id.
In questo modo ogni driver, pur eseguendo la stessa funzione c_driver, avrà come argomento l’id del driver:
.extern c_driver
a_driver_i:
CALL salva_stato
MOVq $i, %rdi
CALL c_driver
CALL apic_send_EOI
CALL carica_stato
IRETQ
Il driver non ha però un suo descrittore di processo, poiché utilizza le risorse del generico processo in esecuzione in quel momento.
Se quindi gli facessimo utilizzare sem_wait() e sem_signal(), la salva_stato e la carica_stato interne ad essi avrebbero effetti sul generico processo attualmente in esecuzione, sovrascrivendone il contesto.
Potremmo bypassare il problema chiamando direttamente c_sem_signal, tuttavia, per come l’abbiamo strutturata, la funzione verifica il livello del chiamate tramite la funzione sem_valido().
Quest’ultima funzione utilizza liv_chiamante() che recupera il livello leggendolo dalla pila, restituendo quindi quello del generico processo P2 interrotto dal driver, potenzialmente eseguendo codice di un altro livello.
Qui il codice:
int liv_chiamante(){
natq* pila = ptr_cast<natq>(esecuzione->contesto[I_RSP]);
return pila[1] == SEL_CODICE_SISTEMA ? LIV_SISTEMA : LIV_UTENTE;
}
// ...
bool csem_valido(natl sem){
int liv = liv_chiamante();
// ...
}
// ...
extern "C" void c_sem_signal(natl sem){
// una primitiva non deve mai fidarsi dei parametri
if (!sem_valido(sem)) {
// ...
}
// ...
}
Una possibile soluzione quindi è quella di eseguire il driver con interruzioni disabilitate (IF = 0).
Questa scelta, per quanto funzionale, ci impedisce però di gestire le interruzioni a priorità, poiché, finché un driver è in esecuzione, tutte le altre interruzioni sono ignorate.
Le scelte adoperate fin’ora per primitiva e driver comportano quindi due scomodità con le quali dovremo convivere:
- Nella primitiva dobbiamo stare attenti a non toccare involontariamente le strutture dati condivise;
- Nel driver non è possibile utilizzare le interruzioni
2.3. Verifica Dati Utente
Lo standard che assumiamo è quello di non fidarci dell’utente. Sarà quindi necessario controllare e approvare i dati che l’utente ci fornisce, in particolare il buffer dove salvare i dati, che ci è restituito attraverso un’indirizzo.
Questo intervallo di indirizzi di memoria [buf, buf + quanti), potrebbe infatti trovarsi in una sezione di memoria alla quale lui non può accedere, ma il sistema sì.
Questo problema, che ricade nei problemi degli indirizzi cavalli di Troia, richiede quindi un’estrema attenzione e un’attenta validazione dei dati.
Per risolverlo dovremo quindi verificare:
- Che l’indirizzo sia normalizzato;
- Che l’indirizzo sia mappato nel trie del processo;
- Nel caso di scritture di buffer, che si abbia accesso in scrittura a quest’ultimo
- Che
buf + inon faccia wrap-around, con $0 \le i < quanti$ - Che
[buf, buf+quanti)stia tutto nella stessa porzione di memoria
Questi controlli, tediosi ma generalmente semplici, sono affetti da un’ulteriore complicazione: il driver gira infatti mentre in esecuzione c’è P2 e non P1.
L’indirizzo privato fornitoci da P1, senza apporre le giuste precauzioni, verrebbe utilizzato nel contesto di P2, sovrascrivendone la memoria privata.
La soluzione più semplice, che è anche quella che generalmente adoperiamo, è quella di imporre la necessità che il buffer stia tutto nella parte condivisa, così da non scrivere nelle parti private di altri processi. (nell’implementazione è sufficiente che sia dichiarato come variabile globale o nello heap)
Per effettuare tutti questi controlli, nel nostro sistema è fornita una funzione access(), la cui parte cpp è la seguente:
extern "C" bool c_access(vaddr begin, natq dim, bool writeable, bool shared = true) {
esecuzione->contesto[I_RAX] = false;
if (!tab_iter::valid_interval(begin, dim))
return false;
if (shared && (!in_utn_c(begin) || (dim > 0 && !in_utn_c(begin + dim - 1))))
return false;
// usiamo un tab_iter per percorrere tutto il sottoalbero relativo
// alla traduzione degli indirizzi nell'intervallo [begin, begin+dim).
for (tab_iter it(esecuzione->cr3, begin, dim); it; it.next()) {
tab_entry e = it.get_e();
// interrompiamo il ciclo non appena troviamo qualcosa che non va
if (!(e & BIT_P) || !(e & BIT_US) || (writeable && !(e & BIT_RW)))
return false;
}
esecuzione->contesto[I_RAX] = true;
return true;
}
La funzione c_read_n avrà quindi il seguente controllo:
if(!c_access(begin, quanti, true, true)){
flog(LOG_WARN, "buffer non valido!");
abort_p();
}
Notiamo che utilizziamo abort_p e non c_abort_p perché questa sezione si trova in c_read_n che non ha effettuato né salva_stato né carica_stato.
3. Modulo I/O
La gestione con il meccanismo dei driver che abbiamo visto, per quanto funzionante, è però poco flessibile ed efficiente per due motivi:
- Il driver deve essere eseguito con interruzioni disabilitate, in quanto manipola direttamente le code processi
- Il driver non si può bloccare, in quanto non è un processo
Il primo punto può causare problemi, in quanto costringe anche le interruzioni a priorità maggiore ad aspettare l’esecuzione prima di poter agire.
Per risolvere invece il secondo punto “trasformiamo” il driver in un processo in un nuovo modulo, chiamato modulo I/O.
Il modulo I/O è un modulo indipendente, così come sistema e utente.
Come utente, anch’egli può affidarsi sulle funzioni di sistema, come se fosse un’altra via per accedervi.
Più precisamente, facciamo in modo che l’interruzione non mandi in esecuzione l’intero driver, ma solo un piccolo handler che ha come scopo mandare in esecuzione il processo, chiamato processo esterno, che si preoccuperà di svolgere le istruzioni che prima erano svolte dal driver.
Quest’ultimo si troverà quindi nel nuovo modulo I/O.
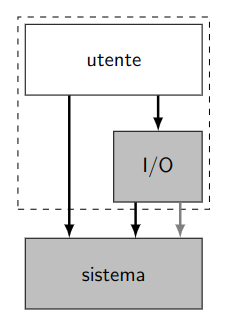
I moduli utente e I/O permettono la non atomicità, che invece è obbligatoria nel modulo sistema.
L’utente ha acesso alle primitive di sistema sia alle nuove primitive realizzate in I/O, accessibili sempre tramite INT.
Tramite questa soluzione risolviamo anche il problema delle interruzioni disabilitate, poiché, essendo adesso un processo come gli altri, basterà disattivarle utilizzando cli e sti solo nei punti dove si accede effettivamente alle strutture dati condivise.
Questa soluzione, per quanto utilizzata in sistemi reali, comporta grandi complicazione nella scrittura del codice.
Possiamo invece adottare una soluzione molto più semplice:
Separando i due moduli (
sistemaeI/O) siamo in grado di intercettare errori involontari, come chiamate interne asalva/carica_statoo l’accesso a code processi, poiché sono dichiarate in un’altro modulo che il collegatore non associa.
Nella nostra implementazione, i file che contengono il codice di questo modulo si trovano nella cartella io/ e sono io.cpp e io.s.
Una volta compilati e collegati produrranno il file build/io che verrà caricato in memoria durante l’avvio del sistema e mappato nello spazio di indirizzamento di ogni processo, nella sezione IO/condivisa.
Idealmente vorremmo che il codice contenuto in questo nuovo modulo girasse ad un livello intermedio tra LIV_UTENTE e LIV_SISTEMA in quanto:
- Deve avere più diritti degli utenti, come il poter agire con le periferiche di io
- Non deve poter accedere direttamente alle strutture dati del sistema, come code processi, tabelle di paginazione,
IDT,GDT, …
Il secondo punto si raggiunge già in parte compilando come modulo separato I/O, tuttavia non è una protezione completa.
Non avendo però a disposizione questo livello ideale siamo costretti a scenglierne uno tra i due che abbiamo a disposizione. I/O gira quindi a LIV_SISTEMA.
Questa scelta deriva da tutta una serie di motivi, in particolare:
- Nell’architettura come l’abbiamo pensata fino a questo punto, non riusciremmo a distinguere
utenteeI/Onella gestione delle periferiche io se fossero allo stesso livello. Infatti chi ha il permesso di poter utilizzare i comandi di io è scritto inRFLAGS, e fa riferimento al livello minimo necessario. - Nei processori iItel vi è un’associazione tra
INeOUTai comandiCLIeSTI. Se ponessimo ilLIV_UTENTE, forniremmo l’accesso all’utenteanche a queste istruzioni, cosa che abbiamo già visto non va fatta.
Pur avendo LIV_SISTEMA, il modulo girerà a interruzioni abilitate così come il codice del modulo utente. Questo vale sia per il codice dei processi esterni sia per il codice delle nuove primitive interne.
Eventuali problemi di mutua esclusione dovranno quindi essere risolti utilizzando i semafori del sistema.
In I/O e in sistema devono essere inoltre caricate ulteriori primitive aggiuntive, dedicate esclusivamente a I/O, salvate nella tabella IDT con il bit DPL = LIV_SISTEMA.
Una delle primitive riservate al modulo I/O è la primitiva activate_pe(), che serve ad attivare un processo esterno.
Questa primitiva ha gli stessi parametri della normale activate_p(), con l’aggiunta di un’ulteriore parametro irq corrispondente al numero del piedino dell’APIC da cui arriveranno le richieste al quale il processo dovrà rispondere.
In particolare I/O ha una tabella a_p con un entrata per ogni piedino dell’APIC (24 piedini $\to$ 24 entrate).
La activate_pe(), dopo aver attivato un processo, inserirà il corrispondente des_proc nell’entrata opportuna di a_p invece che inserirlo in pronti.
Per gestire le possibili interruzioni il sistema deve quindi predisporre un handler che si preoccupa di mettere in esecuzione il processo esterno corrispondente, recuperando il des_proc da a_p.
L’handler tuttavia non recupera alcun parametro per capire chi è la sorgente dell’interruzione.
Per poterlo fare, ipotizzando che i sia uno dei piedini dell’APIC, dovranno quindi esistere tanti handler quanti sono i piedini.
Ogni handler_i metterà in esecuzione il processo in a_p[i].
L’handler avrà quindi una forma standard:
handler_i:
; Salvo lo stato del processo che stava girando
CALL salva_stato
; Lo inserisco in cima alla coda pronti
; Essendo quello attualmente in esecuzione avrà
; sicuramente la priorità più alta degli altri
CALL inspronti
; Equivalente di esecuzione = a_p[i]
MOVq a_p+i*8, %rax
MOVq %rax, esecuzione
; Cedo il controllo al processo esterno, (sotto)
CALL carica_stato
IRETQ
Sottolineiamo che alla loro creazione questi handler non sono associati a nessuna entrata della IDT.
Questo accade perché l’entrata della IDT, ovvero il suo tipo, determina anche la priorità che l’APIC assegna alla richiesta di interruzione.
Inoltre daremo ai processi esterni una priorità maggiore rispetto ai processi interni, per emulare il comportamento dei driver.
Vogliamo però fare in modo che questa priorità sia consistente con la precedenza del corrispondente processo esterno, come assegnata dalla activate_pe().
La soluzione che adottiamo prevede quindi che tale precedenza debba avere la forma: MIN_EXT_PRIO + prio dove:
MIN_EXT_PRIOè una costante definita incostanti.hche stabilisce la massima priorita per i processiutenteprioè un numero naturale minore di256.
La activate_pe() perciò:
- Programmerà l’
APICin modo che il piedinoirqinvii il tipoprio - Installerà un gate che punti a
handler_inell’entratapriodellaIDT.
extern "C" void c_activate_pe(void f(natq), natq a, natl prio, natl liv, natb irq) {
des_proc* p; // des_proc per il nuovo processo
natw tipo; // entrata nella IDT
esecuzione->contesto[I_RAX] = 0xFFFFFFFF;
if (prio < MIN_EXT_PRIO || prio > MAX_EXT_PRIO) {
flog(LOG_WARN, "activate_pe: priorita' non valida: %u", prio);
return;
}
// controlliamo che 'liv' contenga un valore ammesso
// [segnalazione di F. De Lucchini]
if (liv != LIV_UTENTE && liv != LIV_SISTEMA) {
flog(LOG_WARN, "activate_pe: livello non valido: %u", liv);
return;
}
// controlliamo che 'irq' sia valido prima di usarlo per indicizzare 'a_p'
if (irq >= apic::MAX_IRQ) {
flog(LOG_WARN, "activate_pe: irq %hhu non valido (max %u)", irq, apic::MAX_IRQ);
return;
}
// se a_p è non-nullo, l'irq è già gestito da un altro processo
// esterno o da un driver
if (a_p[irq]) {
flog(LOG_WARN, "activate_pe: irq %hhu occupato", irq);
return;
}
// anche il tipo non deve essere già usato da qualcos'altro.
// Controlliamo quindi che il gate corrispondente non sia marcato
// come presente (bit P==1)
tipo = prio - MIN_EXT_PRIO;
if (gate_present(tipo)) {
flog(LOG_WARN, "activate_pe: tipo %hx occupato", tipo);
return;
}
p = crea_processo(f, a, prio, liv);
if (p == 0)
return;
// Creiamo il collegamento irq->tipo->handler->processo esterno
// irq->tipo (tramite l'APIC)
apic::set_VECT(irq, tipo);
// Associazione tipo->handler (tramite la IDT)
// Nota: in sistema.s abbiamo creato un handler diverso per ogni possibile irq.
// L'irq che passiamo a load_handler serve ad identificare l'handler che ci serve.
load_handler(tipo, irq);
// Associazione handler->processo esterno (tramite 'a_p')
a_p[irq] = p;
// Ora che tutti i collegamenti sono stati creati possiamo iniziare a ricevere
// interruzioni da irq.
// Smascheriamo dunque le richieste irq nell'APIC
apic::set_MIRQ(irq, false);
flog(LOG_INFO, "estern=%u entry=%p(%lu) prio=%u (tipo=%2x) liv=%u irq=%hhu",
p->id, f, a, prio, tipo, liv, irq);
esecuzione->contesto[I_RAX] = p->id;
return;
}
L’handler associato alla richiesta di interruzione, i processi esterni e la primitiva di sistema vera e propria avranno quindi questa forma:
sistema.s
; Primitiva di sistema wfi() (waiting_for_interrupt)
a_wfi:
; Stato del processo esterno riferito sopra
CALL salva_stato
CALL apic_send_EOI
; Non abbiamo certezza di chi riprenderà l'esecuzione
; Infatti questa porzione viene eseguita con interruzioni
; abilitate, perciò potrebbe esserci qualcun'altro diverso
; dal processo inserito con la inspronti() in cima a 'pronti'
CALL schedulatore
CALL carica_stato
RET
wfi() (wait-for-interrupt) è una primitiva del modulo-io che mette in attesa un processo e restituisce il controllo alla coda pronti.
io.s
.global wfi
wfi:
INT $TIPO_WFI
RET
io.cpp
extern "C" processo_esterno(natl i){
// Accedo al descrittore di una specifica interfaccia i
// Non è necessario validarlo poiché viene dal modulo io stesso
des_io* d = &array_des_io[i];
// Vado in attesa fino alla prossima wait_for_interrupt
// Senza mai terminare
for(;;){
// Corpo del Processo
wfi();
}
}
Un’ulteriore informazione che abbiamo in questo caso particolare è che l’handler salterà sempre (tranne alla prima chiamata) nell’istruzione successiva a wfi(). Infatti questo è garantito dalla apic_send_EOI() in a_wfi.
Questo fatto ci garantisce inoltre che due interruzioni con la stessa priorità non possano mai interrompersi vicevolmente.
È inoltre necessario che apic_send_EOI sia nel modulo sistema e non nel modulo I/O poiché quest’ultimo può accettare le interruzioni.
Quando invieremo EOI quindi potrebbe generare una nuova interruzione per un processo a priorità uguale.
Due processi a priorità uguale in realtà in maniera rocambolesca funzionano. Infatti quello che succede è questo:
extern "C" void estern_i(natl id){
//...
for(;;){
//....
send_apic_EOI();
// <--- Qui si genera l'interruzione dello stesso handler_i
wfi();
}
}
Perciò si entrerà nell’handler_i, eseguendo una salva_stato che, in particolare, salverà %rip puntando a wfi().
Inoltre il processo estern_i verrà inserito in coda pronti.
Nelle righe successive dell’handler si mette in esecuzione estern_i, che quindi sarà in contemporanea sia in coda pronti che in esecuzione.
Con la carica stato si riprenderà l’esecuzione di estren_i proprio sulla chiamata a wfi().
wfi() quindi farà la salva_stato, dove stavolta %rip punterà in cima al ciclo for e sospenderà il processo in attesa della prossima esecuzione, cosa che avrebbe dovuto fare prima.
Al termine a_wfi esegue schedulatore che reinserisce in esecuzione sempre e comunque estern_i rieseguendo carica_stato in particolare si reinserisce in %rip la cima del ciclo.
Gestendo solo adesso la seconda interruzione.
Tutto questo praticamente quindi funziona, ma fa diversi errori concettuali non banali e non ignorabili:
- Inserisce un processo i/o in coda
pronti - Porta il sistema ad avere lo stesso processo in contempornea sia in
prontiche inesecuzione.